1. DNS와 자원
클라이언트는 서버에게 요청 메시지를 보내고, 서버는 클라이언트에게 요청 메시지에 대한 응답 메시지를 보낸다.
- 이런
요청-응답 메시지 송수신 과정덕분에 브라우저에 특정 URL을 입력하면, 해당 웹 페이지를 확인할 수 있다. - 그렇다면 당연하게 서버와 클라이언트는 ‘메시지를 주고받고자 하는 대상’과 ‘송수신하고자 하는 정보’를 식별할 수 있어야 한다.
메시지를 주고받고자 하는 대상을 파악하기 위해 IP 주소 이외에 도메인 네임을 사용할 수 있다.
그리고 송수신하고자 하는 정보를 식별하기 위한 방법으로 위치 기반의 식별자인 URL과 이름 기반의 식별자인 URN이 있다.
1.1 도메인 네임과 네임 서버
앞서 네트워크 상의 어떤 호스트를 특정하기 위해 IP 주소를 사용한다고 했다.
- 하지만 오로지
IP 주소만 사용하기에는 번거롭다.- 통신하려는 모든 호스트의 IP 주소를 기억하기도 어려울 뿐더러,
- 호스트의 IP 주소는 언제든지 바뀔 수 있기 때문이다.
- e.g.
www.example,developers.naver.com,git.kernel.org같은 문자열이 도메인 네임이다.
IP 주소를 전화번호에 비유하면, 전화번호에 대응되는 사용자 이름과 같다.
사용자이름:전화번호쌍의 목록을 전화번후에 모아서 관리하는 것처럼,- 도메인 네임과 IP 주소는
네임 서버(name server)에서 관리한다.- 도메인 네임을 관리하는 네임 서버는
DNS 서버라고도 부른다.
- 도메인 네임을 관리하는 네임 서버는
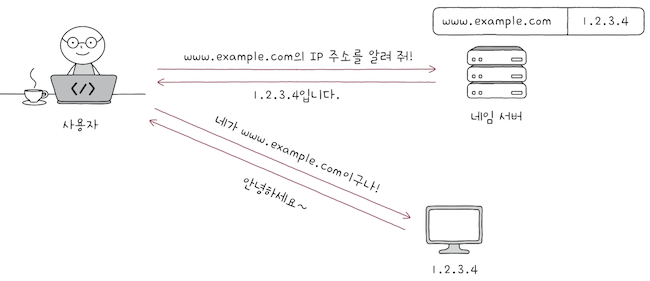
네임 서버는 호스트의 도메인 네임과 PI 주소를 모아 관리하는 ‘공용 전화번호부’와 같은 역할을 한다.
도메인 네임을네임 서버에 질의하면,- 해당 도메인 네임에 대한 IP 주소를 알려주는 방식으로
도메인 네임을 통해 IP 주소를 알아낼 수 있다. - cf. 반대로 IP 주소를 통해 도메인 네임을 알아내는 것도 가능하다.
도메인 네임은 IP 주소에 비해 기억하기 쉬울 뿐더러,
IP 주소가 바뀌더라도 바뀐IP 주소에도메인 네임을 다시 대응하면 되므로,IP 주소만으로 호스트를 특정하는 것보다 더 간편하다.
💡 개인 전화번호부와 같은 hosts 파일
앞서 네임 서버는 마치 ‘공용’ 전화번호부와 같다고 했다.
- 이와 유사하게 호스타마다 유지하는 ‘개인’ 전화번호부같은 파일도 있다.
hosts파일은 도메인 네임과 IP 주소의 대응 관계를 담은 파일로,
- 이를 토대로 도메인 네임에 대응하는 IP 주소를 식별할 수 있다.
- 호스트마다 개별적으로 보유하는 파일이므로, 마치 개인 전화번호부와 같다고 할 수 있다.
hosts파일의 위치와 내용은 운영체제마다 차이가 있으나,
- 맥OS나 리눅스의 경우
/etc/hosts에 위치하고,- 윈도우의 경우
SystemRoot/System32/drivers/etc/hosts에 위치한다.다음은 hosts 파일의 예시다.
1##2# Host Database3#4# localhost is used to configure the loopback interface5# when the system is booting. Do not change this entry.6##7127.0.0.1 localhost8255.255.255.255 broadcasthost9::1 localhost다만 이런 hosts 파일 하나만으로는
- 네트워크 세상에 있는 모든 호스트의
도메인 네임, IP 주소쌍을 전부 기억하기 어렵기에,- 공용 전화번호부인
네임 서버가 필요하다.
그렇다면 네임 서버는 어떻게 관리하면 좋을까? 그리고 몇 개가 있어야 충분할까? 이는 도메인 네임의 구조를 통해 알아볼 수 있다.
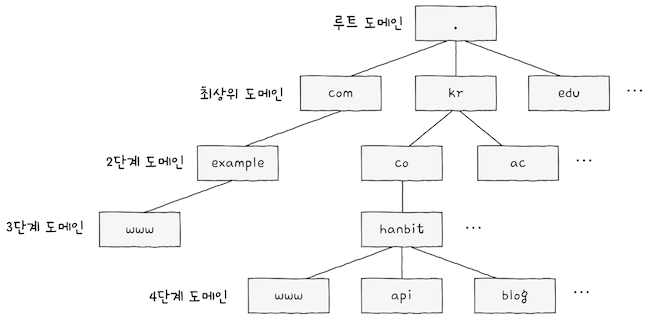
e.g. www.example.com 같은 도메인 네임이 있다고 가정해보면,
- 도메인 네임은
점(.)을 기준으로 계층적으로 구분한다. - 최상단에
루트 도메인(root domain)이 있고, 그 다음 단계인최상위 도메인(TLD; Top-Level Domain)이 있으며, - 계속 그 다음 단계의 도메인이 있는 식이다.
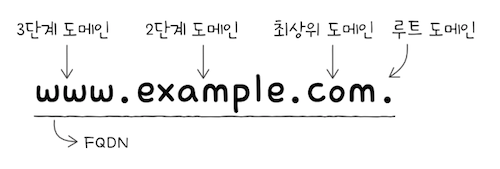
일반적으로 알고 있는 도메인 네임의 마지막 부분을 최상위 도메인, 줄여서 TLD라고 한다.
- e.g.
www.example.com의 최상위 도메인은com이다. 최상위 도메인의 종류는 다양하지만, 대표적으로 com, net, org, kr, jp, cn, us 등이 있다.- doctor, lawyer, company같은 색다른 최상위 도메인도 있다.
흔히 최상위 도메인을 마지막 네임의 마지막 부분이라 생각하기 쉽지만, 사실 루트 도메인도 도메인 네임의 일부다.
루트 도메인은점(.)으로 표현되며,도메인 네임의 마지막에 점이 찍힌 형태로 표기된다.- 일례로 웹 브라우저에
www.google.com같은도메인 네임으로 접속해도 웹사이트에 잘 접속된다. - 다만 일반적으로는
루트 도메인을 생략해서 표기하기에,- 대개
최상위 도메인을 ‘도메인의 네임의 마지막 부분’으로 간주한다.
- 대개
최상위 도메인의 하부 도메인은 2단계 도메인(second-level domain)이라 한다.
- 영어 그 자체로
세컨드 레벨 도메인이라고 부르기도 한다. - e.g.
www.example.com에서example이 2단계 도메인이다.
나아가 www.example.com에서 www는 3단계 도메인이다.
- 도메인의 단계는 이보다 더 늘어날 수도 있지만, 일반적으로 3~5단계 정도다.
- 그리고
www.example.com처럼 도메인 네임을 모두 포함하는 도메인 네임을전체 주소 도메인 네임(FQDN; Fully-Quaified Domain Name)이라 한다.
잘 생각해보면, 뒷부분이 com으로 끝나는 도메인은 아주 많다.
- 뒷부분이
example.com으로 끝나는도메인 네임도 api.example.com,mail.example.com,www.example.com등 여러개가 있을 수 있다.
하지만 FQDN의 첫 부분까지 고려한 도메인 네임은 www.example.com 하나 밖에 없다.
- 즉,
마지막 3단계 도메인까지 고려하면,www.example.com이라는 호스트를 식별할 수 있는도메인 네임을 얻을 수 있다.- 이런 점에서
FQDN의 첫 부분(www)을호스트 네임(host name)이라 부르기도 한다.
- cf.
호스트 네임이란 용어는 때로는 FQDN 자체를 가리키기도 하고,- 때로는 네트워크 상의 장치 자체 이름을 가리키기도 한다.
도메인 네임이 계층적인 형태를 띤다는 것을 배웠다.
- 바로 뒤에 설명하겠으나, 계층적인 도메인 네임을 효율적으로 관리하기 위해 네임 서버 또한 계층적인 형태를 이룬다.
- 또 네임 서버는 여러 개 존재하며, 전 세계 여러 군데에 위치해 있다.
- 이렇게 계층적이고, 분산된
도메인 네임(Domain Name)에 대한 관리 체계를도메인 네임 시스템(DNS; Domain Name System)라고 부른다.
DNS는 호스트가 이런도메인 네임 시스템을 이용할 수 있도록 하는 애플리케이션 계층 프로토콜을 의미하기도 한다.
💡서브 도메인(subdomain)이란?
서브 도메인은 다른 도메인이 포함된 도메인을 의미한다.
- e.g.
google.com의 서브 도메인이다. 모두google.com을 포함하고 있기 때문이다.
main.google.comwww.google.comscholar.google.comdrive.google.com- 마찬가지로
google.com은com을 포함하고 있기에,com의 서브 도메인이라 할 수 있다.
1.2 계층적 네임 서버
이제 계층적인 네임 서버들의 구성을 알아보고, 그 구성을 토대로 도메인 이름을 통해 IP 주소르 알아내는 과정을 살펴본다.
- ‘IP 주소를 모르는 상태에서 도메인 네임에 대응되는 IP 주소를 알아내는 과정’을
- 흔히 ‘도메인 네임을
풀이(resolve)한다’라고 표현하며, 영어로리졸빙(resolve+ing)한다라고도 표현한다.
- 흔히 ‘도메인 네임을
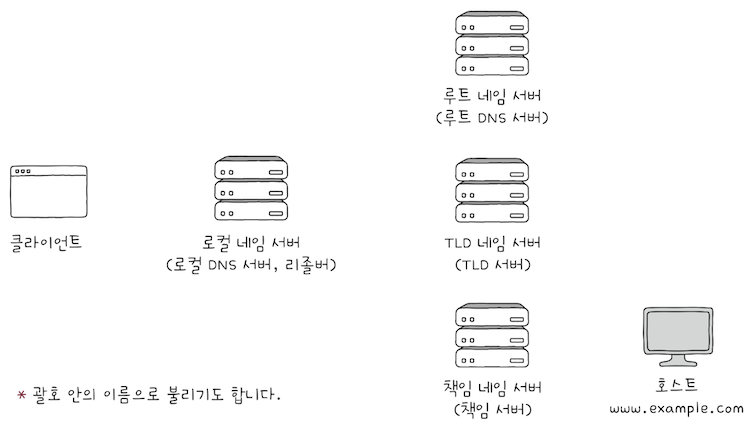
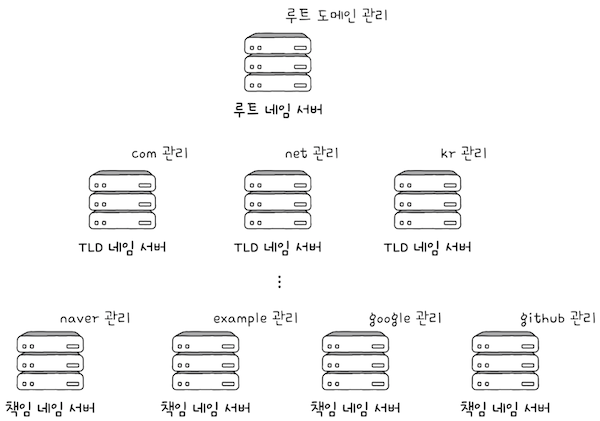
이 과정에서 다양한 네임 서버들이 사용되는데, 중요한 역할을 담당하는 네임 서버의 유형은 크게 4가지가 있다.
로컬 네임 서버,루트 네임 서버,TLD(최상위 도메인) 네임 서버,책임 네임 서버- 처음 나온 용어지만, 모든 용어를 암기할 필요는 없다.
- 용어보다 중요한 것은 각
네임 서버의 역할을 이해하는 것이다.
(1) 로컬 네임 서버(local name server)는 클라이언트와 맞닿아 있는 네임 서버로,
- 클라이언트가 도메인 네임을 통해 IP 주소를 알아내고자 할 떄, 가장 먼저 찾게 되는 네임 서버다.
- 클라이언트가 로컬 네임 서버를 찾을 수 있으려면, 로컬 네임 서버의 주소를 알고 있어야 겠죠.
- 로컬 네임 서버의 주소는 일반적으로 ISP에서 할당해주는 경우가 많다.
- 다만 ISP에서 할당해주는
로컬 네임 서버주소가 아닌공개 DNS 서버를 이용할 수도 있다.
(2) 공개 DNS 서버(public DNS Server)
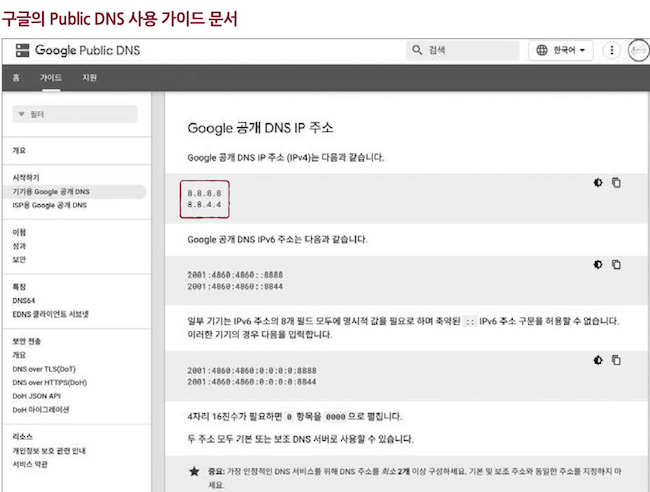
- 공개 DNS 서버의 대표적인 예로 구글의
8.8.8.8,8.8.4.4와 클라우드플레어의1.1.1.1이 있다. - 03-2에서 정적 IP 주소를 설정할 떄, DNS 주소를 설정하려면,
8.8.8.8을 입력하면 된다고 설명했다.- 이는
로컬 네임 서버의 주소로 구글의공개 DNS 서버 주소를 이용한 것이다.
- 이는

클라이언트가 로컬 네임 서버에게 특정 도메인 네임에 대응되는 IP 주소가 무엇인지 질의했다고 가정해보면,
로컬 네임 서버가 대응되는IP 주소를 알고 있다면,클라이언트에게 그IP 주소를 알려주면 된다.- 하지만 만약
로컬 네임 서버가 대응되는IP 주소를 모른다면, 어떻게 해야될까?- 이 경우
루트 네임 서버(next name server)에게 해당도메인 네임을 질의하게 된다.
- 이 경우
루트 네임 서버는루트 도메인을 관장하는 네임 서버로, 질의에 대해TLD 네임 서버의 IP 주소를 반환할 수 있다.
(3) 루트 네임 서버가 루트 도메인을 관장하는 네임 서버인 것처럼, TLD 네임 서버는 TLD를 관리하는 네임 서버다.

