1. 소스 코드와 명령어
명령어는 컴퓨터를 실질적으로 작동시키는 매우 중요한 정보입니다.
- 컴퓨터를 작동시키는 정보가 명령어라면,
- C, C++, Java, Python과 같은 프로그래밍 언어로 만든 소스 코드는 무엇일까요?
- 프로그래밍 언어로 만든 소스 코드, 즉 프로그램을 실행해도 컴퓨터는 잘 작동하는데 말이죠.
- 결론부터 말하면
모든 소스 코드는 컴퓨터 내부에서 명령어로 변환됩니다.
1.1 고급 언어와 저급 언어
고급 언어로 작성된 소스 코드가 실행하려면, 반드시 저급 언어(명령어)로 변환되어야 합니다.
고급 언어high-level programming language)- 개발자가 이해하기 쉽게 만든 언어
- e.g. C, C++, Java, Python
저급 언어(low-level programming language)- 컴퓨터가 이해하고 실행하는 언어
- 저급 언어에는 두 가지 종류가 있습니다. 바로
기계어와어셈블리어입니다.
1.1.1 기계어와 어셈블리어
기계어(machine code)- 0과 1의 명령어 비트로 이루어진 언어
- 기계어는 0과 1로 이루어진 명령어 모음
- 퓨터는 0과 1로 이루어진 이 기계어를 이해하고 실행함
- 기계어를 이진수로 나열하면 너무 길어지기 때문에 가독성을 위해 아래와 같이 십육진수로 표현하기도 함
어셈블리어(assembly language)- 기계어는 오로지 컴퓨터만을 위해 만들어진 언어이기 때문에 사람이 읽으면 그 의미를 이해하기 어려움
- 그래서 등장한 저급 언어가 어셈블리어
- 0과 1로 표현된 명령어(기계어)를 읽기 편한 형태로 번역한 언어가 어셈블리어
다음은 어셈블리어 예시입니다.
1push rbp2mov rbp, rsp3mov DWORD PTR [rbp-4], 14mov DWORD PTR [rbp-8], 25mov edx, DWORD PTR [rbp-4]6mov eax, DWORD PTR [rbp-8]7add eax, edx8mov DWORD PTR [rbp-12], eax9mov eax, 010pop rbp11ret
위 어셈블리어 한 줄 한 줄이 무엇을 의미하는지 몰라도 괜찮습니다. 다만, 위 어셈블리어 한 줄 한 줄이 명령어라는 사실만 기억해 주세요.
1.1.2 고급언어
프로그래밍 언어를 배워봤다면, 어셈블리어는 C, C++, Java, Python과는 사뭇 다르게 생겼다는 사실을 아실 겁니다.
어셈블리어는 0과 1로 이루어진 기계어를 읽기 편하게 만든 저급 언어일 뿐이므로,
개발자가 어셈블리어를 이용해 복잡한 프로그램을 만들기란 쉽지 않습니다.
그래서 고급 언어가 필요합니다.
- 고급 언어는 사람이 읽고 쓰기 편한 것은 물론이고,
- 더 나은 가독성, 변수나 함수 같은 편리한 문법을 제공하기 때문에 어떤 복잡한 프로그램도 구현할 수 있습니다.
그러면 왜 저급 언어를 알아야 할까요?
- 개발자들이 고급 언어로 소스 코드를 작성하면 알아서 저급 언어로 변환되어 잘 실행되는데,
- “일부러 저급 언어로 개발할 일은 없지 않나요?”라는 생각을 할 수 있습니다.
이는 반만 맞는 말입니다. 정확히는 여러분이 어떤 개발자가 되길 희망하는지에 따라 저급 언어의 중요성이 달라집니다. 물론, 어셈블리어를 작성하거나 관찰할 일이 거의 없는 개발자도 있습니다. 하지만 하드웨어와 밀접한 프로그램을 개발하는 임베디드 개발자, 게임 개발자, 정보 보안 분야 등의 개발자는 어셈블리어를 많이 이용합니다.