- 위 그림처럼
TLD 네임 서버는 질의에 대해TLD의 하위 도메인 네임을 관리하는네임 서버 주소를 반환할 수 있다. - 하위 도메인 네임을 관리하는
네임 서버는 마찬가지로,- 그보다 하위 도메인 네임을 관리하는
네임 서버 주소를 반환할 수 있다.
- 그보다 하위 도메인 네임을 관리하는
(4) 책임 네임 서버(authoritative name server)는 특정 도메인 영역(zone)을 관리하는 네임 서버다.
책임 네임 서버는 자신이 관리하는 도메인 영역의 질의에 대해서,- 다른
네임 서버에게 떠넘기지 않고, 곧바로 답할 수 있는네임서버다.
- 다른
- 쉽게 말해,
책임 네임 서버는로컬 네임 서버가 마지막으로 질의하는 네임서버다. - 일반적으로
로컬 네임 서버는책임 네임 서버로부터 원하는 IP 주소를 얻어낸다. - 이처럼
루트 도메인을 관리하는루트 네임 서버로부터TLD를 관리하는TLD 네임 서버,최종 IP 주소를 답해주는책임 네임 서버에 이르기까지,네임 서버들은 계층적인 구조를 띠고 있다.
💡 도메인 네임을 풀이(리졸빙)하기 위해 사용되는 네임 서버의 유형으로는
로컬 네임 서버,루트 네임 서버,TLD 네임 서버,책임 네임 서버가 있다.
도메인 네임을 리졸빙하는 과정, 즉 IP 주소를 알아내는 과정을 조금 더 자세히 살펴보자.
로컬 네임 서버가 네임 서버들에게 질의하는 방법에는 크게 2가지가 있다.
- 재귀적 질의
- 반복적 질의
e.g. 다음의 그림들처럼 구성된 네임 서버들을 바탕으로 www.example.com의 IP 주소를 알아내려는 상황을 가정해보면,
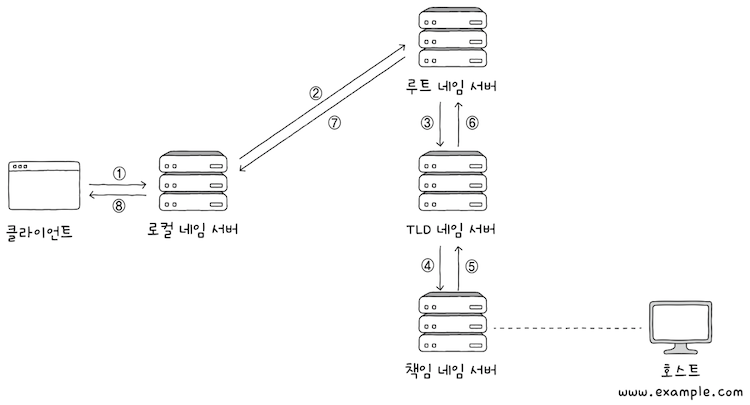
(1) 재귀적 질의(recursive query)는 클라이언트가 로컬 네임 서버에게 도메인 네임을 질의하면,
로컬 네임 서버가루트 네임 서버에게 질의하고,루트 네임 서버가TLD 네임 서버에게 질의하고,TLD 네임 서버가 다음 단계에 질의하는 과정을 반복하며, 최종 응답 결과를 역순으로 전달받는 방식이다.
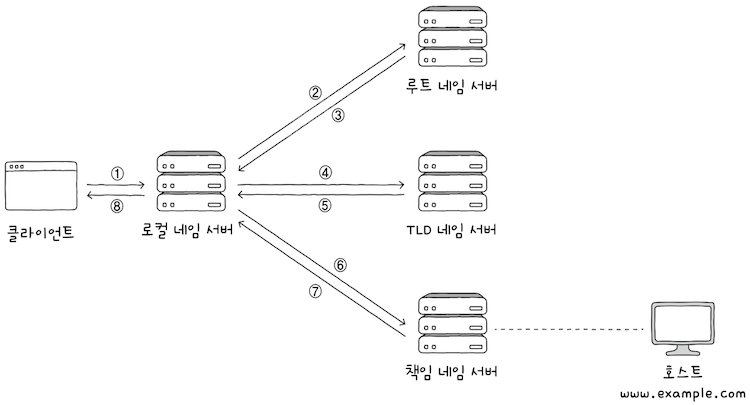
(2) 반복적 질의(iterative query)는 클라이언트가 로컬 네임 서버에게 IP 주소를 알고싶은 도메인 네임을 질의하면,
로컬 네임 서버는루트 도메인 서버에게 질의해서 다음으로 질의할네임 서버의 주소를 응답받고,- 다음으로
TLD 네임 서버에게 질의해서 다음으로 질의할네임 서버의 주소를 응답받는 과정을 반복하다가, - 최종 응답 결과를 클라이언트에게 알려주는 방식이다.
지금까지 설명한 도메인 네임 리졸빙 과정에는 약간의 문제가 있다.
- 예시의 그림만 봐도
하나의 도메인 네임을 리졸빙하기 위해 8개의 단계를 거쳐야하는 것은 시간이 오래 걸리고,- 네트워크 상의 메시지 수가 지나치게 늘어날 수 있다는 점이다.
- 만약 전 세계 모든 호스트가
도메인 네임 리졸빙을 위해루트 네임 서버에 도메인 네임을 한꺼번에 질의하면,루트 네임 서버에 과부하가 생길 것이다.
그래서 실제로 네임 서버들이 기존에 응답받은 결과를 임시로 저장했다가, 추후 같은 질의에 이를 활용하는 경우가 많다.
- 이를
DNS 캐시(cache)라고 한다. DNS 캐시를 저장하는 용도로만 사용되는 서버도 있다.DNS 캐시를 활용하면 더 짧은 시간 안에 원하는 IP 주소를 얻어낼 수 있다.- cf.
DNS 캐시는 영원히 남아있는 것은 아니다.- 임시 저장된 값은
TTL(Time To Live)라는 값과 함께 저장되는데, 이 값은 캐시될 수 있는 시간을 뜻한다.
- 임시 저장된 값은
- cf. 이
TTL은 03-1에서 설명한IP 패킷의 TTL과는 다르다는 점에 유의하자.DNS 캐시의 TTL은 도메인 네임의 질의 결과를 임시로 저장하는 시간을 의미한다.
1.3 자원을 식별하는 URI
지금까지 클라이언트가 메시지를 주고받고자 하는 대상을 식별하는 방법을 설명했다.
- 이번에는 송수신하고자 하는 정보를 식별하기 위한
URI와 - URI를 식별 정보 기준으로 분류한 개념인
URL, URN을 설명하겠다.
이 개념들을 이해하려면, 우선 자원(resource)이 무엇인지 이해해야 한다.
자원이란 네트워크 상의 메시지를 통해 주고받는 대상을 의미한다.- 이는 HTML 파일이 될 수도 있고, 이미지나 동영상 파일이 될 수도 있으며, 텍스트 파일이 될 수도 있다.
- 즉, 두 호스트가 네트워크를 통해 서로 정보를 주고받을 때, 송수신하는 대상이 바로
자원인 셈이다.
오늘날 인터넷 환경을 이루는 대부분의 통신은 HTTP를 기반으로 이루어지므로,
자원이란 용어는 ‘HTTP 요청 메시지의 대상’이라고도 표현한다.- cf. RFC 9110 : The target of an HTTP request is called a “resource”.
- HTTP가 요청하는 대상을 ‘자원’이라고 한다.
네트워크 상에서 자원을 주고받으려면, 자원을 식별할 수 있어야 한다.
- 자원을 식별할 수 있는 정보를
URI(Uniform Resource Identifier)라고 부른다. - 이름 그대로
자원(Resource)을식별(Indentifier)하는 통일된방식(Uniform)이URI인 셈이다.
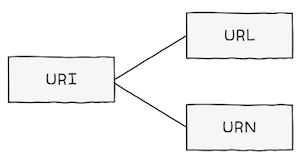
그렇다면 URI는 어떤 정보를 바탕으로 자원을 식별할까?
- 위치를 이용해 자원을 식별하는 것을
URL(Uniform Resource Locator)라고 한다. - 이름을 이용해 자원을 식별하는 것을
URN(Uniform Resource Name)이라 한다.
1.3.1 URL
오늘날 인터넷 환경에서 자원 식별에 더 많이 사용되는 방법은 URL과 URN 중 위치 기반의 식별자인 URL이다.
URL이 어떤 형식을 띠고 있는지 확인해볼까요?- 일반적인
URL 형식은 다음 그림과 같다.

이 URL 형태는 인터넷 표준 문서(RFC 3986)에서 소개하는 일반적인 URL 표기다.
이와 같은 형식이 HTTP(S)에서 어떻게 표기되고 사용되는지를 기준으로 설명한다.
(1) scheme
URL의 첫 부분은 scheme이다. scheme은 자원에 접근하는 방법을 의미한다.
- 일반적으로 사용할 프로토콜이 명시된다.
HTTP를 사용하여 자원에 접근할 떄는http://를 사용하고,HTTPS를 사용하여 자원에 접근할 떄는https://를 사용한다.- scheme의 종류가 궁금한 독자들은 다음 링크를 참고하자.
(2) authority
authority에는 ‘호스트를 특정할 수 있는 정보’, 이를테면 IP 주소 혹은 도메인 네임이 명시된다.
콜론(:)뒤에 포트 번호를 덧붙일 수 있다.
(3) path
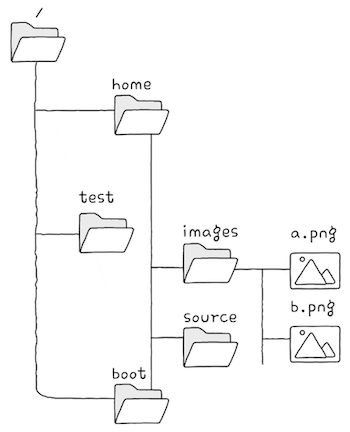
path에는 ‘자원이 위치한 경로’가 명시된다.
- 자원이 위치는 슬래시()를 기준으로 계층적으로 표현되고, 최상위 경로 또한 슬래시로 표현된다.
- e.g. 여러분이 원하는 자원의 이름이
a.png이고,a.png는 위 쪽 그림과 같은 위치에 존재한다고 가정하면,a.png는 어디에 있을까?최상위 경로 아래(/),home 아래(/home),images 아래(/home/images)에 있다.- 따라서
a.png의 path는/home/images/a.png가 된다.
1http://example.com/home/iamges/a.png
URL에서의 경로도 이와 같다.
- ‘http 프로토콜로 접근 가능한 도메인 네임 example.com의 자원 중,
/home/iamges/a.png의 자원’은 다음과 같은 URL로 표현할 수 있다.
(4) query
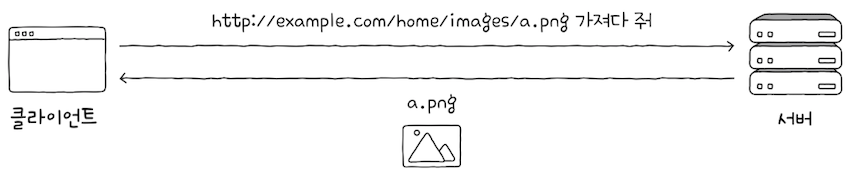
다음 절에서 한 번 더 다루겠지만, HTTP는 요청-응답 기반의 프로토콜이다.
클라이언트는서버에게URI(URL)가 포함된HTTP 요청 메시지를 보내고,HTTP 서버는 이에 대해HTTP 응답 메시지를 보낸다.- 지금까지 학습한 URL 구문만으로도 위의 그림처럼 문제없이 자원의 위치를 식별할 수 있는 경우도 있지만,
- 때로는 더 많은 정보가 필요할 수 있다.

e.g. 위 그림처럼 수 많은 정보 중에서 ‘특정 단어를 검색한 결과’에 해당하는 자원이나,
- 수많은 상품 중에서 ‘특정 상품을 검색한 뒤 그 결과를 내림차순으로 정렬한 결과’에 해당하는 자원을
scheme,authority,path만으로 모듀 표현하기란 어렵다.- 이럴 떄 사용할 수 있는 것이
쿼리 문자열(query string)이다.쿼리 파라미터(query parameter)라고도 부른다.
쿼리 문자열은물음표(?)로 시작되는<키=값>형태의 데이터로,앰퍼샌드(&)를 사용해 여러 쿼리 문자열을 연결할 수 있다.
1https://example.com/random/path?query=value&query2=value2
위 URL은 <query=value>, <query2=value2>라는 쿼리 문자열이 포함된 예시다.