소스 코드에 어셈블리어가 사용된 예시
1#include <linux/module.h>2#include <linux/io.h>3void __raw_readsl(const void __iomem *addr, void *datap, int len)4{5u32 *data;6for (data = datap; (len != 0) && (((u32)data & 0x1f) != 0); len- -)7*data++ = __raw_readl(addr);8if (likely(len >= (0x20 >> 2))) {9int tmp2, tmp3, tmp4, tmp5, tmp6;10__asm__ __volatile__(11"1: \n\t"12"mov.l @%7, r0 \n\t"13"mov.l @%7, %2 \n\t"14#ifdef CONFIG_CPU_SH415"movca.l r0, @%0 \n\t"16#else17"mov.l r0, @%0 \n\t"18#endif19"mov.l @%7, %3 \n\t"20"mov.l @%7, %4 \n\t"21"mov.l @%7, %5 \n\t"22"mov.l @%7, %6 \n\t"23"mov.l @%7, r7 \n\t"24"mov.l @%7, r0 \n\t"25"mov.l %2, @(0x04,%0) \n\t"26"mov #0x20>>2, %2 \n\t"27"mov.l %3, @(0x08,%0) \n\t"28"sub %2, %1 \n\t"29"mov.l %4, @(0x0c,%0) \n\t"30"cmp/hi %1, %2 ! T if 32 > len \n\t"31"mov.l %5, @(0x10,%0) \n\t"32"mov.l %6, @(0x14,%0) \n\t"33"mov.l r7, @(0x18,%0) \n\t"34"mov.l r0, @(0x1c,%0) \n\t"35"bf.s 1b \n\t"36" add #0x20, %0 \n\t"37: "=&r" (data), "=&r" (len),38"=&r" (tmp2), "=&r" (tmp3), "=&r" (tmp4),39"=&r" (tmp5), "=&r" (tmp6)40: "r"(addr), "0" (data), "1" (len)41: "r0", "r7", "t", "memory");42}43}
그리고 이러한 분야의 개발자들에게 어셈블리어란 ‘작성의 대상’일 뿐만 아니라 매우 중요한 ‘관찰의 대상’이기도 합니다.
- 어셈블리어를 읽으면, 컴퓨터가 프로그램을 어떤 과정으로 실행하는지,
- 즉, 프로그램이 어떤 절차로 작동하는지를 가장 근본적인 단계에서부터 추적하고 관찰할 수 있기 때문입니다.
- 어떤 개발자가 되길 희망하는지에 따라 저급 언어의 중요성이 달라집니다.
- 개발 분야를 막론하고, 고급 언어와 저급 언어의 차이를 이해하는 것은 매우 좋은 교양입니다.
1.2 컴파일 언어와 인터프리터 언어
개발자들이 고급 언어로 작성한 소스 코드는 결국 저급 언어로 변환되어 실행된다고 했는데,
- 그렇다면 고급 언어는 어떻게 저급 언어로 변환될까요?
- 여기에는 크게 두 가지, 컴파일방식과 인터프리트 방식이 있습니다.
컴파일 언어 | 인터프리터 언어 |
|---|---|
| 컴파일 방식으로 작동하는 프로그래밍 언어 | 인터프리트 방식으로 작동하는 프로그래밍 언어 |
1.2.1 컴파일 언어
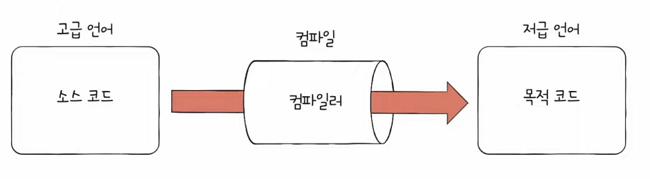
컴파일 언어: 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급 언어- e.g. 대표적인 컴파일 언어가 C언어
- 컴파일 언어로 작성된 소스 코드는 코드 전체가 저급 언어로 변환되는 과정을 거칩니다.
- 이 과정을
컴파일(compile)이라고 합니다.
- 이 과정을
- 컴파일을 수행해 주는 도구를
컴파일러(compiler)- 컴파일러는 개발자가 작성한 소스 코드 전체를 쭉 훑어보며
- 소스 코드에 문법적인 오류는 없는지, 실행 가능한 코드인지, 실행하는데 불필요한 코드는 없는지 등을 따지며
- 소스 코드를 처음 부터 끝까지 저급 언어로 컴파일힘
- 이때 컴파일러가 소스 코드 내에서 오류를 하나라도 발견되면, 해당 소스 코드는 컴파일에 실패
- 컴파일이 성공적으로 수행되면, 개발자가 작성한 소스 코드는 컴퓨터가 이해할 수 있는 저급 언어로 변환
- 이렇게 컴파일러를 통해 저급 언어로 변환된 코드를
목적 코드(object code)라고 합니다.
1.2.2 인터프리터 언어
인터프리터 언어: 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어입니다.- e.g. 대표적인 인터프리터 언어로 Python
- 소스 코드를 한 줄씩 저급 언어로 변환하여 실행해 주는 도구를
인터프리터(interpreter) - 인터프리터 언어는 컴퓨터와 대화하듯 소스 코드를 한 줄씩 실행하기 때문에
- 소스 코드 전체를 저급 언어로 변환하는 시간을 기다릴 필요가 없음
- 소스 코드를 한 줄씩 실행하기 때문에,
- 소스 코드 N번째 줄에 문법 오류가 있더라도 N-1번째 줄까지는 올바르게 수행
- 인터프리터 언어가 컴파일 언어보다 빠르다고 생각할 수도 있지만,
- 일반적으로 인터프리터 언어는 컴파일 언어보다 느림
- 컴파일을 통해 나온 결과물, 즉 목적 코드는 컴퓨터가 이해하고 실행할 수 있는 저급 언어인 반면,
- 인터프리터 언어는 소스 코드 마지막에 이를 때까지 한 줄 한 줄씩 저급 언어로 해석하며 실행해야 하기 때문
💡 컴파일 언어와 인터프리터 언어, 칼로 자르듯이 구분될까?
컴파일 언어와 인터프리터 언어는 칼로 자르듯이 명확하게 구분할 수 있는 개념일까요?
- C, C++과 같이 명확하게 구분할 수 있는 언어도 있으나,
- 현대의 많은 프로그래밍 언어 중에는 컴파일 언어와 인터프리터 언어 간의 경계가 모호한 경우가 많습니다.
- 가령 대표적인 인터프리터 언어로 알려진 Python도 컴파일을 하지 않는 것은 아니며,
- Java의 경우 저급 언어가 되는 과정에서 컴파일과 인터프리트를 동시에 수행합니다.
즉, 하나의 프로그래밍 언어가 반드시 둘 중 하나의 방식만으로 작동한다고 생각하는 것은 오개념입니다.
- 컴파일이 가능한 언어라고 해서 인터프리트가 불가능하거나,
- 인터프리트가 가능한 언어라고 해서 컴파일이 불가능한 것은 아닙니다.
따라서 모든 프로그래밍 언어를 컴파일 언어와 인터프리터 언어로 칼로 자르듯 구분하기보다는 ‘고급 언어가 저급 언어로 변환되는 대표적인 방법에는 컴파일 방식과 인터프리트 방식이 있다’ 정도로만 이해하는 것이 좋습니다.
Compiler Explorer : 컴파일 & 인터프리트 과정 알아보기
2. 명령어의 구조
여러분들은 누군가에게 명령할 때 어떻게 말하나요? 보통 아래와 같이 말할 겁니다.
“학생들, 다음 주까지 과제를 제출하세요.” “영수야, 방 좀 치워 줘!” “멍멍아, 이거 물어와!”
컴퓨터 속 명령어도 마찬가지입니다. 명령어는 아래 그림처럼 ‘무엇을 대상으로, 어떤 작동을 수행하라’는 구조로 되어 있습니다.
2.1 연산 코드와 오퍼랜드

색 배경 필드는 명령의 ‘작동’, 달리 말해 ‘연산’을 담고 있고,흰색 배경 필드는 ‘연산에 사용할 데이터’ 또는 ‘연산에 사용할 데이터가 저장된 위치’를 담고 있습니다.

명령어는 연산 코드와 오퍼랜드로 구성되어 있습니다.
연산 코드(operation code) 필드: 명령어가 수행할 연산연산자라고도 부름
오퍼랜드(operand) 필드: 연산에 사용할 데이터 or 연산에 사용할 데이터가 저장된 위치피연산자라고도 부름
1push rbp2mov rbp, rsp3mov DWORD PTR [rbp-4], 14mov DWORD PTR [rbp-8], 25mov edx, DWORD PTR [rbp-4]6mov eax, DWORD PTR [rbp-8]7add eax, edx8mov DWORD PTR [rbp-12], eax9mov eax, 010pop rbp11ret
기계어와 어셈블리어 또한 명령어이기 때문에 연산 코드와 오퍼랜드로 구성되어 있습니다. 앞에서 살펴본 어셈블리어 예시를 다시 볼까요?