cf. 쿼리 문자열은 서버를 개발하는 개발자가 설계하기 나름이다.
- e.g. 위 그림처럼 부동산 검색 웹사이트 URL이나 도서 판매 웹 사이트 URL을 설계할 수도 있다.
- 쿼리 문자열을 이용하면 더 다양하게 상호작용할 수 있다.
(5) fragment
fragment는 ‘자원의 한 조각을 가리키기 위한 정보’이다.
- 흔히 HTML 파일과 같은 자원에서 특정 부분을 그리키기 위해 사용된다.
1https://datatracker.ietf.org/doc/html/rfc3986
e.g. 위와 같은 특정 HTML 파일 자원의 위치를 나타내는 URL이 있다고 가정해면,
- 이번에는
아래 URL을 보면, 위 HTML 파일 자원 내의 특정 부분을 나타낸다. - 브라우저로
위의 URL과아래의 URL에 각각 접속해보면, 차이를 알 수 있다. 위의 URL은 HTML 파일 자원 그 자체를 가리키기에 브라우저로 접속해보면, HTML의 첫 부분이 보이지만,아래의 URL은 HTML 자원의 특정 부분을 가리키기에,- 브라우저 접속해보면, HTML 파일의 특정 부분으로 이동하여 보일 것이다.
1https://datatracker.ietf.org/doc/html/rfc3986#section-1.1.2
지금까지의 자원과 URL에 대해 학습했다.
- 이제 웹 브라우저를 열고 여러 웹 사이트를 돌아다니며 URL을 관찰해보길 바랍니다.
- 지금까지 배운 URL 구조를 따르고 있다는 것을 확인할 수 있을 것이다.
1.3.2 URN
URN도 간략하게 알아보면, URL은 위치를 기반으로 자원을 식별한다.
- 그런데 자원의 위치는 언제든 변할 수 있다.
- 그래서 자원의 위치가 변한다면, URL은 유효해지지 않을 수 있다.
- 다시 말해, 자원의 위치가 변경되면,
기존 URL로는 자원을 식별할 수 없게 된다. - 이것은 URL의 고질적인 문제 중 하나다.
반면에, URN은 자원에 고유한 이름을 붙이는 이름 기반 식별자이기에,
- 자원의 위치와 무관하게 자원을 식별할 수 있다는 장점이 있다.
urn:isbn:0451450523같은 URN 예시를 보면,ISBN이0451450523인 도서를 나타내는 URN 예시다.
또한 다음 URN은 인터넷 기술 표준을 만드는 단체인 국제 인터넷 표준화 기구 IETF(Internet Engineering Task Force)의 공식 문서 중 RFC 2648을 나타내는 URN 예시다.
1urn:ietf:rfc:2648
이와 같은 URN을 이용하면, 위치나 프로토콜과 무관하게 자원을 식별할 수 있겠죠?
- 다만,
URN은 아직URL만큼 널리 채택된 방식은 아니기에, - 자원을 식별할
URI로는URN보다는URL이 더 많이 사용된다.
1.3.3 DNS 레코드 타입
앞서 도메인 네임과 네임 서버, DNS의 동작 과정을 살펴봤다.
- 이번에는 여기서 한 걸음 더 나아가
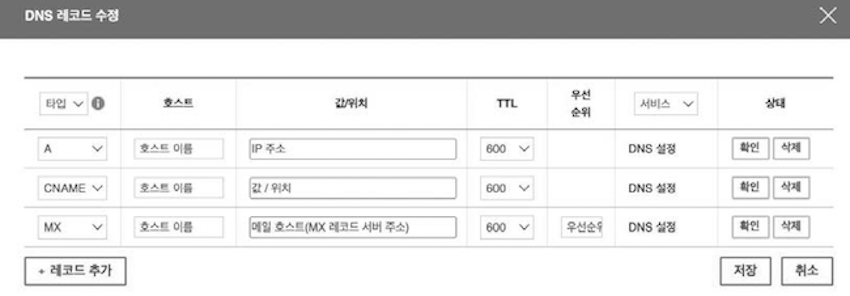
DNS가 올바르게 동작하기 위해네임 서버가 무엇을 저장하는지 알아본다. 네임 서버는DNS 자원 레코드(DNS resource record)라 불리는 정보를 저장하고 관리한다.- 단순히
DNS 레코드라 부르기도 하는데, 위 화면에서 각 행이DNS 레코드다.
- 단순히
이러한 레코드는 도메인 네임을 구입한 뒤, 웹 사이트에 도메인 네임을 적용시킬 떄 자주 접하게 된다.
- e.g. 여러분이 IP 주소
1.2.3.4인 호스트를 접속 가능한 웹 서비스로 만들었다고 가정해보면,- 즉, 다른 사용자들은
1.2.3.4로 접속하면 여러분이 웹 서비스를 이용할 수 있다. - 그리고 여러분은
example.com이라는 도메인 네임을 구입하여 이를1.2.3.4에 대응시키고자 한다고 해보자.
- 즉, 다른 사용자들은
- 그런데 도메인 네임
example.com이1.2.3.4에 대응된다는 사실을네임 서버에게 알리지 않는다면,- 당연히
네임 서버는 그 사실을 알 수 없다.
- 당연히
- 그래서 여러분은 ‘도메인 네임 example.com이 1.2.3.4에 대응된다는 사실’을 네임 서버에게 알리기 위해,
도메인 레코드를 추가해야 한다.
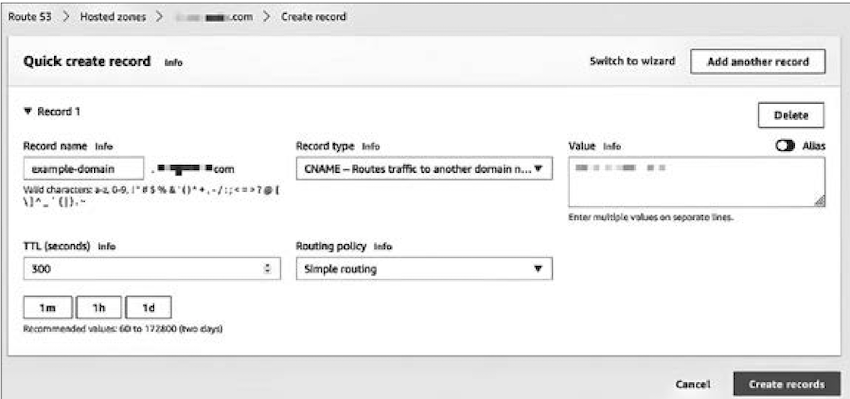
위 화면은 다른 DNS 관리 서비스에서 새로운 레코드를 등록하는 과정을 보여주는 화면이다.
두 화면을 보면서 도메인 레코드마다 공통으로 유지하는 정보는 어떤 것이 있는지 확인해본다.
- 우선
이름(호스트 이름, Record name)과값(값/위치, Value)이 있다. - 그리고 TTL을 설정하는 곳도 있다.
- 또한, 공통 정보로
유형(타입, Record type)이 있다. - 각 레코드에는 유형이 정해져 있기에
레코드의 유형이 달라지면,레코드의 이름과 값의 의미가 달라진다. - 다양한 레코드 유형이 있지만, 우리가 자주 접할
레코드 유형은 다음과 같다.
| 레코드 유형 | 설명 |
|---|---|
| A | 특정 호스트에 대한 도메인 네임과 IPv4 주소와의 대응 관계 |
| AAAA | 특정 호스트에 대한 도메인 네임과 IPv6 주소와의 대응 관계 |
| CNAME | 호스트 네임에 대한 별칭 지정 |
| NS | 특정 호스트의 IP 주소를 찾을 수 있는 네임 서버 |
| MX | 해당 도메인과 연동되어 있는 메일 서버 |
e.g. 다음과 같은 레코드는 example.com이 1.2.3.4에 대응되어 있다는 것을 보여준다.
- 즉, 다음과 같은 레코드를 저장하는 네임 서버에
example.com을 질의하면,1.2.3.4를 응답받을 수 있다.
| 타입 | 이름 | 값 | TTL |
|---|---|---|---|
| A | example.com | 1.2.3.4 | 300 |
여기에 다음과 같은 레코드가 추가되었다고 가정해보면,
- 추가된 레코드는
example.com에 대한 별칭으로www.example.com.을 사용하겠다는 의미다. - 따라서
www.example.com.을 질의하면 같은 IP 주소인1.2.3.4를 응답받게 된다.
| 타입 | 이름 | 값 | TTL |
|---|---|---|---|
| A | example.com | 1.2.3.4 | 300 |
| CNAME | www.example.com | example.com. | 300 |
2. HTTP
HTTP는 사용자와 밀접하게 맞닿아 있는 프로토콜로, 오늘날 웹 세상의 기반을 이루는 중요한 역할을 한다.
HTTP(Hypertext Transfer Protocol)에는 중요한 4가지 특징이 있다.
- 요청과 응답을 기반으로 동작하고,
- 미디어 독립적이며
- 상태를 유지하지 않고
- 지속 연결을 지원한다.
각 특성의 의미와 HTTP 메시지 구조를 파악하면, HTTP의 개괄적인 구조를 이해할 수 있다.
2.1 HTTP의 특성
HTTP는 응용 계층에서 정보를 주고받는 데 사용되는 프로토콜이다. HTTP의 4가지 주요 특성은 다음과 같다.
2.1.1 요청-응답 기반 프로토콜
HTTP는 클라이언트-서버 구조 기반의 요청-응답 프로토콜이다.
- 호스트의 대표적인 종류에는
클라이언트와서버가 있고,클라이언트는 서버에게 요청 메시지를 전송하며,서버는 클라이언트에게 요청에 대한 응답 메시지를 전송한다.
HTTP는 이와 같이클라이언트와서버가 서로 HTTP 요청 메시지와 HTTP 응답 메시지를 주고받는 구조로 동작한다.- 그렇기에 같은
HTTP 메시지일지라도HTTP 요청 메시지와HTTP 응답 메시지는 메시지 형태가 다르다.
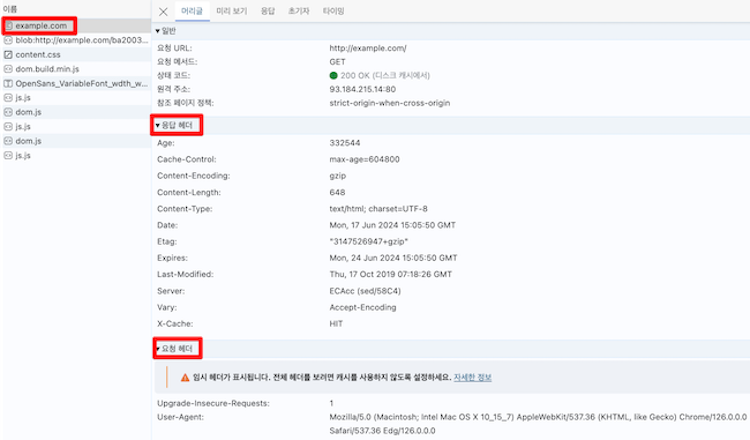
요청 메시지와 응답 메시지 형태를 직접 확인해볼려면, 웹 브라우저를 열고 개발자 도구를 켜보자.
- [Network] 탭을 클릭한 후, 특정 웹 사이트에 접속해보세요.
- 해당 웹 사이트에 접근하는 과정에서 주고받은 자원들을 개발자 도구에서 실시간으로 확인할 수 있다.
- 위 그림은 크롬 브라우저의 개발자 도구를 열고,
- [Network] 탭을 클릭한 후,
http://example.com에 접속했을 떄 나타난 화면이다. - 여기서 임의의 자원인
example.com을 클릭해보면, - HTTP
요청 메시지 헤더(request Header)와 HTTP응답 메시지 헤더(Response Header)를 볼 수 있다.
- [Network] 탭을 클릭한 후,
2.1.2 미디어 독립적 프로토콜
클라이언트는 HTTP 요청 메시지를 통해 서버의 자원을 요청할 수 있고,
서버는 HTTP 응답 메시지로 요청받은 자원에 대해 응답할 수 있다.
그렇다면 HTTP는 어떤 자원을 주고받을까? HTTP를 정의한 공식 문서(RFC 9110)에서는 다음과 같이 설명한다.
💡 RFC 9110
The target of an HTTP request is called a “resource”.
HTTP가 요청하는 대상을 “자원”이라고 한다.
HTTP does not limit the nature of a resource; it mereyl defines an interface that might be used to interact with resources.
HTTP는 자원의 특성을 제한하지 않으며, 단지 자원과 상호 작용하는 데 사용할 수 있는 인터페이스를 정의할 뿐이다.
Most resources are identified by a Uniform Resource Identifieer (URI).
대부분의 자원은 URI로 식별된다.
다시 말해, HTTP는 주고받을 자원의 특성과 무관하게, 그저 자원을 주고받을 수단(인터페이스)의 역할만 수행한다.
- 실제로 HTTP를 통해서 HTML, JPEG, PNG, JSON, XML, PDF 파일 등 다양한 종류의 자원을 주고받을 수 있다.
HTTP에서 메시지로 주고받는 자원의 종류를 미디어 타입(media type)이라 부른다.
MIME 타입(Multipurpose Internet Mail Extensions Type)이라고도 부른다.- 즉,
HTTP는 주고받을 미디어 타입에 특별히 제한을 두지 않고, - 독립적으로 동작이 가능한 미디어 독립적인 프로토콜이라 할 수 있다.
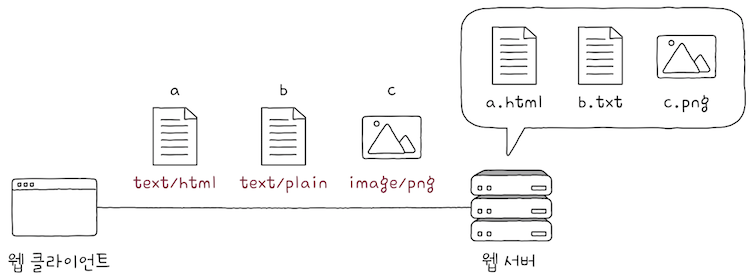
미디어 타입을 더 자세히 살펴보면, 미디어 타입은 ‘일종의 웹 세상의 확장자’와 같은 개념이다.
- 일반적으로 파일의 종류를
.html,.png,.json,.mp4와 같은 확장자로 나타낼 수 있듯, - HTTP를 통해 송수신하는 정보의 종류는 미디어 타입으로 나타낼 수 있다.
- 위 그림에서 붉은 색 글자가 미디어 타입이다.
- 차례로
HTML,일반 텍스트,PNG이미지 타입을 나타낸다.
1type/subtype
미디어 타입은 기본적으로 슬래시를 기준으로 하는 타입/서브타입(type/subtype)형식으로 구성된다.
타입(type)은 데이터 유형을 나타내고,서브타입(subtype)은 주어진 타입에 대한 세부 유형을 나타낸다.
미디어 타입의 종류는 매우 다양하며, 필요에 따라 새로운 미디어 타입을 등록할 수도 있다.
- 그렇기에 모든 미디어 타입을 암기할 필요는 없고, 필요할 떄마다 찾아보는 것이 일반적이다.
- 다음 표를 통해 개발 시에 자주 마주칠 대표
미디어 타입과서브타입의 예시를 보자. - 전체 목록을 확인하려면 다음 URL을 참고.
| 타입 | 타입 설명 | 서브타입 | 서브타입 설명 |
|---|---|---|---|
| text | 일반 텍스트 형식의 데이터 | text/plain | 평문 텍스트 문서 |
| text/html | HTML 문서 | ||
| text/css | CSS 문서 | ||
| text/javascript | 자바스크립트 문서 | ||
| image | 이미지 형식의 데이터 | image/png | PNG 이미지 |
| image/jpeg | JPEG 이미지 | ||
| image/webp | WebP 이미지 | ||
| image/gif | GIF 이미지 | ||
| video | 비디오 형식의 데이터 | video/mp4 | MP4 비디오 |
| video/ogg | OGG 비디오 | ||
| video/webm | WebM 비디오 | ||
| video/midi | MIDI 오디오 | ||
| video/wav | WAV 오디오 | ||
| application | 바이너리 형식의 데이터 | application/octet-stream | 알수없는 바이너리 데이터를 포함한 일반적인 바이너리 데이터 |
| application/pdf | PDF 문서 형식 데이터 | ||
| application/xml | XML 형식 데이터 | ||
| application/json | JSON 형식 데이터 | ||
| application/x-www-form-urlencoded | HTML 입력 폼 데이터 (키-값 형태의 입력값을 URL 인코딩한 데이터) | ||
| multipart | 각기 다른 미디어 타입을 가질 수 있는 여러 요소로 구성된 데이터 | multipart/form-data | HTML 입력 폼 데이터 |
| multipart/encrypted | 암호화된 데이터 |
cf. 별표 문자(*)는 여러 미디어 타입을 통칭하기 위해 사용된다.
- e.g.
text/*는 text 타입의 모든 서브타입을 나타내고, - e.g.
iamge/*는 image 타입의 모든 서브 타입을 나타낸다. - e.g. 또
*/*는 모든 미디어 타입을 나타낸다.
1type/subtype;parameter=value
또한 미디어 타입에는 부가적인 설명을 위해 선택적으로 매개변수가 포함될 수 있다.
- 매개변수는
타입/서브타입;매개변수=값의 형식으로 표현한다.- 위 표현의
parameter=value를 참고하자.
- 위 표현의
- e.g.
type/html;charset=UTF-8은 미디어 타입이 HTML 문서 타입이며,- HTML 문서 내에서 사용된 문자는 UTF-8로 인코딩되었음을 의미한다.
💡
UTF-8 인코딩과 위 표에서application/x-www-form-urlencoded 서브타입을 설명할 떄,
URL 인코딩은 모두 문자 인코딩 방식의 일종이다.문자 인코딩이란 사람이 읽을 수 있는 문자를 컴퓨터가 이해하는 문자로 변환하는 방식을 의미한다.
2.1.3 스테이트리스 프로토콜
HTTP는 상태를 유지하지 않는 스테이트리스(stateless) 프로토콜이다.
- 이는
서버가HTTP 요청을 보낸 클라이언트와 관련된 상태를 기억하지 않는다는 의미다. - 그렇기 때문에
클라이언트의 모든 HTTP 요청은 기본적으로 독립적인 요청으로 간주된다.
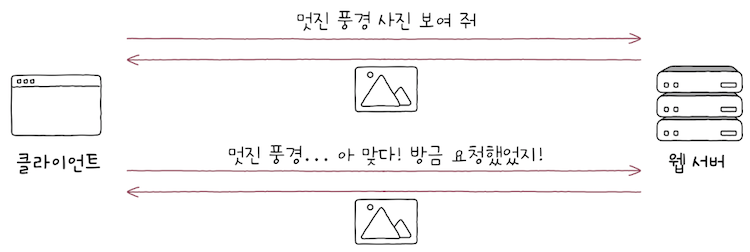
e.g. 클라이언트가 실수로 특정 HTTP 요청 메시지를 서버에게 여러 번 전송했다고 가정해보면,
서버는 이 요청들을 각기 다른 요청으로 간주한다.- 따라서
클라이언트는 같은 응답 메시지를 여러 번 받을 수 있다.
상태를 유지하지 않는 특성은 언뜻 효율적이지 않아 보일 수도 있지만, 실제로는 장점이 더 명확하다.
HTTP 서버는 일반적으로 많은 클라이언트와 동시에 상호 작용한다.- 동시에 처리해야 할
요청 메시지의 수는 수천 개가 될 수도 있고, 많게는 수백만 개가 될 수도 있다. - 이런 상황에서 모든
클라이언트의 상태 정보를 유지하는 것은서버에 큰 부담이 된다.
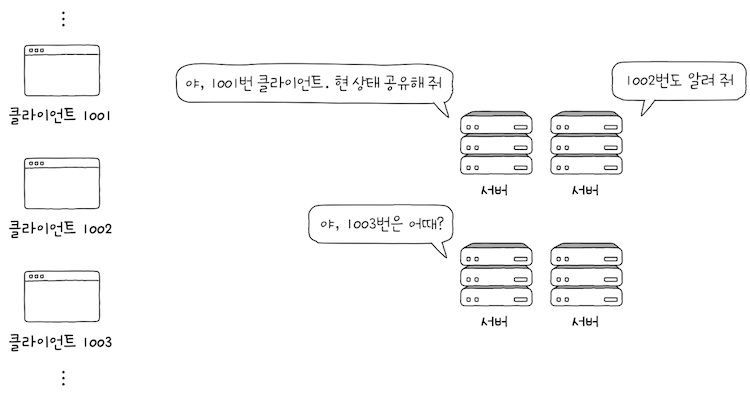
또한, 서버는 하나가 아니라 여러 대로 구성될 수도 있다.
- 이런 상황에서
모든 서버가 모든클라이언트의 상태를 유지할 경우,클라이언트는여러 서버를 동시에 이용하기가 어려워진다.
모든 서버가모든 클라이언트의 상태 정보를 공유하는 작업은 매우 번거롭고 복잡하기 때문이다.
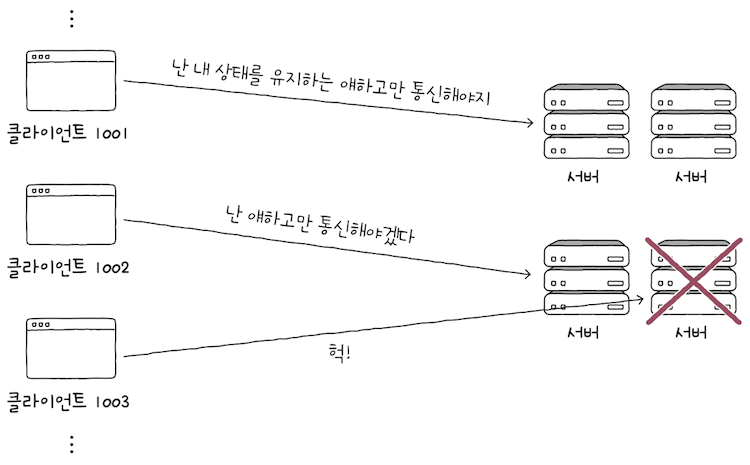
HTTP가 상태를 유지하는 프로토콜이었다면,
클라이언트는 자신의 상태를 기억하는 특정 서버하고만 상호작용할 수 있게 되어,특정 클라이언트가특정 서버에 종속될 수 있다.
- 이런 상황에서 어느
한 서버에 문제가 발생하면,- 해당
서버에종속된 클라이언트는 직전까지의 HTTP 통신 내역을 잃어버리는 상황이 발생할 수도 있다.
- 해당
HTTP가 만들어졌을 떄부터 오늘날까지 이어지는 핵심 설계 목표는 확장성(scalability)과 견고성(robustness)이다.
서버는 하나가 아니라 여러 개가 있을 수도 있다고 했죠?
- 상태를 유지하지 않고, 모든 요청을 독립적인 요청으로 처리하는 것은
특정 클라이언트가특정 서버에 종속되지 않도록 하며,서버의 추가나 문제 발생 시 대처가 용이하도록 한다.
- 즉, 상태를 유지하지 않는
스테이트리스한 특성은- 필요하다면 언제든 쉽게 서버를 추가할 수 있기 떄문에 확장성이 높고,
- 서버 중 하나에 문제가 생겨도 쉽게 다른 서버로 대체가 가능하기 떄문에 견고성이 높다.
💡 cf.
HTTP가 스테이트리스 프로토콜이라 할지라도,
- 서버가 클라이언트의 요청을 매번 처음 보는 것처럼 동작하는 것만 아니다.
- 상태를 유지하지 않는 HTTP의 특성을 보완하기 위한 여러 방법이 있고, 이는 뒤에서 배운다.
2.1.4 지속 연결 프로토콜
HTTP는 지속해서 발전 중인 프로토콜인 만큼, 여러 버전이 있다.
- 오늘날 많이 사용되는 HTTP 버전인
HTTP 1.1과HTTP 2.0이 포함된다. - 기본적으로
HTTP는 TCP 상에서 동작하는데,HTTP는 비연결형 프로토콜이지만,TCP는 연결형 프로토콜이다.
- 따라서
초기 HTTP 버전(HTTP 1.0 이하)은3-way 핸드셰이크를 통해 TCP 연결을 수립한 후,- 요청에 대한 응답을 받으면, 연결을 종료하는 방식을 동작한다.
- 추가적인 요청-응답을 하기 위해서는 다시 TCP 연결을 수립해야 했다.
- 이런 방식을
비지속 연결이라고 한다.
- cf. 최근 HTTP 버전인
HTTP 3.0은 UDP 상에서 동작한다.- HTTP의 버전별 특성은 이번 절 HTTP 발전사를 참고.
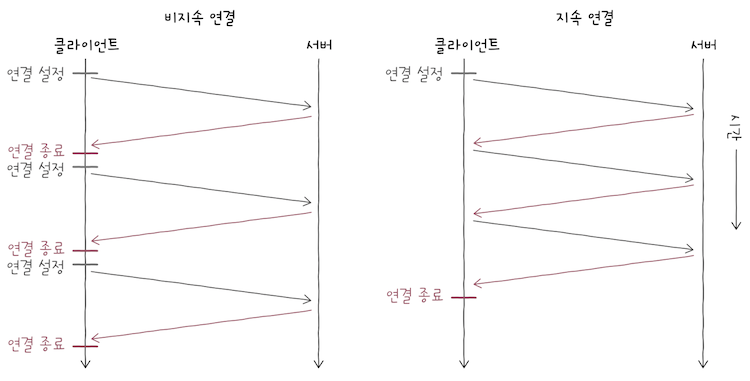
하지만 최근 대중적으로 사용되는 HTTP 버전(HTTP 1.1 이상)은 지속 연결(persistent connection)이란 기술을 제공한다.
- 다른 표현으로는
킵 얼라이브(keep-alive)라고도 부른다. - 이는
하나의 TCP연결상에서 여러 개의 요청-응답을 주고받을 수 있는 기술이다. 지속 연결 기능을 지원하지 않는 HTTP와지속 연결 기능을 지원하는 최근의 HTTP와의 차이는 위 그림과 같다.- 그림의 내용처럼 지속 연결 기능을 지원하는
HTTP는 매번 새롭게 연결을 수립하고,- 종료해야 하는 비지속 연결에 비해, 더 빠르게
여러 HTTP요청과 응답을 처리할 수 있다.
- 종료해야 하는 비지속 연결에 비해, 더 빠르게
정리하면, HTTP는 요청-응답 기반 프로토콜이자, 미디어 독립적이고, 스테이트리스하며, 지속 연결 기능을 제공하는 프로토콜이다.
2.2 HTTP 메시지 구조
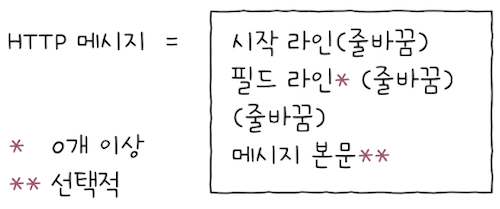
그렇다면 HTTP 메시지의 구성을 살펴보면, HTTP의 큰 그림을 그리는 것이라 생각해도 좋다. 암기하기 보다는 구조를 대략적으로 살펴보자. 여기서는 대중적으로 사용되는 HTTP 버전 중 하나인 HTTP 1.1 버전의 메세지를 위주로 학습한다.
HTTP 메시지는 시작 라인, 필드 라인, 메시지 본문으로 이루어져 있다.
필드 라인은 없거나 여러 개 있을 수 있고,메시지 본문은 없을 수 있다.- 또한
필드 라인과메시지 본문사이에는 빈 줄바꿈이 있다.
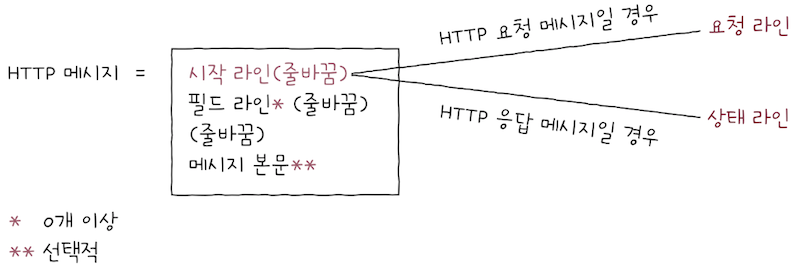
시작 라인(start-line)부터 보면, HTTP 메시지는 HTTP 요청 메시지일수도 있고, HTTP 응답 메시지일 수도 있다.
HTTP 메시지가HTTP 요청 메시지일 경우,시작 라인은 ‘요청 라인’이 되고,HTTP 메시지가HTTP 응답 메시지일 경우,시작 라인은 ‘상태 라인’이 된다.
1요청 라인 = 메시지(공백) 요청 대상(공백) HTTP 버전(줄바꿈)
HTTP 요청 메시지의 시작 라인인 요청 라인(request-line)의 형식은 위와 같다.
메시지, 요청 대상, HTTP 버전은 모두 공백으로 구분된다.
메서드(method)란 클라이언트가 서버의 자원(요청 대상)에 대해 수행할 작업의 종류를 나타낸다.
- 대표적으로 GET, POST, PUT, DELETE 등이 있다.
- 요청 대상이 같아도 메서드가 다르면, 각기 다른 요청으로 처리된다.
- 다양한 메서드의 종류와 종류별 동작은 뒤에서 설명한다.
요청 대상(request-target)은 HTTP 요청을 보낼 서버의 자원을 의미한다.
- 보통 이곳에는 (쿼리가 포함된) URI의 경로가 명시된다.
- e.g. 클라이언트가
http://www.example.com/hello?q=world로 요청을 보낼 경우,- 요청 대상은
/hello?q=world가 된다. - 만약 하위 경로가 없더라도, 요청 대상은
슬래시(/)로 표기해야 한다.
- 요청 대상은
- 즉, e.g. 클라이언트가
http://www.example.com으로 요청할 경우, 요청 대상은/가 된다.
HTTP 버전(version)은 이름 그대로 사용된 HTTP 버전을 의미한다.
HTTP/버전이라는 표기 방식을 따르며,HTTP 버전 1.1은HTTP/1.1로 표기된다.
1상태 라인 = HTTP 버전(공백) 상태 코드(공백) 이유 구문*(줄바꿈)23*는 선택적이란 뜻
HTTP 메시지가 HTTP 응답 메시지일 경우, 시작 라인은 위와 같은 상태 라인(status-line)이 된다.
상태 라인의 형식은 위와 같으며,HTTP 버전,상태 코드,이유 구문모두 공백으로 구분된다.
HTTP 버전은 사용된 HTTP의 버전을 나타내며, 상태 코드(status code)는 요청에 대한 결과를 나타내는 3자리 정수다.
- 클라이언트는 상태 코드를 통해 요청이 어떻게 처리되었는지 판단할 수 있다.
이유 구문(reason phrase)은 상태 코드에 대한 문자열 형태의 설명을 의미한다.
e.g. 상태 코드 200은 ‘요청이 성공적으로 받아들여지고 수행되었음’을 의미한다.
- 이유 구문까지 함께 표기한 상태 라인의 예시는 다음과 같다.
HTTP/1.1 200 OK
또 다른 예로, 상태 코드 404는 ‘요청한 자원이 존재하지 않음’을 의미한다.
- 이를 이유 구문까지 함께 표기한 상태 라인은 다음과 같다.
HTTP/1.1 404 Not Found
다양한 상태 코드와 이유 구문에 대해서는 이어서 알아본다.