- push, mov, add, pop 같은 것들은
연산 코드, - rbp, rsp 등 뒤에 있는 것들은
오퍼랜드입니다.
2.1.1 오퍼랜드
오퍼랜드(operand) 필드: 연산에 사용할 데이터 or 연산에 사용할 데이터가 저장된 위치
피연산자라고도 부름- 숫자와 문자 등을 나타내는
데이터또는 메모리나 레지스터주소가 저장될 수 있습니다만, 오퍼랜드 필드에는 주로 데이터가 저장된 위치, 즉 메모리 주소나 레지스터 이름이 담깁니다.- 그래서
오퍼랜드 필드를주소 필드라고 부르기도 합니다.
오퍼랜드는 명령어 안에 하나도 없을 수도 있고, 한 개만 있을 수도 있고, 두 개 또는 세 개 등 여러 개가 있을 수도 있습니다.
1mov eax, 0 ; -> 오퍼랜드가 2개인 경우2pop rgb ; -> 오퍼랜드가 1개인 경우3ret ; -> 오퍼랜드가 없는 경우
0-주소 명령어: 오퍼랜드가 하나도 없는 명령어1-주소 명령어: 오퍼랜드가 하나인 명령어2-주소 명령어: 오퍼랜드가 두 개인 명령어3-주소 명령어: 오퍼랜드가 세 개인 명령어
2.1.2 연산코드
연산 코드(operation code) 필드: 명령어가 수행할 연산
연산 코드 종류는 매우 많지만, 가장 기본적인 연산 코드 유형은 크게 네 가지로 나눌 수 있습니다.
- 데이터 전송
- 산술/논리 연산
- 제어 흐름 변경
- 입출력 제어
이 네 가지 유형 각각에 해당하는 대표적인 연산 코드를 알아봅시다. 그렇다고 이 내용들을 다 외우라는 것은 아닙니다. 명령어의 종류와 생김새는 CPU마다 다르기 때문에 연산 코드의 종류와 생김새 또한 CPU마다 다릅니다. 지금부터 설명할 내용은 대부분의 CPU가 공통으로 이해하는 대표적인 연산 코드의 종류 정도로만 이해해도 무방합니다.
(1) 데이터 전송
MOVE: 데이터를 옮겨라STORE: 메모리에 저장하라LOAD(FETCH): 메모리에서 CPU로 데이터를 가져와라PUSH: 스택에 데이터를 저장하라POP: 스택의 최상단 데이터를 가져와라
(2) 산술/논리 연산
ADD / SUBTRACT / MULTIPLY / DIVIDE: 덧셈 / 뺄셈 / 곱셈 / 나눗셈을 수행하라INCREMENT / DECREMENT: 오퍼랜드에 1을 더하라 / 오퍼랜드에 1을 빼라AND / OR / NOT: AND / OR / NOT 연산을 수행하라COMPARE: 두 개의 숫자 또는 TRUE / FALSE 값을 비교하라
(3) 제어 흐름 변경
JUMP: 특정 주소로 실행 순서를 옮겨라CONDITIONAL JUMP: 조건에 부합할 때 특정 주소로 실행 순서를 옮겨라HALT: 프로그램의 실행을 멈춰라CALL: 되돌아올 주소를 저장한 채 특정 주소로 실행 순서를 옮겨라RETURN: CALL을 호출할 때 저장했던 주소로 돌아가라
CALL과 RETURN은 함수를 호출하고 리턴하는 명령어 입니다
(4) 입출력 제어
READ(INPUT): 특정 입출력 장치로부터 데이터를 읽어라WRITE(OUTPUT): 특정 입출력 장치로 데이터를 써라START IO: 입출력 장치를 시작하라TEST IO: 입출력 장치의 상태를 확인하라
2.2 주소 지정 방식
2.2.1 주소를 담는 이유
그런데 이런 의문이 들 수 있습니다.
“왜 오퍼랜드 필드에 메모리나 레지스터 주소를 담을까?” “그냥 데이터만 넣어놓으면 되지 않나?”