지금까지 HTTP 메시지의 첫 줄인 시작 라인을 알아봤다. 이버에는 피드 라인에 대해 알아본다.
필드 라인에는 0개 이상의HTTP 헤더(header)가 명시된다.- 그래서 이를
헤더 라인(header-line)이라고 부른다.
- 그래서 이를
- 여기서 HTTP 헤더란 HTTP 통신에 필요한 부가정보를 의미한다.
- cf. 공식문서에서는 필드 라인에 ‘0개 이상’의 HTTP 헤더가 명시된다고 언급되지만,
- 실제로는 한 HTTP 메시지에 아주 다양한 HTTP 헤더들이 사용되는 것이 일반적이다.
1GET /example-page HTTP/1.12Host: www.example.com3User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/118.04Accept: text/html
필드 라인에 명시되는 각 HTTP 헤더는 콜론(:)을 기준으로 헤더 이름(header-name)과 하나 이상의 헤더값(header-value)으로 구성된다.
- 위 예시로 첫 줄 다음으로 표기한 글자들이 HTTP 헤더이다.
- HTTP 헤더의 종류는 다양하며, 뒤에서 학습한다.
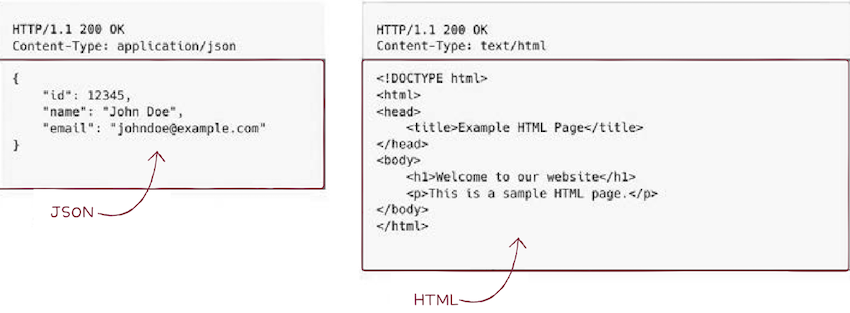
HTTP 요청 혹은 응답 메시지에서 본문이 필요한 경우, 이는 메시지 본문(message-body)에 명시된다.
메시지 본문은 존재하지 않을 수도 있고, 위와 같은 다양한 콘텐츠 타입이 사용될 수도 있다.
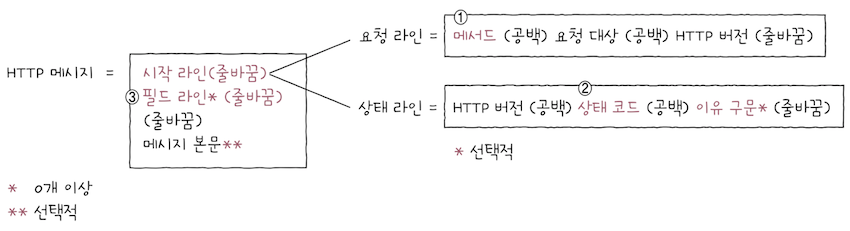
이렇게 HTTP 메시지의 구조를 살펴봤다. 지금까지 학습한 내용을 그림으로 표현하면 위와 같다.
- 이제부터 시작 라인의 (1) 메서드와 (2) 상태 코드와 이유 구문을 학습한 뒤,
- 다음 절에서 (3) 다양한 HTTP 헤더를 학습하는 순서로 HTTP를 살펴본다.
- cf. HTTP
요청 메시지의 요청 라인에는메서드가 명시되고,- HTTP
응답 메시지의 상태 라인에는상태 코드가 명시된다.
- HTTP
2.3 HTTP 메서드
우선 각 메서드에 대한 설명을 살펴보고, 주로 사용되는 메서드를 자세히 알아보자.
| HTTP 메서드 | 설명 |
|---|---|
| GET | 자원을 습득하기 위한 메서드 |
| HEAD | GET과 동일하나, 헤더만을 응답받는 메서드 |
| POST | 서버로 하여금 특정 작업을 처리하게끔 하는 메서드 |
| PUT | 자원을 대체하기 위한 메서드 |
| PATCH | 자원에 대한 부분적 수정을 위한 메서드 |
| DELETE | 자원을 삭제하기 위한 메서드 |
| CONNECT | 자원에 대한 양방향 연결을 시작하는 메서드 |
| OPTIONS | 사용 가능한 메서드 등 통신 옵션을 확인하는 메서드 |
| TRACE | 자원에 대한 루프백 테스트를 수행하는 메서드 |
표의 메서드 중에서 특히 자주 사용되는 메서드는 색이 있는 GET, HEAD, POST, PUT, PATCH, DELETE이다.
2.3.1 GET - 가져다주세요
GET 메서드는 특정 자원을 조회할 떄, 사용되는 메서드이다.
- 클라이언트가 서버에게 ‘이것을 가져다주세요’라고 요청을 보내는 것과 같다.
- 여기서 ‘이것’은 조회하고자 하는 자원을 의미한다.
- 이는 HTML이 될 수도 있고, JSON이 될 수도 있으며, 이미지 파일이나 일반 텍스트 파일이 될 수도 있다.
GET은 가장 흔히 사용되는 메서드 중에 하나이며, 웹 브라우저에서도 빈번하게 사용된다.
- 웹 브라우저를 통해 조회하는 자원은 대부분 GET 요청 메시지에 대한 응답이다.
- e.g. 웹 브라우저에
http://www.example.com을 입력했다고 가정해보면,- 웹 브라우저는 사용자에게 해당 웹 페이지를 보여줄 것이다.
- 사실 이것은 웹 브라우저가
www.example.com에게 ‘당신의 웹 페이지의 자원을 가져다주세요’라고 요청하고, - 웹 페이지 자원을 응답받은 것과 같다.
GET은 ‘이것을 가져다주세요’와 같은 요청 메서드라고 했다.
- 그렇다면 ‘이것’에 해당하는 자원을 요청 메시지에 포함해야겠죠.
- 이를 위해 사용되는 것이 요청 라인의
요청 대상그리고Host 헤더이다.
(1) 요청 메시지
1GET /example-page HTTP/1.12Host: www.example.com3Accept: *
e.g. http://www.example.com/example-page에 대한 간략화된 GET 요청 메시지이다.
실제로는 위 예제보다 더 많은 헤더가 붙긴 합니다만, 우선 1~2줄까지 글자를 중심으로 살펴보자.
- 앞서 요청 라인의 ‘요청 대상’에는 일반적으로 요청할 자원에 대한 쿼리가 포함된 경로가 명시된다.
- e.g.
/example-page로 표현된다.
- e.g.
Host 헤더에는 요청을 보낼 호스트가 명시된다.- 다음 예제에서는
Host: www.example.com으로 표현된다.
- 다음 예제에서는
(2) 응답 메시지
1HTTP/1.1 200 OK2Content-Type: text/html3Content-Length: 123445<!DOCTYPE html>6<html>7<head>8<title>Example Page</title>9</head>10<body>11<h1>Hello, World!</h1>12</body>13</html>
GET 요청 메시지가 성공적으로 처리되었다면, 이에 대한 응답으로 요청한 자원을 전달받게 된다.
- 다음 예제는 HTML 문서를 응답받은 예제다.
- 위 3줄을 제외한 아래 HTML은 응답 메시지의 본문이자 응답받은 자원(HTML 문서)이다.
(3) 요청 메시지
1GET /index.html?name1=value1&name2=value=2 HTTP/1.12Host: www.example.com3Accept: *
cf. GET 메서드에 요청 메시지 본문을 포함시키는 것은 바람직하지 않다.
- GET 요청 메시지에서는 메시지 본문보다 위 예시처럼 쿼리 문자열이 사용되는 경우가 많다.
2.3.2 HEAD - 헤더만 가져다주세요
(1) 요청 메시지
1HEAD /example-page HTTP/1.12Host: www.example.com3Accept: *
HEAD 메서드는 사실상 GET 메서드와 동일한 역할을 한다.
- 유일한 차이점은 응답 메시지에 메시지 본문이 포함되지 않는다는 것이다.
- 즉, HEAD 메서드를 사용하면, 서버는 요청에 대한 응답으로 응답 메시지의 헤더만을 반환한다.
- 요컨대 HEAD 메서드는 클라이언트가 서버에게 ‘헤더만 가져다주세요’라고 요청을 보내는 것과 같다.
- 위 예시는 앞의 예시와 동일한 URI로 HEAD 요청을 보낸 예시다.
(2) 응답 메시지
1HTTP/1.1 200 OK2Content-Type: text/html3Content-Length: 1234
이에 대한 응답 메시지를 보면, 앞서 설명했던대로 메시지 본문없이 헤더만을 포함한다는 것을 알 수 있다.
2.3.3 POST - 처리해 주세요
POST 메서드는 서버로 하여금 특정 작업을 처리하도록 요청하는 메서드다.
GET이 ‘이것을 가져다주세요’와 같은 메서드라면,POST는 ‘이것을 처리해주세요’와 같은 메서드로 이해할 수 있다.- 짐작할 수 있듯이, POST 메서드는 범용성이 넓은 메서드다.
- 웹과 관련된 개발을 하게 된다면, GET 다음으로 많이 접하게 될 메서드라고 볼 수 있다.
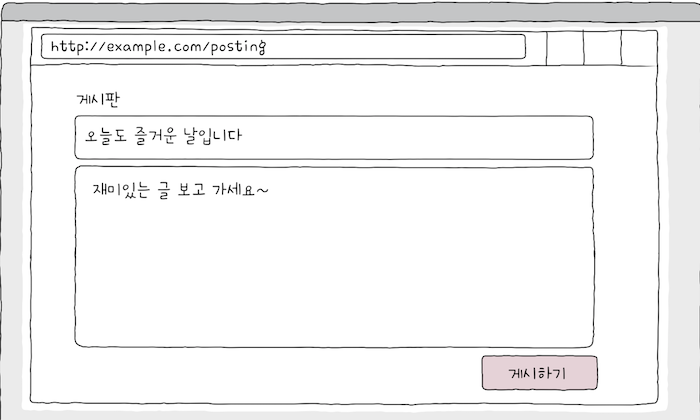
e.g. http://example.com/posting에 접속했을 떄의 화면이 위와 같고,
어떤 클라이언트가 입력 폼에 글을 입력한 뒤, [게시하기] 버튼을 눌렀다고 가정해보면,
- 이떄 클라이언트는 서버에 어떤 요청을 보내야 할까?’
- ‘이 글을 처리해주세요’라는 요청을 보내야겠죠? 이떄 POST 메서드가 사용된다.

처리할 대상은 흔히 메시지 본문으로 명시된다. 위 POST 요청 메시지 예시로 확인해보세요.
1HTTP/1.1 201 Created2Content-Type: application/json3Content-Leangth: 1004Date: Mon, 14 Oct 2024 16:35:00 PST5Location: /posting/167{8"id": 1,9"Title": "오늘도 즐거운 날입니다.",10"Contents": "재미있는 글 보고 가세요~"11}
POST 메서드가 범용성이 넓은 메서드라고는 하나,
- 많은 경우 ‘클라이언트가 서버에 새로운 자원을 생성하고자 할 떄’ 사용된다.
- 그리고 만약 성공적으로 POST 요청이 처리되어 새로운 자원이 생성되면,
- 서버는 응답 메시지의 Location 헤더를 통해 새로 생성된 자원의 위치를 클라이언트에게 알려줄 수 있다.
- 위 응답 메시지의 5번째 줄(Location)을 보면, 새로 생성된 자원은
/posting/1에서 확인할 수 있다는 의미다. - Location 헤더는 다음 절에서 한 번 더 다룬다.
2.3.4 PUT - 덮어써 주세요
PUT 메서드는 쉽게 말해서, ‘덮어쓰기’를 요청하는 메서드다.
요청 자원이 없다면, 메시지 본문으로 자원을 새롭게 생성하거나,이미 자원이 존재한다면, 메시지 본문으로 자원을 완전히 대체하는 메시드다.
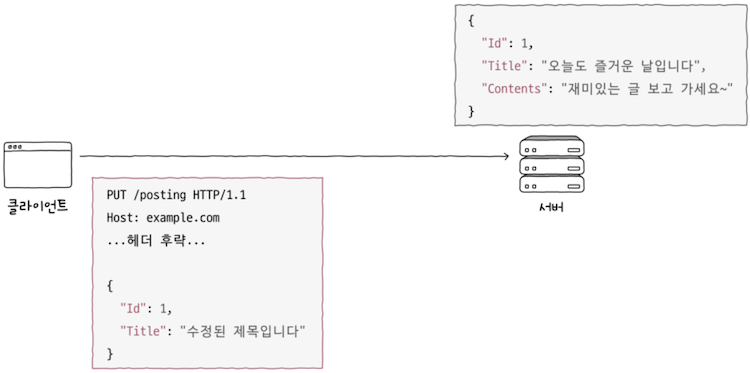
e.g. 위 그림처럼 example.com/posts/1에 우측 상단과 같은 자원이 있다고 가정해보면, (회색 테두리 박스)
- 이에 대해 좌측 하단과 같이 PUT 요청 메시지(붉은색 테두리 박스)를 보낸다면 어떻게 될까?