이는 명령어 내에서 표현할 수 있는 데이터 크기가 제한되기 때문입니다.
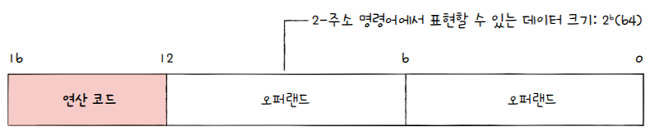
예를 들어, 명령어의 크기가 16비트이고, 연산 코드 필드가 4비트인 2-주소 명령어에서는
- 오퍼랜드 필드당 6비트 정도밖에 남지 않습니다.
- 즉, 하나의 오퍼랜드 필드로 표현할 수 있는 정보의 개수는 개밖에 되지 않습니다

여기다 오퍼랜드의 수가 많아지면 더 줄어듭니다. 명령어의 크기가 16비트, 연산 코드 필드가 4비트인 3-주소 명령어에서는
- 오퍼랜드 필드당 4비트 정도밖에 남지 않습니다.
- 이 경우 하나의 오퍼랜드 필드로 표현할 수 있는 정보의 개수는 개밖에 없겠죠
2.2.2 주소 지정 방식
하지만 만약 오퍼랜드 필드 안에 메모리 주소가 담긴다면 표현할 수 있는 데이터의 크기는 하나의 메모리 주소에 저장할 수 있는 공간만큼 커집니다.
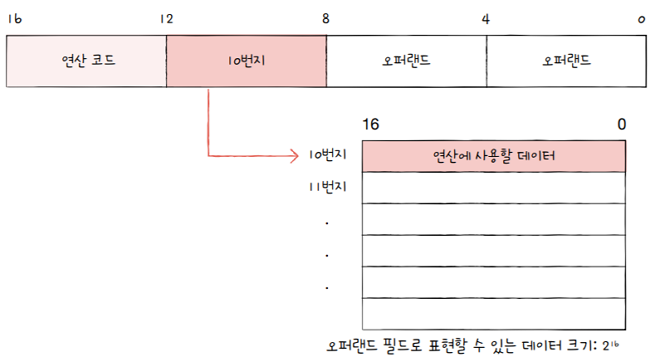
예를 들어, 한 주소에 16비트를 저장할 수 있는 메모리가 있다고 가정해 봅시다.
- 이 메모리 안에 데이터를 저장하고,
- 오퍼랜드 필드 안에 해당 메모리 주소를 명시한다면 표현할 수 있는 정보의 가짓수가 으로 확 커지죠?
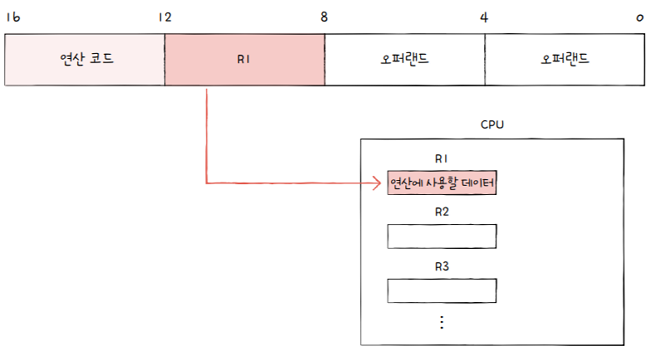
오퍼랜드 필드에 메모리 주소가 아닌 레지스터 이름을 명시할 때도 마찬가지입니다.
- 이 경우 표현할 수 있는 정보의 개수는 해당 레지스터가 저장할 수 있는 공간만큼 커집니다.
2.2.3 유효 주소
유효 주소(effective address)- 연산 코드에 사용할 데이터가 저장된 위치
- 즉, 연산의 대상이 되는 데이터가 저장된 위치
- e..g.
- 위 섹션의 첫 번쨰 그림의 경우
유효 주소는 10번지, - 우 섹션의 두 번째 그림의 경우
유효 주소는 레지스터 R1이 되겠죠.
- 위 섹션의 첫 번쨰 그림의 경우
명령어 주소 지정 방식(addressing modes)- 연산에 사용할 데이터 위치를 찾는 방법
- 유효 주소를 찾는 방법
- 다양한 명령어 주소 지정 방식들이 존재
2.3 주소 지정 방식 종류
현대 CPU는 다양한 주소 지정 방식을 사용합니다. 대표적인 주소 지정 방식 다섯 가지를 하나씩 살펴보겠습니다.