PUT 요청은 마치 덮어쓰기와 같다고 했다. 따라서 example.com/posts/1의 자원은 위와 같이 갱신된다.
2.3.5 PATCH - 일부 수정해 주세요
PATCH 메서드는 PUT 메서드와의 차이와 비교하며 이해하는 것이 좋다.
PUT 메서드가 덮어쓰기, 완전한 대체에 가깝다면,PATCH 메서드는 부분적 수정에 가깝다.

바로 위 예제에서의 요청 메서드를 PATCH 메서드로 바꿔 보낸 결과는 위와 같다.
- PUT 메서드로 요청을 보냈을 경우, 메시지 본문으로 덮어써졌지만,
- PATCH 메서드로 요청을 보낼 경우, 메시지 본문에 맞게 자원이 일부 수정되는 것을 볼 수 있다.
2.3.6 DELETE - 삭제해 주세요
DELETE 메서드는 특정 자원을 삭제하고 싶을 떄 사용하는 메서드다.
- 다음 예시는
example.com/texts/a.txt라는 자원을 삭제하도록 요청하는 메시지다.
1DELETE /texts/a.txt HTTP/1.12Host: example.com
지금까지 대표적인 HTTP 메서드를 알아봤다. 마지막으로 서버를 개발하는 개발자 입장에서 생각해보자.
- 어떤 URI(URL)에 어떤 메서드로 요청을 받았을 떄,
- 서버가 어떻게 행동해야 하는지 설계하는 것은 오로지 개발자 몫이다.
- 어떤 메서드는 구현할 수도 있고, 어떤 메서드는 구현하지 않을 수도 있다.

같은 URL에 대한 요청일지라도 사용된 메서드가 다르면,
- 각기 다른 요청으로 간주하기 때문에,
- 때로는 같은 URL에 대해 메서드별 동작을 여러 개 구현할 수도 있다.
‘어떤 URL로 어떤 요청을 받았을 떄, 서버는 어떻게 응답할 것인가?’는 서버를 개바라는 개발자들의 주된 고민이다.
- 이를 가장 잘 보여주는 문서가 바로
API 문서다.
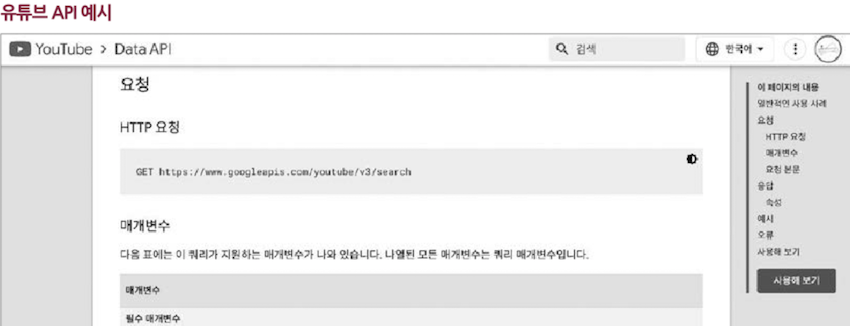
위 예시는 유튜브와 관련된 API다.
- 어떤 URL에 어떤 메서드를 보낼 수 있는지,
- 어떤 쿼리 문자열(매개변수)이 사용될 수 있는지,
- 올바르게 요청을 보냈을 경우 어떤 응답 메시지를 받을 수 있는지,
- 그리고 올바르지 않은 요청을 보냈을 경우 어떤 오류 메시지를 받을 수 있는지가 명시되어 있다.
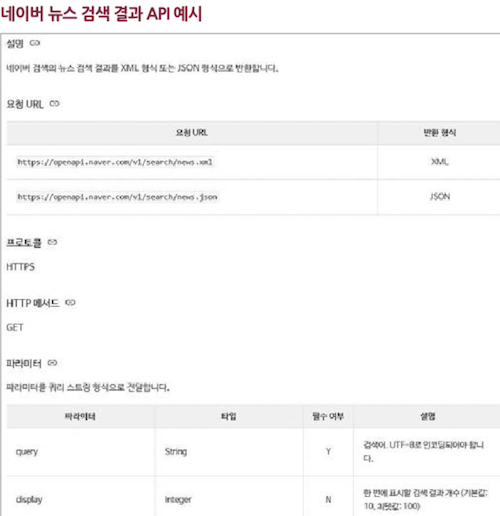
또 다른 예시로, 네이버의 뉴스 검색 결과를 확인할 수 있는 API 예시다.
- 이 또한 어떤 URL에 어떤 메서드를 보낼 수 있는지,
- 어떤 쿼리 문자열(매개변수)이 사용될 수 있는지,
- 어떤 응답 메시지를 받을 수 있는지가 명시되어 있다.
2.4 HTTP 상태 코드
| 상태 코드 | 설명 |
|---|---|
| 100번대(100~199) | 정보성 상태 코드 |
| 200번대(200~299) | 성공 상태 코드 |
| 300번대(300~399) | 리다이렉션 상태 코드 |
| 400번대(400~499) | 클라이언트 에러 상태 코드 |
| 500번대(500~599) | 서버 에러 상태 코드 |
상태 코드는 요청에 대한 결과를 나타내는 3자리 정수다.
- 상태 코드는 백의 자리 수를 기준으로 유형을 구분할 수 있다.
- 즉, 100번대 상태 코드, 200번대 상태 코드, 300번대 상태 코드처럼,
- 유사한 상태 코드는 같은 백의 자리 수를 공유한다.
이러한 상태 코드 중에서 주로 사용되는 200번대 상태 코드부터 500번대 상태 코드까지를 더 자세히 보자.
2.4.1 200번대: 성공 상태 코드
200번대 상태 코드는 ‘요청이 성공했음’을 의미한다. 주로 사용되는 상태 코드는 다음 표와 같다.
| 상태 코드 | 이유 구문 | 설명 |
|---|---|---|
| 200 | OK | 요청이 성공했음 |
| 201 | Created | 요청이 성공했으며, 새로운 자원이 생성되었음 |
| 202 | Accepted | 요청을 잘 받았으나, 아직 요청한 작업을 끝내지 않았음 |
| 204 | No Content | 요청이 성공했지만, 메시지 본문으로 표시할 데이터가 없음 |
e.g. 클라이언트가 http://example.com/images/a.png로 GET 요청을 보냈다고 가정해보면,
- 서버가 이 요청을 성공적으로 받아들이고 처리한 경우,
- 서버는 요청한 자원과 함께 상태 코드 200(OK)을 포함한 응답을 할 수 있다.

또한, 만약 POST 요청을 통해 서버에 새로운 자원을 생성한 경우,
상태 코드 201(Created)로 요청이 성공했으며, 새로운 자원이 만들어졌음을 알릴 수 있다.- 이 경우
Location 헤더를 통해 생성된 자원의 위치를 명시할 수 있다.

202(Accepted)는 요청을 잘 받았으나, 아직 요청한 작업을 끝내지 않았음을 의미한다.
- 작업 시간이 긴 대용량 파일 업로드 작업이나 배치 작업과 같이 요청 결과를 곧바로 응답하기 어려운 상황이 있다.
- 이 경우 서버는
202(Accepted)로 응답할 수 있다.
그리고 요청 메시지에 대해 성공적으로 작업을 완료했더라도, 마땅히 메시지 본문으로 표기할 것이 없을 경우,
- 서버는 상태 코드
204(Not Content)로 응답할 수 있다.
2.4.2 300번대: 리다이렉션 상태 코드
300번대 상태 코드는 라이이렉션(redirection)과 관련된 상태코드다.
💡 리다이렉션이란?
- 인터넷 공식문서(RFC 9110)에서는 이를 ‘요청을 완수하기 위해 추가적인 조치가 필요한 상태’ 정의한다.
- 이름을 풀이해보면,
다시(re) 향하다(direct)라는 뜻이다.- 즉,
리다이렉션은 클라이언트가 요청한 자원이 다른 곳에 있을 떄,
- 클라이언트의 요청을 다른 곳으로 이동시키는 것을 의미한다.
클라이언트가 요청한 자원이 다른 URL에 있을 경우,
서버는 응답 메시지의 Location 헤더를 통해, 요청한 자원이 위치한 URL을 안내해줄 수 있다.- 이를 수신한
클라이언트는 Location 헤더에 명시된 URL로 즉시 재요청을 보내, 새 URL에 대한 응답을 받게된다.
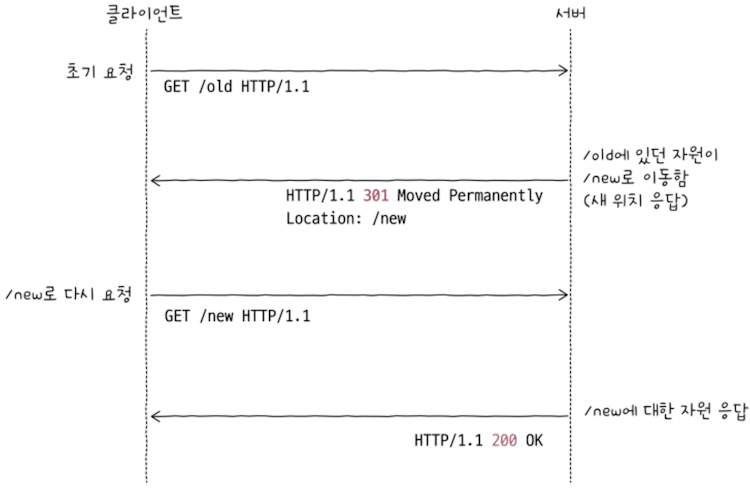
위 그림은 이와 관련된 예시로, http://example.com/old로 GET 요청을 보낸 호스트가 http://example.com/new로 리다이렉트되는 상황을 나타낸다. 상태 코드 200(OK)도 확인할 수 있다.
리다이렉션의 유형은 크게 영구적인 리다이렉션과 일시적인 리다이렉션으로 구분된다.
2.4.2.1 영구적인 리다이렉션
영구적인 리다이렉션(permanent redirection)은 자원이 완전히 새로운 곳으로 이동하여 경로가 영구적으로 재지정되는 것을 의미한다.- 따라서 이 경우 기존 URL에 요청 메시지를 보내면, 항상 새로운 URL로 리다이렉트된다.
- 서버가 도메인을 이전하는 등 웹 사이트의 큰 개편이 있을 떄, 이런 영구적인 리다이렉션을 접할 수 있다.
영구적인 리다이렉션과 관련한 상태 코드로는301과308이 있다.
| 상태 코드 | 이유 구문 | 설명 |
|---|---|---|
| 301 | Moved Permanently | 영구적 리다이렉션; 재요청 메서드 변경될 수 있음 |
| 308 | Permanent Redirect | 영구적 리다이렉션; 재요청 메서드 변경되지 않음 |
상태 코드 301과 308의 차이점은 ‘클라이언트의 재요청 메서드 변경 여부’에 있다.
e.g. 클라이언트가 서버에 GET 요청 메시지를 보낸 뒤, 301 혹은 308 응답 메시지를 받았고,
응답 메시지의 Location 헤더에 명시된 경로로 재요청을 보내야 한다고 가정해보면,
- 이 경우
클라이언트가 보내는 2번쨰 요청 메서드는 1번쨰 요청 메서드와 동일하게GET이다.
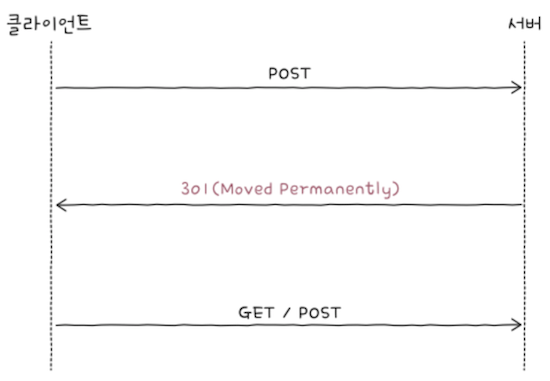
이번에는 클라이언트가 서버에 POST 메서드와 같이 GET 메서드가 아닌 요청 메시지를 보냈고, 301 응답 메시지를 받았다고 해보면,
- 이 경우 클라이언트가 보내는 2번쨰 요청 메서드는 위 그림처럼 GET 요청으로 바뀔 ‘수도’ 있다.
- 다소 엄밀하지 못한 표현에 당황할 수도 있겠지만,
- 공식문서에서도 이 부분은 ‘MAY change the request method(요청 메서드가 바뀔 수도 있다)’라고 정의한다.
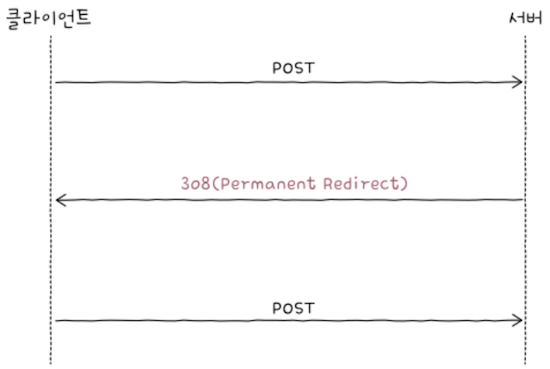
이런 애매함으로 인해 등장한 상태 코드가 308이다.
클라이언트가308 메시지 응답 메시지를 받을 경우, 2번쨰 요청 메서드는 변하지 않는다.- 즉, 위 그림과 같이
1번 요청에서POST 메서드를 사용했다면,상태 코드 308을 받은 뒤 보내는2번 요청에서도POST 메서드를 유지하게 된다.
2.4.2.2 일시적인 리다이렉션
이제 일시적인 리다이렉션(temporary redirection)을 알아보자.
- 앞서 학습한
영구적인 리다이렉션은 자원의 위치가 영구적으로 변경되었음을 시사한다. - 그렇기에 만약 어떤 URL에 요청을 보낸 결과로
영구적인 리다이렉션관련 상태 코드를 응답받았다면,- 요청을 보낸 URL은 기억할 필요가 없다고 봐도 된다.
- 앞으로는 새로운 URL로 요청을 보내면 되기 때문이다.
반면, 일시적인 리다이렉션은 자원의 위치가 임시로 변경되었거나, 임시로 사용할 URL이 필요한 경우 주로 사용한다.
- 따라서 어떤 URL에 대해 일시적인 리다이렉션 관련 상태 코드를 응답받았다면,
- 여전히 요청을 보낸 URL을 기억해야 한다.
- 일시적인 리다이렉션과 관련한 상태 코드는
302,303,307이 있다.
| 상태 코드 | 이유 구문 | 설명 |
|---|---|---|
| 302 | Found | 일시적 리다이렉션; 재요청 메서드 변경될 수 있음 |
| 303 | See Other | 일시적 리다이렉션; 재요청 메서드 GET으로 변경 |
| 307 | Temporary Redirect | 일시적 리다이렉션; 재요청 메서드 변경되지 않음 |
상태 코드 302는 상태 코드 301과 유사하다.
301이 ‘요청한 자원이 완전히 다른 곳으로 이동했음’을 나타낸다면,302는 ‘요청한 자원이 임시로 다른 곳으로 이동했음’을 나타낸다는 정도의 차이가 있다.
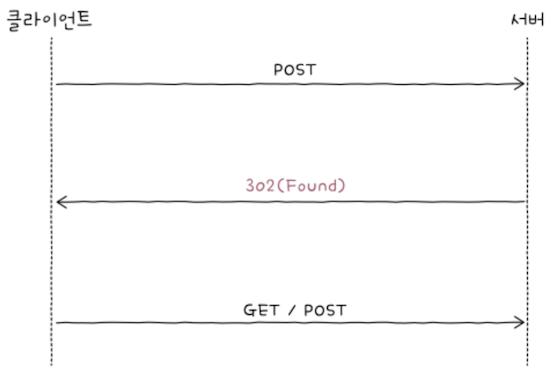
앞서 GET이 아닌 요청 메서드를 사용한 클라이언트가 상태 코드 301을 응답받을 경우,
2번째 요청 메서드가GET으로 바뀔 ‘수도’ 있다고 했다.상태 코드 302도 마찬가지다.
GET이 아닌 요청 메서드를 사용한 클라이언트가상태 코드 302를 응답받을 경우,2번쨰 요청 메서드는GET으로 바뀔 ‘수도’ 있다.
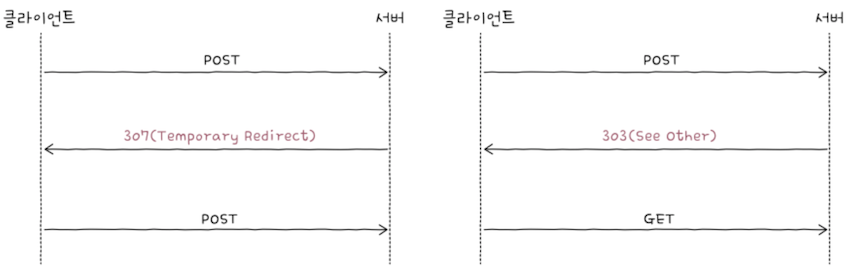
상태 코드 301의 애매모호함을 해결하기 위한 상태 코드가 308인 것처럼,
302의 애매모호함을 해결하기 위한 상태 코드는307이다.307은 2번쨰 요청 메서드를 변경하지 않는 상태 코드다.
e.g. POST 요청을 보낸 클라이언트가 307을 응답받을 경우,
2번쨰 요청 메서드도POST로 유지된다.- 한편으로,
2번쨰 요청 메서드를 반드시 유지하는상태 코드 307과 달리,상태 코드 303은2번쨰 요청 메서드를GET으로 바꿔 주기 위해 사용된다.
요컨대, 만일 클라이언트가 POST 요청 메시지를 보내고,
- 302 응답을 받았다면 2번쨰 요청 메서드는 GET으로 변경될 수 있다.
- 또
클라이언트가POST 요청 메시지를 보내고,303응답을 받았다면,- 2번쨰 요청 메서드는
GET으로 변경된다.
- 2번쨰 요청 메서드는
- 그러나
클라이언트가POST 요청 메시지를 보내고,307응답을 받았다면,- 2번쨰 요청 메서드는 변경없이
POST메서드로 유지된다.
- 2번쨰 요청 메서드는 변경없이
앞에서 리다이렉션이란 **클라이언트가 요청한 자원이 ‘다른 곳’**에 있을 떄,
- 클라이언트의 요청을 ‘다른 곳’으로 이동시키는 것이라고 했다.
- 여기서 말하는 ‘다른 곳’은 다른 URL이 될 수도 있고, 다음 절에서 학습할 캐시가 될 수도 있다.
- 지금까지의 설명은 URL와 관련한 설명이었다.
- 다시 말해,
클라이언트가 요청한 자원이 다른 URL에 있을 떄,클라이언트의 요청을 해당 URL로 이동시키는 상태 코드를 설명했다.
- 다음 절에서는 캐시와 관련된 상태 코드인
304를 학습할 예정이다.- 지금은
304는 ‘자원이 변경되지 않았음’을 의미하는 상태 코드이며, - 캐시와 관련된 상태 코드라는 정도로 알아두면 된다.
- 지금은
2.4.3 400번대: 클라이언트 에러 상태 코드
400번대 상태 코드는 ‘클라이언트에 의한 에러가 있음’을 알려주는 상태 코드다.
- 서버가 처리할 수 없는 형태로 요청을 보냈거나, 존재하지 않는 자원에 대해 요청을 보내는 경우가 이런 경우에 속한다.
- 404(Not Found)가 바로 400번대 코드, 즉 클라이언트 에러 상태 코드의 일종이다.
그럼 400번대 상태 코드의 대표 유형을 알아보자.
| 상태 코드 | 이유 구문 | 설명 |
|---|---|---|
| 400 | Bad Request | 클라이언트의 요청이 잘못되었음 |
| 401 | Unauthorized | 요청한 자원에 대한 유효한 인증이 없음 |
| 403 | Forbidden | 요청이 서버에 의해 거부됨(e.g. 접근 권한이 없을 경우) |
| 404 | Not Found | 요청받은 자원을 찾을 수 없음 |
| 405 | Method Not Allowed | 요청한 메서드를 지원하지 않음 |
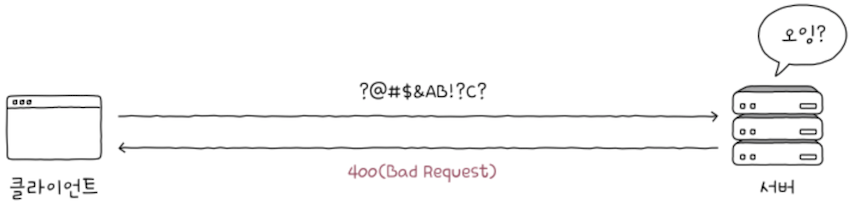
상태 코드 400은 클라이언트가 잘못되었음을 알려주는 상태 코드다.
클라이언트 요청 메시지의 내용이나 형식 자체에 문제가 있어,서버가 요청 메시지를 올바르게 처리할 수 없는 경우가 이런 상황에 속한다.

웹 상에서 정보를 검색할 떄, 모든 자원에 접근이 가능한 것은 아니다.
- 때로는 특정 자원에 접근하기 위해 인증이 필요할 떄가 있다.
- 요청에 대한 인증이 필요한 경우,
서버는401상태 코드를 응답할 수 있다.
서버가 상태 코드 401로 응답할 때는 한 가지 특징이 있습니다.
WWW-Authenticate라는 헤더를 통해 인증 방법을 알려줘야 한다는 점이다.- WWW-Authenticate 헤더는 다음 절에서 자세히 알아보자.
만약 클라이언트의 권한이 충분하지 않다면, 상태 코드 403을 응답한다.
- 즉,
상태 코드 403은 ‘자원에 접근할 권한이 없음’을 의미한다.
상태 코드 401과 403을 혼동하기 쉬운데,
인증(Authentication)여부와권한 부여(Authorization)여부는 다른 개념이다.인증이란 ‘자신이 누구인지 증명하는 것’을 의미하고,권한 부여(다른말로 인가)는 ‘인증된 주체에게 작업을 허용하는 것’을 의미한다.- 인증이 되었더라도, 권한이 충분하지 않을 수 있다.
- e.g. “당신은 일반 사용자입니다. 이 페이지는 관리자만 접속 가능합니다.”
인증과권한 부여/인가는 개발할 떄 자주 등장하는 용어이니, 개념과 차이를 꼭 이해하자.
상태 코드 404는 접근하고자 하는 자원이 존재하지 않음을 알리는 상태 코드다.
- 존재하더라도 공개하지 않은 자원에 대해 404를 응답하는 경우도 있다.
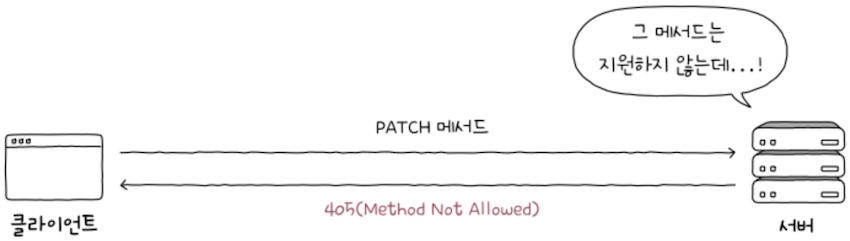
앞서 말한 것처럼 어떤 URI(URL)에 어떤 메서드로 요청을 받았을 떄,
- 서버가 어떻게 행동(응답)해야 하는지 설계하는 것은 오로지 개발자의 몫이므로,
- 일부 메서드는 구현되어 있지 않을 수도 있다.
- 구현되지 않은 메서드로 요청을 보낸다면,
상태 코드 405를 통해 해당 메서드의 미지원을 알릴 수 있다.
2.4.4 500번대: 서버 에러 상태 코드
400번대 상태 코드의 원인이 클라이언트라면, 500번대 상태 코드 원인은 서버다.
- 즉, 500번대 오류는 클라이언트가 올바르게 요청을 보냈을지라도 발생할 수 있는 서버 에러에 대한 상태 코드다.
- 대표적인 500번대 상태 코드들을 알아보자.
| 상태 코드 | 이유 구문 | 설명 |
|---|---|---|
| 500 | Internal Server Error | 요청을 처리할 수 없음 |
| 502 | Bad Gateway | 중간 서버의 통신 오류 |
| 503 | Service Unavailable | 현재는 요청을 처리할 수 없으나, 추후 가능할 수도 있음 |
500번대 상태 코드 중에서 자주 사용되는 상태 코드는 500이다.
- 이는 ‘서버의 예기치 못한 상황으로 인해 요청을 처리할 수 없음’이라는 의미다.
- 다소 포괄적인 표현인 것처럼,
500은 서버 내 에러를 통칭한다.
502(Bad Gateway)는 클라이언트와 서버 사이에 위치한 중간 서버의 통신 오류를 나타내는 상태코드다.
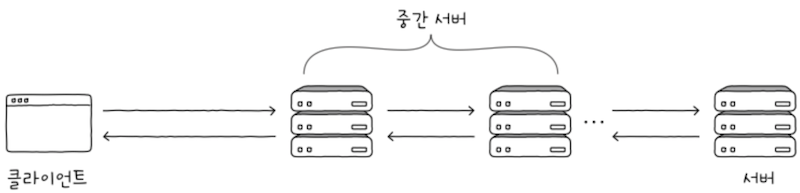
클라이언트와 서버는 일반적으로 일대일로 연결되어 통신하지 않는다.
- 클라이언트와 서버 사이에는 게이트웨이를 비롯한 여러 중간 서버가 존재할 수 있다.
- 클라이언트와 서버가 요청과 응답을 주고받는 과정에서 중간에 위치한 수많은 서버들도 요청과 응답을 주고받는다.
게이트웨이를 비롯한 중간 서버와 관련된 자세한 설명은 07-1 좀더 알아보기를 참조
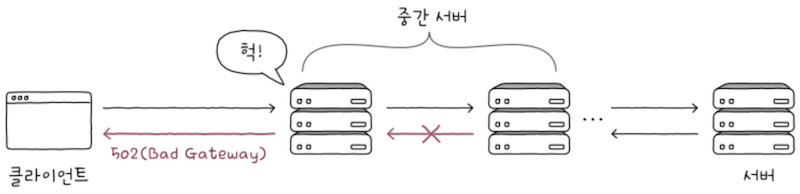
이떄,클라이언트와 서버 사이에 위치한 중간 서버가 위 그림처럼 유효하지 않거나 잘못된 응답을 받을 수도 있다.
- 이럴 떄
상태 코드 502를 응답한다.
마지막으로 상태 코드 503은 ‘현재 서비스를 일시적으로 이용할 수 없음’을 의미하는 상태 코드다.
- 서버가 과부하 상태 있거나 일시적인 점검 상태일 떄, 볼 수 있는 상태 코드다.
여기까지 HTTP의 특성과 메시지 구조, 그리고 요청 메시지의 메서드와 응답 메시지의 상태 코드에 대해 알아봤다.
2.4.5 HTTP의 발전: HTTP/0.9에서 HTTP/3.0까지
HTTP는 오늘날 인터넷이 지탱하는 프로토콜이 되기까지 많은 진화를 거쳐왔다.
- HTTP의 초기 단계인 HTTP 버전 0.9부터 비교적 최근에 등장한 HTTP 버전 3.0까지,
- 단계별로 어떤 주요 변화가 있었고, 각 버전에는 어떤 특성이 있었는지 간략하게 알아보자.
(1) HTTP/0.9
HTTP/0.9는 지금은 거의 사용되지 않는 초창기 HTTP 버전이다.
- 사용 가능한 메서드가 GET뿐이었고, 요청 메시지는 한 줄로 구성되어 있다.
- 헤더가 지원되지 않았기에, 오늘날의 HTTP에 비하면 기능과 성능 면에서 아주 제한적이다.
(2) HTTP/1.0
HTTP/1.0에서는 HEAD, POST와 같은 GET 이외의 메서드가 도입되었고,
- 헤더가 지원되기 시작해 훨씬 더 다양한 정보를 주고받을 수 있게 되었다.
- 그러나 여전히 공식적으로는
지속 연결(persistent connection)을 지원하지 않았다. - 다시 말해, HTTP 메시지를 주고받을 떄마다 연결을 수립하고 종료하기를 반복했다.
(3) HTTP/1.1
HTTP/1.1부터 지속 연결이 공식적으로 지원되었다.
- 또한 특정 요청에 대한 응답이 수신되기 전에 다음 요청을 보낼 수 있는
파이프라이닝 기능과 - 다음 절에서 학습할 콘텐츠 협상 기능 등 다양한
편의 기능 및 사용 가능한 헤더가 추가되었다. - 오늘날까지 널리 사용되는 버전이다.
(4) HTTP/2.0

HTTP/2.0은 HTTP/1.1의 효율과 성능을 높이기 위한 버전이다.
- 달리 말하자면, HTTP/1.1을 보완하고 개선하기 위한 버전으로 볼 수 있다.
- HTTP/2.0에서는 송수신 효율을 높이기 위해 헤더를 압축하여 전송하고,
- (텍스트 기반의 메시지를 송수신한 이전 버전과는 달리) 바이너리 데이터 기반의 메시지를 송수신한다.
- 또 클라이언트가 요청하지 않았더라도,
- 미래에 필요할 것으로 예상되는 자원을 미리 전송해주는
서버 푸시(server push)라는 기능을 제공하기도 한다.
- 미래에 필요할 것으로 예상되는 자원을 미리 전송해주는
그리고 HTTP/2.0은 HTTP/1.1까지의 고질적 문제였던 HOL 블로킹(Head-Of-Line blocking)이라는 문제를 완화한 버전이기도 하다.
💡 “HOL 블로킹”이란
- ‘같은 큐에 대기하여 순차적으로 처리하는 여러 패킷이 있을 떄,
- 첫 번째 패킷의 처리 지연으로 인해, 나머지 패킷들의 처리도 모두 지연되는 문제 상황’을 의미한다.
- cf. 여기서
큐(queue)는 한 줄로 저장된 값이 저장된 순서대로 처리되는 일종의 대기열이다.
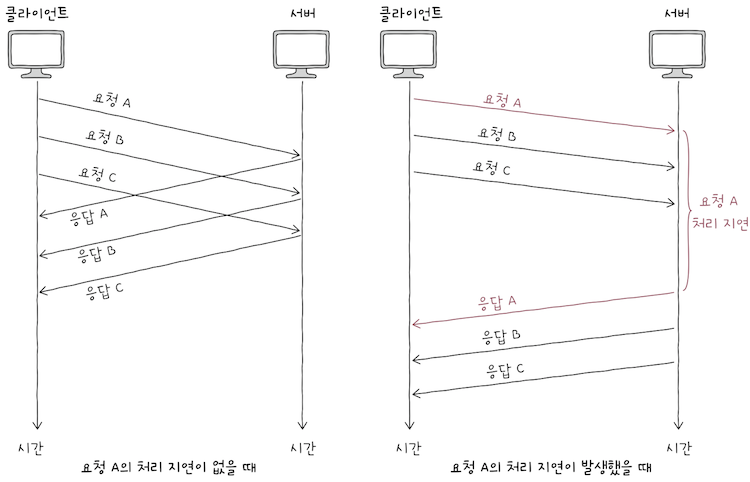
HTTP에서 발생하는 HOL 블로킹 양상은 위 그림과 같다.
- 위 그림을 보면, 알 수 있듯이, 서버가 요청 B, C를 빠르게 처리할 수 있더라도,
- 요청 A의 처리가 지연되면, 요청 B, C의 처리 속도도 지연된다.
HTTP/2.0에서는 이를 멀티플렉싱(multiplexing) 기법을 도입해 완화했다.
HTTP 멀리플릭셍이란? 여러 스트림(stream)을 이용해 병렬적으로 메시지를 주고받는 기술을 의미한다.- 요청과 응답을 주고받는 단위는
하나의 스트림에서 이루어지고,- 이런 스트림을 여러 개 활용하는 동시에
스트림(stream)별로 독립적인 송수신이 가능하며, 스트림별 메시지들은 꼭 일정한 순서를 유지할 필요가 없다.
- 이런 스트림을 여러 개 활용하는 동시에
별도의 스트림을 통해 여러 데이터를 병렬적으로 주고받는다면, HOL 블로킹은 상당 부분 완화할 수 있다.
(5) HTTP/3.0
지금까지 언급한 HTTP 버전들은 모두 TCP를 기반으로 동작한다.
하지만 HTTP/3.0은 이전까지의 HTTP 버전과는 달리 UDP를 기반으로 동작한다.
- 정확히는, UDP를 기반으로 구현된
QUIC(Quick UDP Internet Connection)프로토콜을 기반으로 동작한다. - 연결형 프로토콜인 TCP에 비해 비연결형 프로토콜인 UDP는 상대적으로 더 빠르기 때문에,
- HTTP/3.0은 속도 측면에서 큰 개선이 이루어졌다.
- HTTP/3.0은 현재 빠르게 성장하는 프로토콜로, 이에 따라 QUIC의 중요성도 점차 커지고 있다.
3. HTTP 헤더와 HTTP 기반 기술
지난 절에서는 HTTP의 특징과 메시지 구조,
그리고 HTTP 메시지의 첫 번쨰 줄인 시작 라인, 메서드, 상태 코드에 대해 배웠다.
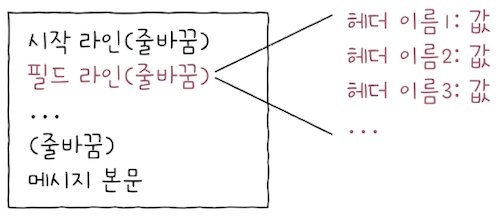
이번 절에는 두 번쨰 줄인 필드 라인을 학습한다.
- 앞서 언급했듯,
필드 라인에는 위 그림과 같은 형식을 따르는 다양한 HTTP 헤더들이 명시된다. HTTP 헤더는필드 이름(헤더 이름)과필드 값(헤더 값)이콜론(:)을 기준으로 구분되어 있다.
HTTP의 중요 헤더 중에서는 특별한 사전 지식이 필요하지 않은 헤더가 있고, 사전 지식이 필요한 헤더가 있다.
- e.g. 캐시, 쿠키, 콘텐츠 협상 관련 헤더를 이해하려면, 먼저 캐시, 쿠키, 콘텐츠 협상이 무엇인지 이해해야 한다.
- 우선 중요하지만 별도 사전 지식없이도 이해할 수 있는 HTTP 헤더들을 살펴보고,
- 그 뒤에 사전 지식이 필요한 HTTP 헤더들을 학습한다.
3.1 HTTP 헤더
HTTP 헤더의 종류는 매우 많기 때문에, 자주 활용되는 중요한 HTTP 헤더 위주로 학습해본다.
- HTTP 요청 시 주로 사용되는 헤더, HTTP 응답 시 주로 사용되는 헤더,
- 그리고 HTTP 요청과 응답 모두에서 자주 활용되는 헤더 순으로 설명한다.
3.1.1 요청 시 활용되는 HTTP 헤더
HTTP 요청 시 주로 활용되는 대표 헤더인 ‘Host’, ‘User-Agent’, ‘Referer’, ‘Authorization’ 헤더에 대해 알아보자.
(1) Host
Host는 요청을 보낼 호스트를 나타내는 헤더이다.
- 주로 도메인 네임으로 명시되며, 포트 번호가 포함되어 있을 수 있다.
다음은 http://info.com/ch/hypertext/WWW/TheProject.html에 접속할 때의 HTTP 요청 메시지 일부다.
1GET /hypertext/WWW/TheProject.html HTTP/1.12Host: info.cern.ch3...
(2) User-Agent
User-Agent는 Host 헤더와 더불어 HTTP 요청 메시지에서 가장 흔히 볼 수 있는 헤더 중 하나다.
유저 에이전트(user agent)란 웹 브라우저와 같이 HTTP 요청을 시작하는 클라이언트 측의 프로그램을 의미한다.- User-Agent 헤더에는 이러한 정보,
- 즉 요청 메시지 생성에 관여한 클라이언트 프로그램과 관련된 다양한 정보가 명시된다.