2.3.1 즉시 주소 지정 방식

즉시 주소 지정 방식(immediate addressing mode)
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식
- 가장 간단한 형태의 주소 지정 방식
- 데이터의 크기가 작아질 수 있지만,
- 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는 과정이 없기 때문에 빠름
2.3.2 직접 주소 지정 방식
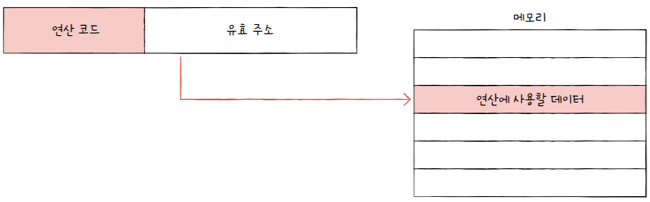
직접 주소 지정 방식(direct addressing mode)
- 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식
- 유효 주소를 표현할 수 있는 범위가 연산 코드의 비트 수만큼 줄어듦
- 표현할 수 있는 오퍼랜드 필드의 길이가 연산 코드의 길이만큼 짧아져 표현할 수 있는 유효 주소에 제한이 생김
2.3.3 간접 주소 지정 방식
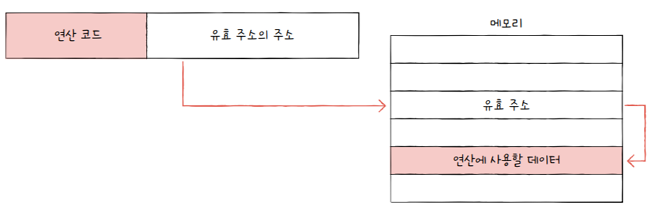
간접 주소 지정 방식(indirect addressing mode)
- 유효 주소의 주소를 오퍼랜드 필드에 명시
- 직접 주소 지정 방식보다 표현할 수 있는 유효 주소의 범위가 더 넓어졌지만,
- 두 번의 메모리 접근이 필요하기 때문에 앞서 설명한 주소 지정 방식들보다 일반적으로 느림
2.3.4 레지스터 주소 지정 방식
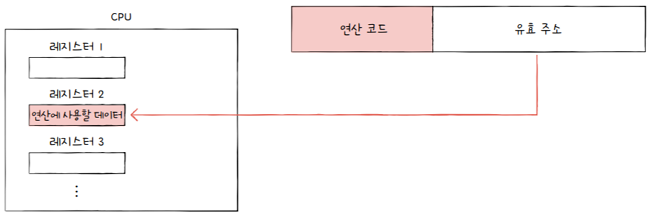
레지스터 주소 지정 방식register addressing mode
- 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방법
- 일반적으로 CPU 외부에 있는 메모리에 접근하는 것보다 CPU 내부에 있는 레지스터에 접근하는 것이 더 빠름
- 그러므로 레지스터 주소 지정 방식은 직접 주소 지정 방식보다 빠르게 데이터에 접근
- 다만, 레지스터 주소 지정 방식은 직접 주소 지정 방식과 비슷한 문제를 공유합니다.
- 표현할 수 있는 레지스터 크기에 제한이 생길 수 있다는 점
2.3.5 레지스터 간접 주소 지정 방식
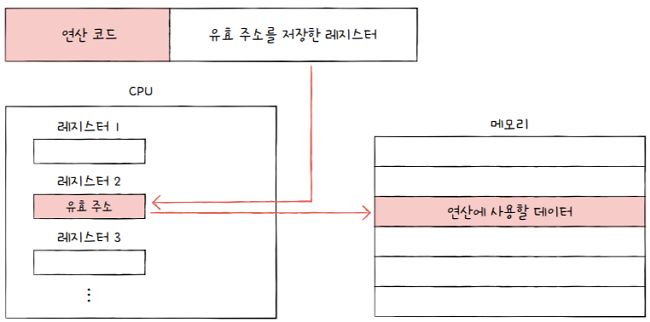
레지스터 간접 주소 지정 방식(register indirect addressing mode)
- 연산에 사용할 데이터를 메모리에 저장하고,
- 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법
- 유효 주소를 찾는 과정이
간접 주소 지정 방식과 비슷하지만, - 메모리에 접근하는 횟수가 한 번으로 줄어든다는 차이이자 장점이 있습니다.