위 그림을 보면,
- 운영체제, 브라우저 종류 및 버전, 렌더링 엔진과 같은 다양한 정보가 User-Agent 헤더에 포함되어 있음을 알 수 있다.
- 서버 입장에서는 User-Agent 헤더를 통해 클라이언트의 접속 환경을 유추할 수 있다.
💡 User-Agent 헤더에 명시되는 값은 다양하고 복잡하기에, 처음부터 명시될 수 있는 모든 값을 암기할 필요는 없다.
(3) Referer
Referer는 개발 시 아주 중요한 헤더 중 하나다.
- 이 헤더에는 클라이언트가 요청을 보낼 떄 머무르고 있던 URL이 명시된다.
- 다음 예시 헤더는 클라이언트가
https://en.wikipedia.org에서 요청을 보냈음을 의미한다. - Referer를 통해 클라이언트의 유입 경로를 파악해 볼 수 있다.
1Referer: https://en.wikipedia.org/
cf. 영문법적으로는 Referer가 맞지만, 초기 개발 당시의 오타로 인해 Referer라는 표기가 오늘날까지 사용되고 있다. Referer라는 표기를 보고 혼란이 없기 바랍니다.
(4) Authorization
Authorization 헤더는 클라이언트의 인증 정보를 담는 헤더이다.
- 이 헤더는 다음처럼 인증 타입(type)과 인증을 위한 정보(credentials)가 차례로 명시된다.
- 인증 타입에 따라 인증 정보에 명시될 값이 달라진다.
1Authorization: <type> <credentials>
인증 타입의 종류는 다양하지만, 가장 기본적인 HTTP 인증 타입은 Basic이라는 타입이다.
- Basic 타입 인증은
username:password와 같이,- 사용자 아이디(username)와 비밀번호(password)를 콜론을 이용해 합친 뒤,
- 이를 Base64 인코딩한 값을
인증 정보(credential)로 삼는 방식이다.
- 여기서 Base64 인코딩이란? ‘문자를 코드로 변환하는 방법’을 의미하는
인코딩(encoding)방식의 일종이다.
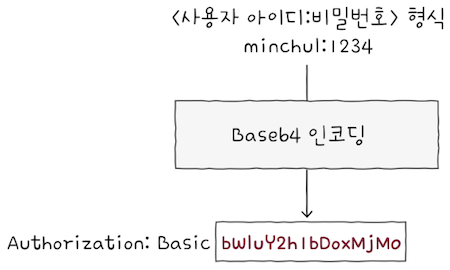
e.g. 사용자 아이디이가 ‘minchul’이고, 비밀번호가 ‘1234’라고 가정해보면,
- ‘minchul:1234’를 Base64 방식으로 인코딩하면, ‘bWluY2h1bDoxMjM0’이 된다.
- 따라서 아이디 ‘minchul’과 비밀번호 ‘1234’를 Basic 타입으로 인증하기 위해 다음과 같은 헤더를 보내면 된다.
1Authorization: Basic bWluY2h1bDoxMjM0
지면상 Base64 인코딩의 원리 관련 설명은 생략하였으나,
- Base64 인코딩에 대해 더 알고 싶으면, 다음 링크의
<encoding>을 참고하기 바란다. - cf. https://github.com/kangtegong/self-learning-cs2/tree/main/encoding
3.1.2 응답 시 활용되는 HTTP 헤더
이번에는 HTTP 응답 시 주로 활용되는 대표적인 헤더는 ‘Server’, ‘Allow’, ‘Retry-After’, ‘Location’. ‘WWW-Authenticate’ 헤더에 대해 알아보자
(1) Server
Server 헤더는 요청을 처리하는 서버 측의 소프트웨어와 관련된 정보를 명시한다. e.g. 다음 예시 헤더는 ‘Unix 운영체제에서 동작하는 아파치 HTTP 서버’를 의미한다.
1Server: Apache/2.4.1 (Unix)
(2) Allow
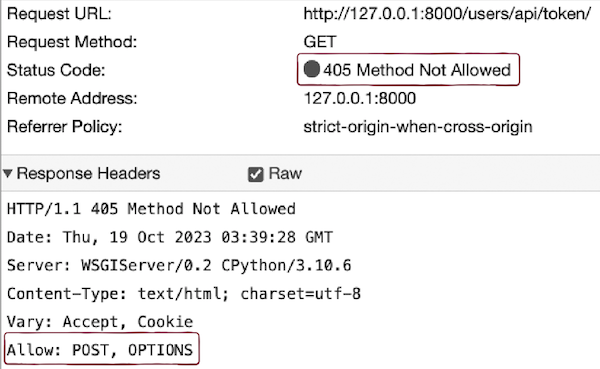
Allow 헤더는 클라이언트에게 허용된 HTTP 메서드 목록을 알려주기 위해 사용된다.
- 앞선 절에서 학습한 상태 코드
405(Method Not Allowed)를 배웠다.- 이는 ‘요청한 메서드를 지원하지 않음’을 의미하는 상태 코드다.
- 상태 코드 405를 응답하는 메시지에서 Allow 헤더가 함께 사용된다.
(3) Retry-After
05-2에서 상태 코드 503(Service Unavailable)도 배웠다.
- ‘현재 요청을 처리할 수 없으나 추후 가능할 수도 있음’을 의미한다.
- 이 응답과 함께 사용될 수 있는 헤더는 Retry-After 헤더이다.
- 이 헤더는 자원을 사용할 수 있는 날짜 혹은 시각을 나타낸다.
다음 예시는 각각 ‘2024년 8월 23일 금요일 9시 이후에 사용 가능하다’라는 사실, ‘120초 이후에 사용가능하다’라는 사실을 나타내는 헤더다.
1Retry-After: Fri, 23 Aug 2024 09:00:00 GMT2Retry-After: 120
(4) Location
Location 헤더는 이전 절에도 언급한 헤더로, 클라이언트에게 자원의 위치를 알려주기 위해 사용되는 헤더다.
- 주로 리다이렉션이 발생했을 떄나 새로운 자원이 생성되었을 떄 사용된다.
(5) WWW-Authenticate
상태 코드 401(Unauthorized)을 배웠다. 이 상태 코드는 요청한 자원에 대한 유효한 인증이 없을 떄 응답하는 코드다.
- 상태 코드 401과 함께 사용되는 헤더가
WWW-Authenticate이다. - WWW-Authenticate 헤더는 자원에 접근하기 위한 인증 방식을 설명하는 헤더다.
- 이를테면 다음과 같이 Basic 인증을 요구할 수 있다.
1WWW-Authenticate: Basic
다만 실제로는 이보다 조금 더 많은 정보를 알려주는 경우가 많다.
- e.g. 다음과 같이 보안 영역(realm)을 함께 알려주거나 인증에 사용될 문자집합(charset)도 알려줄 수 있다.
1WWW-Authenticate: Basic realm="Access to engineering site", charset="UTF-8"
💡 영역(realm)이란?
WWW-Authenticate 헤더에서 ‘realm’은 보안이 적용될 영역을 의미한다.
- 영역이 달리지면, 요구되는 권한도 달라질 수 있다.
- 예컨대 같은 서버가 제공되는 자원일지라도 ‘Engineering site’라는 영역에 속한 자원에 접근 가능한 사용자는 ‘Financial site’라는 영역에 속한 자원에 접근이 불가능할 수 있다.
앞서 Authorization 헤더는 클라이언트가 서버에게 전송하는, 인증 정보를 담는 헤더라고 배웠다.