- 메모리에 접근하는 것이 레지스터에 접근하는 것보다 더 느리다고 했었죠?
- 그래서
레지스터 간접 주소 지정 방식은간접 주소 지정 방식보다 빠릅니다.
💡 정리
연산에 사용할 데이터를 찾는 방법을
주소 지정 방식이라고 했습니다. 연산에 사용할 데이터가 저장된 위치를유효 주소이라 합니다. 대표적인 주소 지정 방식으로 아래의 5가지 방식이 있습니다.
즉시 주소 지정 방식: 연산에 사용할 데이터직접 주소 지정 방식: 유효 주소(메모리 주소)간접 주소 지정 방식: 유효 주소의 주소레지스터 주소 지정 방식: 유효 주소(레지스터 이름)레지스터 간접 주소 지정 방식: 유효 주소를 저장한 레지스터이 밖에도 레지스터에 대해 더 공부해야만 이해할 수 있는 중요한 주소 지정 방식들이 있습니다. 이들은 04장에서 학습하겠습니다.
2.3 스택과 큐
2.3.1 스택(stack)
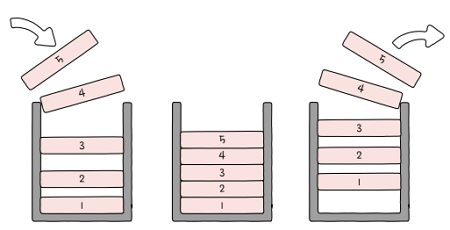
- 한쪽 끝이 막혀 있는 통과 같은 저장 공간
- ‘나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식(후입선출)’이라는 점에서
LIFO(Last In First Out)(‘리포’라고 읽습니다) 자료 구조
- e.g. 스택 안에 1 - 2 - 3 - 4 - 5 순으로 데이터를 저장하면,
- 데이터를 빼낼 때는 5 - 4 - 3 - 2 - 1 순으로 빼낼 수 있음
- 스택에 새로운 데이터를 저장하는 명령어가
PUSH, - 스택에 저장된 데이터를 꺼내는 명령어가
POP - POP 명령어를 수행하면 스택의 최상단에 있는(Last In), 마지막으로 저장한 데이터부터(First Out) 꺼내게 됩니다.
2.3.2 큐(queue)
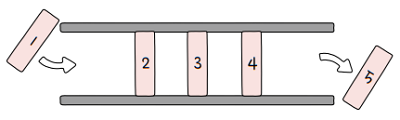
- 양쪽이 뚫려 있는 통과 같은 저장 공간
- 한쪽으로는 데이터 를 저장하고, 다른 한쪽으로는 먼저 저장한 순서대로 데이터를 빼냅니다.
- ‘가장 먼저 저장된 데 이터부터 빼내는 데이터 관리 방식(선입선출)’이라는 점에서
FIFO(First In First Out)(‘피포’라고 읽습니다) 자료 구조
3. C언어 컴파일 과정
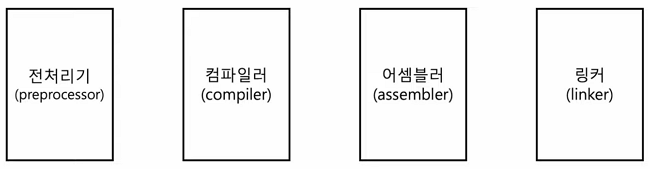
C언어는 위 그림과 같은 과정을 거쳐서 실행파일이 됩니다.
전처리기: 전처리컴파일러: 컴파일어셈블러: 어셈블링커: 링킹
3.1 전처리 과정(preprocessing)
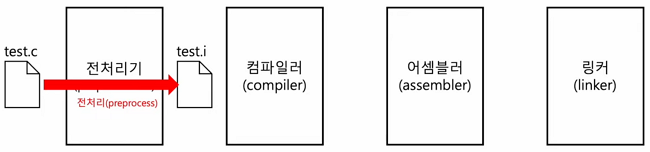
- 본격적으로 컴파일하기 전에 처리할 작업들
- 외부에 선언된 다양한 소스 코드, 라이브러리 포함 (e.g.
#include) - 프로그래밍의 편의를 위해 작성된 매크로 변환 (e.g.
#define) - 컴파일할 영역 명시 (e.g.
#if, #ifdef, ...)
3.2 컴파일 과정(compiler)
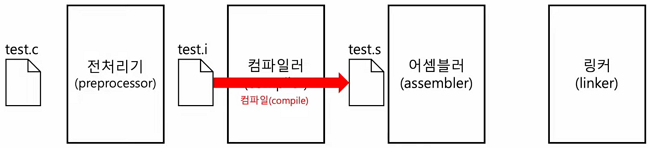
- 전처리가 완료되어도 여전히 소스코드
- **전처리 완료된 소스 코드를 저급 언어(**어셈블리 언어)로 변환
3.3 어셈블러(assembler)
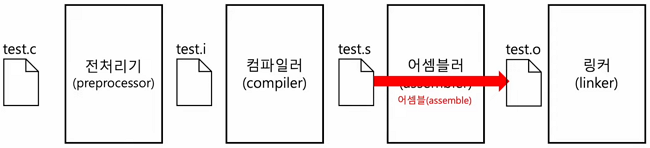
- 어셈블리어를 기계어로 변환
- 목적 코드(object file)를 포함하는 목적 파일이 됨
3.4 링커(linker)
- 목적 파일 vs 실행 파일
- 목적 파일과 실행 파일은 둘 다 기계어로 이루어진 파일
- But, 목적 파일과 실행 파일은 다르다
- 목적 파일은
링킹(linking)을 거친 이후에야 실행 파일이 된다.
3.4.1 목적 파일 vs 실행 파일
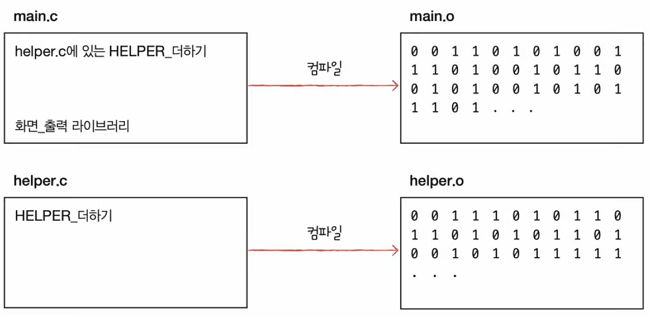
예를 들어, main.c, helper.c를 컴파일해서 목적코드로 만들었다고 합시다.
그리고 main.c는 helper.c의 내용이 꼭 필요하다고 가정해보겠습니다.
그렇다면, main.c를 컴파일하면 목적코드가 실행될까요? 안됩니다.
왜냐하면 helper.c에 있는 기능을 갖고와야 됩니다.
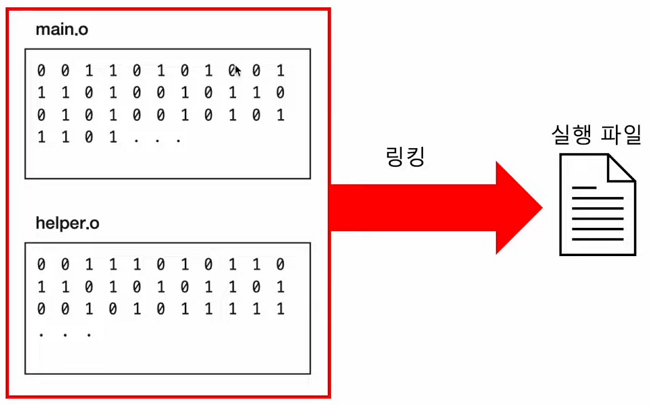
그래서 위 두 목적 코드를 연결시켜주는 작업이 링킹(linking)입니다.
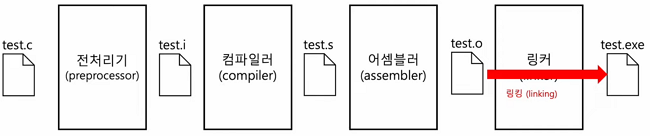
링킹까지 거치면, 마침내 사용자들이 실행할 수 있는 실행파일(exe)이 만들어 집니다.