Authorization과 WWW-Authenticate 헤더를 통해 인증되지 않은 클라이언트가 HTTP 인증(Basic 인증)을 수행하는 과정을 위 그림과 함께 살펴보자.
- 인증되지 않은 클라이언트가 서버에 GET 요청 메시지를 전송한다.
- 서버는 클라이언트에게 상태 코드 401(Unauthorized)과 함께 WWW-Authenticate 헤더를 통해 인증방식을 알린다.
- 클라이언트는 사용자로부터 인증 정보(아이디와 비밀번호)를 전달받는다.
- “아이디:비밀번호”를 Base64 인코딩한 값을 인증 정보로 삼은 Authorization 헤더를 통해 다시 GET 요청 메시지를 전송한다.
- 서버는 인증 정보를 확인한다.
- 인증이 유효하면 상내 코드 200으로 응답하고, 인증되지 않았으면 상태 코드 401로 응답한다.
3.1.3 요청과 응답 모두에서 활용되는 HTTP 헤더
(1) Date
Date는 메시지가 생성된 날짜와 시각에 관련된 정보를 담은 헤더이다.
- 클라이언트와 서버 모두에서 사용될 수 있는 헤더다.
1Date: Tue, 15 Nov 1994 08:12:31 GMT
(2) Connection
Connection 헤더는 클라이언트의 요청과 응답 간의 연결 방식을 설정하는 헤더다.
- 표현이 조금 복잡하지만, 사실 이미 학습한 내용이다.
- HTTP의 특성을 학습할 떄,
HTTP를 지속 연결 프로토콜이라 언급했다. 지속 연결을킵 얼라이브라고도 부른다.
이 지속 연결이 Connection에 명시된 대표적인 연결 방식이다.
- ‘Connection: keep-alive’ 헤더를 통해 상대방에게 지속 연결을 희망함을 알릴 수 있다.
- 또한 서버나 클라이언트가 연결을 종료하고 싶을 떄는 ‘Connection: close’를 통해 알릴 수도 있다.
- Connection 필드에는 다양한 값이 명시될 수 있지만, 가장 대표적인 사용되는 값은 keep-alive와 close다.
1Connection: keep-alive2Connection: close
(3) Content-Length
Content-Length 헤더는 본문의 바이트 단위 크기(길이)를 나타낸다.
1Content-Length: 100
(4) Content-Type, Content-Language, Content-Encoding
이 헤더들은 전송하려는 메시지 본문의 표현 방식을 설명하는 헤더다.
- 이런 점에서 이 헤더들은
표현 헤더(representation header)의 일종이라고도 부른다. - HTTP 요청-응답 메시지를 관찰하다 보면 자주 접할 헤더들이다.
Content-Type 헤더는 메시지 본문에서 사용된 미디어 타입을 담고 있다.
- 미디어 타입은 HTTP의 특성(미디어 독립적 프로토콜)을 설명할 떄 다룬 적이 있다.
- e.g. 다음 헤더는 메시지 본문이 HTML 문서 형식이며, 문자 인코딩으로 UTF-8을 사용한다는 정보를 알려준다.
1Content-Type: text/html; charset=UTF-8
Content-Language 헤더는 메시지 본문에 사용된 자연어를 명시한다.
- 어떤 언어로 작성되었는지 Content-Language를 통해 알 수 있는 셈이다.
- Content-Language의 값은 언어 태그로 명시되며, 언어 태그는 하이픈(-)으로 구분된 다음과 같은 구조를 따른다.
e.g. Content-Language 헤더 값이 en이거나 ko일 경우, 첫 번쨰 서브 태그만 사용된 것이고,
- Content-Language 헤더 값이 en-US, ko-KR일 경우 두 번쨰 서브 태그까지 사용된 것이다.
1<첫 번쨰 서브태그>2<첫 번쨰 서브태그>-<두 번쨰 서브태그>3<첫 번쨰 서브태그>-<두 번쨰 서브태그>-<세 번쨰 서브태그>4...
cf. 두 번쨰 태그보다 더 많은 서브태그도 있을 수도 있지만, 일반적으로 첫 번쨰 서브 태그나 두 번쨰 서브 태그까지만 사용된다.
첫 번째 서브 태그는 언어 코드로, 특정 언어를 의미하는 언어 코드가 명시된다. 주로 사용되는 언어 코드는 다음과 같다.
| 언어 | 언어 코드 |
|---|---|
| 한국어 | ko |
| 영어 | en |
| 중국어 | zh |
| 일본어 | ja |
| 독일어 | de |
| 프랑스어 | fr |
두 번쨰 서브 태그는 국가 코드로, 특정 국가를 의미하는 국가 코드가 명시된다. 다음 표를 참고하자.
| 국가 | 국가 코드 |
|---|---|
| 한국 | KR |
| 미국 | US |
| 영국 | GB |
| 중국 | CN |
| 타이완 | TW |
| 일본 | JP |
| 독일 | DE |
| 프랑스 | FR |
언어 코드와 국가 코드를 조합하면, ‘어떤 국가에서 사용하는 어떤 언어’인지를 알 수 있게 된다.
- 예컨대 ko는 ‘한국어’를 의미하고, ko-KR는 ‘한국에서 사용하는 한국어’라는 의미가 된다.
- 마찬가지로 en은 ‘영어’를 의미하고,
- en-US는 ‘미국에서 사용하는 영어’, en-GB는 ‘영국에서 사용하는 영어’를 의미한다.
💡 국가를 나타내는 서브 태그는 대문자를 사용하는 경우가 많다.
Content-Encoding 헤더에는 메시지 본문을 압축하거나 변환한 방식이 명시된다.
- HTTP를 통해 송수신되는 데이터는 전송 속도를 개선하기 위해 종종 압축이나 변환이 되고는 하는데,
- 이떄 사용된 방식이 Content-Encoding 필드에 명시되는 셈이다.
- 수신 측은 이 헤더를 통해 압축 및 변환 방식을 인식하고,
- 압축을 해제하거나 원문으로 재변환하여 본문 내용을 확인할 수 있게 된다.
- Content-Encoding 헤더에 명시될 수 있는 대표적인 값은 ‘gzip’, ‘compress’, ‘deflate’, ‘br’ 등 이 있다.
- 다만 각 방식에 대한 자세한 내용은 분량상 여기서는 다루지 않는다.
1Content-Encoding: gzip2Content-Encoding: compress3Content-Encoding: deflate4Content-Encoding: br56// 여러 인코딩이 사용되었을 경우: 적용된 순서대로 명시7Content-Encoding: deflate, gzip
3.2 캐시
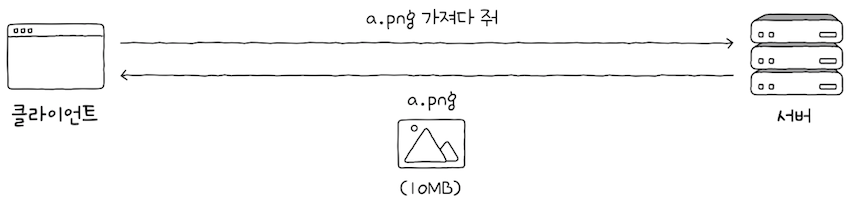
이제 앞서 말했던 대로 HTTP 기반 기술을 설명합니다. 위 그림과 같은 상황을 가정해보면,
클라이언트가 이미지를 조회하기 위해서버를 향해 GET 요청 메시지를 보냈고,- 이에 대한 응답 메시지로 10MB 크기의 이미지가
클라이언트에게 전송된다.
그런데 이떄, 클라이언트가 같은 이미지를 2, 3번 더 요청하면 어떻게 될까?
- 몇 번이고 서버로부터 10MB 크기의 이미지를 응답받을 것 같지만, 그렇지 않다.
- 오늘날 인터넷 환경에서는 HTTP 캐시(혹은 웹 캐시, 이하 캐시)를 활용해 응답받은 내용의 사본을 임시로 저장할 수 있기 때문이다.
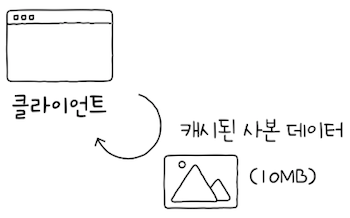
캐시(cache)란 불필요한 대역폭 낭비와 응답 지연을 방지하기 위해 정보의 사본을 임시로 저장하는 기술이다.
- 정보의 사본을 임시로 저장하는 것 자체를
캐시(cache)한다. 캐싱(caching)한다라고도 표현하며, 캐시된 데이터를캐시라 부르기도 한다.- 이렇게 사본을 임시로 저장해두면, 동일한 요청에 대해 캐시된 데이터를 활용할 수 있기 때문에,
- 불필요한 대역폭 낭비를 줄일 수 있고, 더 빠르게 데이터에 접근할 수 있다.
캐시는 웹 브라우저에 저장되어 있기도 하고, 클라이언트와 서버 사이에 위치한 중간 서버에 저장되어 있기도 한다.
- 전자를
개인 전용 캐시(private cache)라 하고, - 후자를
공용 캐시(public cache)라 부른다. - 여기서는 개인 전용 캐시에 초점을 맞춰 이야기한다.
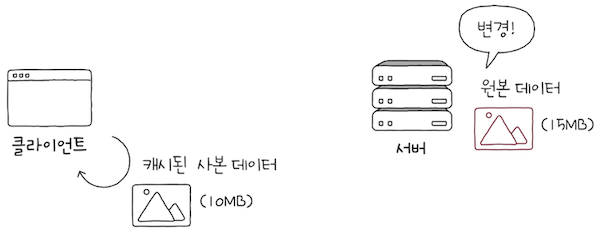
캐시란 원본 데이터의 사본을 임시로 저장하는 기술이라고 했다.
- 여기서 중요한 점은 바로 캐시는 원본이 아닌 ‘사본’을 저장한다는 점이다.
- 따라서 캐시를 했다면 항상 캐시한 이후로 원본 데이터가 변경되는 상황에 대비해야 한다.
- 위 쪽 예시를 다시 보면,
캐시한 a.png라는 데이터는 사본이다.- 언제든지 서버의 원본 데이터가 변경될 수 있다.
- 원본 데이터가 변경되었는데도, 계속해서 캐시된 사본 데이터를 참조하다 보면 문제가 발생할 수 있다.
캐시된 사본 데이터가 얼마나 최신 원본 데이터와 유사한지를 캐시 신선도(cache freshness)라고 표현한다.
- 그렇다면 캐시 신선도는 어떻게 검사할 수 있을까?
- 달리 말해, 클라이언트가 확보한 캐시된 데이터가 최신 상태를 유지할 수 있는지를 어떻게 알 수 있을까?
신선도를 유지하는 가장 기본적인 방법은 ‘캐시된 데이터에 유효 기간을 설정하는 방법’이다.
- 캐시된 데이터를 한 달 뒤, 1년 뒤, 10년 뒤 등 언제까지고 참조할 수 있다면, 자연스레 신선도가 떨어질 것이다.
- 따라서 캐시 데이터에 유효 기간을 설정하고,
- 기간이 만료되었더라면, 원본 데이터를 다시 요청하는 방식으로 캐시 신선도를 유지할 수 있다.
캐시된 데이터에 유효 기간을 부여하는 방법으로
- 응답 메시지의 Expires 헤더(날짜)와 Cache-Control 헤더의 Max-Age 값 (초)을 사용할 수 있다.
- 다음 예시 헤더 속 붉은색 글자를 통해 이해해보면,
- 각각 캐시의 유효 기간을 2024년 2월 6일 화요일 12:00:00로 설정하고,
- 1200초로 설정하는 응답 메시지의 예시다.
응답 메시지
1HTTP/1.1 200 OK2Date: Mon, 05 Feb 2024 12:00:00 GMT3Content-type: text/plain4Content-length: 1005Expires: Tue, 06 Feb 2024 12:00:00 GMT // 캐시의 유효 기간 설정6... 본문 생략 ...
1HTTP/1.1 200 OK2Date: Mon, 05 Feb 2024 12:00:00 GMT3Content-type: text/plain4Content-length: 1005Expires: max-age=1200 // 1200초로 설정6... 본문 생략 ...
클라이언트가 응답받은 자원을 캐시해서 이용하다가 캐시의 유효 기간이 만료되었다고 가정해보면,
- 그러다면
서버에게 자원을 다시 요청해야 한다. - 그런데 만약 캐시의 유효 기간이 만료되었더라도 원본 데이터가 변하지 않았다면,
서버는 굳이 자원을 전송해줄 필요가 없다.- 어차피 같은 자원이
클라이언트에게 캐시되어 있기 때문이다.
- 다시 말해,
캐시가 만료되었더라도 캐시된 자원이 여전히 최신 정보라면,클라이언트는 굳이 서버로부터 같은 자원을 응답받을 필요가 없다.- 캐시된 자원을 (유효 기간을 연장하여) 이용하면 되기 때문이다.
- 하지만 만일
서버의 원본 자원이 변경되었다면,클라이언트는 새로운 자원을 응답받아야 한다.
따라서 캐시의 유효 기간이 만료되었다면,
클라이언트는 캐시된 자원이 여전히 신선한지, 여전히 최신 상태의 정보인지 재검사해야 한다.- 캐시의 신선도를 재검사하는 방법은 크게 2가지 방법이 있다.
- 하나는 ‘날짜를 기반으로 서버에게 물어보는 방법’이고,
- 또 다른 하나는 ‘엔티티 태그를 기반으로 서버에게 물어보는 방법’이다.
날짜를 기반으로 재검사하는 방식을 먼저 살펴보자.
- 클라이언트는
If-Modified-Since 헤더를 통해,- 서버에게 특정 시점 이후로 원본 데이터에 변경이 있었는지 물어볼 수 있다.
If-Modified-Since 헤더의 값으로 특정 시점(날짜와 시각)이 명시되는데,- 이 시점 이후로 원본에 변경이 있었다면, 그때만 새 자원으로 응답하도록 서버에게 요청하는 헤더다.
다음 예시를 통해 이해해보면,
- 해당 요청 메시지는 ‘2024년 8월 23일 금요일 09:00:00 이후에
www.example.com/index.html의 자원이 변경되었니? - 변경이 되었을 경우에만 새 자원으로 응답해줘‘라는 요청 메시지와 같다.
💡 If-Modified-Since 헤더와 유사한 If-Unmodified-Since 헤더도 있다.
요청 메시지
1GET /index.html HTTP/1.12Host: www.example.com3If-Modified-Since: Fri, 23 Aug 2024 09:00:00 GMT
이제 서버 입장에서 생각해보면, 서버가 If-Modified-Since 헤더가 포함된 요청 메시지를 수신했다고 가정해보면, 이떄 서버의 자원은 크게 셋 중 하나의 상황을 따르게 된다.
- 요청받은 자원이 변경되었음
- 요청받은 자원이 변경되지 않았음
- 요청받은 자원이 삭제되었음
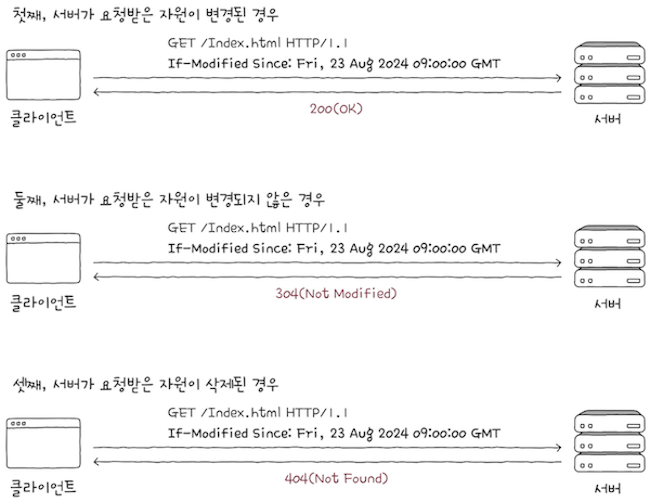
첫째, 요청받은 자원이 변경되었다면, 서버는 상태 코드 200(OK)과 함께 새로운 자원을 반환한다.
둘쨰, 요청받은 자원이 변경되지 않았다면,
서버는 메시지 본문없는 상태 코드 304(Not Modified)를 통해 클라이언트에게 자원이 변경되지 않았음을 알린다.
이 경우 클라이언트는 캐시된 자원을 사용할 수 있다.
셋쨰, 만약 요청받은 자원이 삭제되었다면,
서버는 상태 코드 404(Not Found)를 통해 요청한 자원이 존재하지 않음을 알린다.
05-2에서 300번대 상태 코드를 설명할 떄, 상태 코드 304(Not Modified)는 다음 절에서 설명할 예정이다.
- 여러분이 HTTP 응답 상태 코드 304(Not Modified)를 마주친다면,
- 이는 십중팔구 ‘이미 캐시된 자원이 있으니 캐시된 자원을 참조하세요’라는 응답이다.
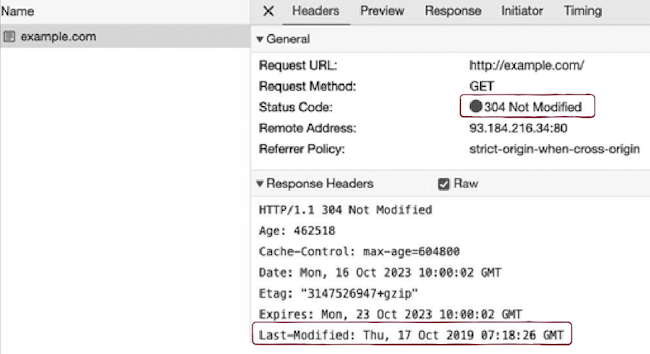
서버는 상태 코드 304(Not Modified)를 통한 자원의 ‘변경 여부’뿐만 아니라,
- **자원의 ‘마지막 변경 시점’**도
클라이언트에게 알려줄 수 있다. - 이를 위한 헤더로
Last-Modified 헤더가 있다. - 즉,
Last-Modified 헤더는 특정 자원이 마지막으로 수정된 시점을 나타낸다. - 위 그림 속
Last-Modified 헤더를 확인해보면,- 응답된 자원이 마지막으로 2019년 10월 17일 목요일 7시 18분 26초에 변경되었음을 나타낸다.
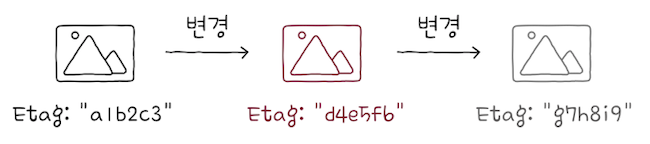
지금까지 날짜를 기반으로 캐시 신선도를 재검사하는 방식을 설명했다면,
이번에는 엔티티 태그(Entity Tag; 이하 Etag)를 사용하는 방법에 대해 알아본다.
Etag는 ‘자원의 버전’을 식별하기 위한 정보다.- 여기서
버전(version)이란 ‘유의미한 변경사항’을 의미한다. - 즉, 자원이 변경될 떄마다 자원의 버전을 식별하는 Etag 값이 변경된다.
- 반대로 자원이 변경되지 않았다면, Etag 값도 변경되지 않는다.
클라이언트가 Etag 값이 부여된 자원을 캐시할 떄,
- 캐시 신선도를 검사하기 위해
서버에게 ‘이 Etag 값과 일치하는 자원이 있니?’와 같이 물어볼 수 있다. - 이를 사용하는 헤더가 바로
If-None-Match다. - e.g. 다음의 요청 메시지는 ‘혹시 Etag 값이 abc인
www.example.com/index.html이라는 자원이 있니?- 이 자원이 변경되었다면(Tag 값이 바뀌었다면) 그때만 새 자원으로 응답해줘’라는 요청 메시지와 같다.
1GET /index.html HTTP/1.12Host: www.example.com3If-None-Match: "abc"
💡 If-None-Match 헤더와 유사한 If-Match 헤더도 있다.
이때도 서버의 자원은 크게 셋 중하나의 상황을 따른다.
- 요청받은 자원이 변경되었음(Etag 값이 변경됨)
- 요청받은 자원이 변경되지 않았음(Etag 값이 동일함)
- 요청받은 자원이 삭제되었음
첫째로, 요청한 자원이 변경되었다면 Etag 값도 변경되었을 것이다. 이 경우 서버는 상태 코드 200(OK)과 함께 변경된 데이터와 Etag 값을 응답한다.
둘쨰로, 요청한 자원이 변경되지 않았다면, Etag 값도 변하지 않는다. 이떄 서버는 메시지 본문 없는 상태 코드 304(Not Modified)를 응답한다.
셋째로, 요청한 자원이 삭제되었다면, 서버는 상태 코드 404(Not Found)를 응답하게 된다.
3.3 쿠키
HTTP은 기본적으로 상태를 유지하는 스테이트리스 프로토콜이다. 그런데 조금 이상하다.
- 만약 HTTP가 스테이트리스 프로토콜이고, 클라이언트의 상태를 유지하지 않는다면,
- 위 그림과 같은 기능은 어떻게 구현될까?
- 분명 이런 기능은 클라이언트의 상태를 알고 있어야만 구현할 수 있는 기능인데 말이죠.
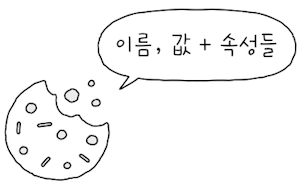
HTTP 쿠키(이하 쿠기)를 통해 이러한 기능을 구현할 수 있다.
쿠키(cookie)란 서버에서 생성되어 클라이언트 측에 저장되는 데이터로,- 상태를 유지하지 않는 HTTP의 특성을 보완하기 수단이다.
서버는 클라이언틔 상태를 알 수 있게끔 하는 특별한 데이터다.- 쿠키를 이루는 정보는 기본적으로
<이름, 값>쌍의 형태를 띠고 있고,- 추가로 적용 범위와 만료 기간 등 다양한 속성을 가질 수 있다.
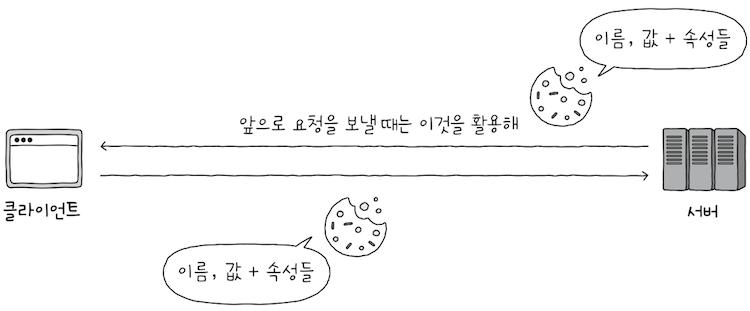
서버는 쿠키를 생성하여 클라이언트에게 전송하고,
클라이언트는 전달받은 쿠키를 저장해 두었다가, 추후 동일한 서버에 보내는 요청 메시지에 쿠키를 포함하여 전송한다.서버는 쿠키 정보를 참고해,- 두 개의 요청이 같은
클라이언트에서 왔는지, 로그인 상태를 유지하고 있는지 등을 알 수 있다.
- 두 개의 요청이 같은
💡세션 인증
HTTP는 스테이트리스 프로토콜이라고 했다.
- 같은
클라이언트가 서버에 여러 번 요청을 보낸다고 해도,- 기본적으로
서버는 모든 요청들을 별개의 요청으로 간주한다.- 그렇다면 클라이언트가 서버에 요청 메시지를 보낼 때마다,
- (아이디, 비밀번호와 같은) 인증정보를 보내고 번거로운 인증 과정을 거쳐야 하는 것일까? 그렇지 않다.
쿠키를 통해 전달되는 대표적인 정보를
세션 아이디(session id)가 있다.
- 세션 아이디가 무엇인지 이해하려면,
세션 인증(session authentication)이 무엇인지 이해해야 한다.세션 인증이란 다음과 같은 순서로 이루어지는 인증 방식을 의미한다.
- 클라이언트는 서버에게 (아이디, 비밀번호와 같은) 인증 정보를 전송한다.
- 인증 정보가 올바르다면, 서버는 세션 아이디를 생성해 클라이언트에게 전송한다.
- 서버는 생성한 세션 아이디를 데이터베이스 등에 저장한다.
- 클라이언트는 추후 요청을 보낼 떄 쿠키 내에 세션 아이디를 포함하여 전송한다.
- 서버는 쿠키 속 세션 아이디와 저장된 세션 아이디를 비교하여 클라이언트를 식별한다.
위와 같이 쿠키를 통해 세션 아이디를 전송하면, 요청을 보낼 떄마다 번거로운 인증 과정을 거칠 필요가 없어 효율적이다.
앞서 언급했듯, 쿠키는 서버가 생성하고, 클라이언트는 서버로부터 전달받은 쿠키를 활용한다.
- 이들은 각각 응답 메시지의 Set-Cookie 헤더와 요청 메시지의 Cookie 헤더를 통해 전달된다.
응답 메시지의 Set-Cookie 헤더를 통해 쿠키의 이름, 값과 더불어 세미클론(;)으로 구분되는 속성들을 전달할 수 있다.
- 한 응답 메시지에 전달할 쿠키가 여러 개라면, 다음과 같이 여러 개의
Set-Cookie를 사용하기도 한다.
응답 메시지
1Set-Cookie: 이름=값2Set-Cookie: 이름=값; 속성13Set-Cookie: 이름=값; 속성1; 속성2
요청 메시지의 Cookie 헤더 값은 서버에 전달할 쿠키의 이름과 값을 나타내는 헤더다. 여러 개의 쿠키값을 서버에 전달할 떄는 다음과 같이 세미콜론(;)을 사용하여 여러 쿠키의 이름-값을 나타낸다.
요청 메시지
1Cookie: 이름=값; 이름=값;
다음 예시 메시지를 보면,
- 첫 번쨰 메시지는 name=“minchul”, phone=“100-100”, message=“Hello”라는 쿠키를 클라이언트에게 전송하는 서버의 응답 메시지 예시다.
- 두 번쨰 메시지는 서버로부터 전달받은 쿠키를 활용하는 클라이언트의 요청 메시지 예시다.
응답 메시지
1HTTP/1.1 200 OK2Content-Type: text/html3Set-Cookie: name=minchul4Set-Cookie: phone=100-1005Set-Cookie: message=Hello6... 헤더 후략7... 메시지 본문 생략
요청 메시지
1GET /next_page HTTP/1.12Host: example.com3Cookie: name=minchul; phone=100-100; message=Hello4... 헤더 후략

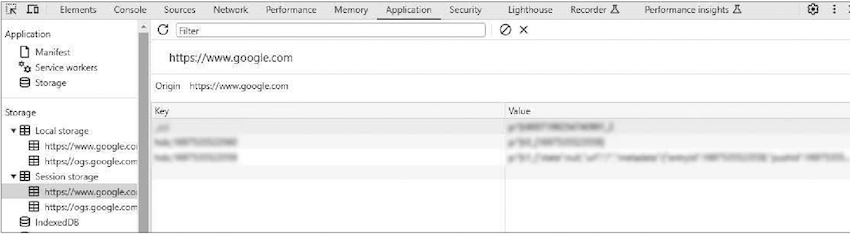
쿠키는 브라우저에서 저장되고 관리된다. 쿠키를 직접 확인해보면,
- 크롬 브라우저에서 개발자 도구를 열고,
[Application] → [Storage] → [Cookie]를 확인해보세요. - 위 화면처럼
쿠키의 이름(name),값(value)목록을 볼 수 있다. - 각각의 행이 쿠키인 셈이다.
- 쿠키 관련 정보로 이름과 값 외에도
도메인(domain)과경로(path)등도 있다.
www.naver.com에게 받은 쿠키를 전혀 다른 웹사이트인 www.google.com에게 전송하면 안되듯이,
쿠키는 사용 가능한 도메인이 정해져 있다.- 이는 응답 메시지 속 Set-Cookie 헤더의 ‘domain’ 속성으로 정해진다.
응답 메시지
1Set-Cookie: name=minchul domain=example.com
또한 같은 도메인이라도 경로별로 쿠키를 구분하여 사용하고 싶을 때가 있을 수 있다.
- e.g.
www.example.com/lectures를 포함한 하위 경로에서 사용하고자 하는 쿠키와 www.naver.com/books를 포함한 하위 경로에서 사용하고자 하는 쿠키가 다를 수 있다.
이럴 때는 다음 예시에서 path=/lectures 부분처럼 “path”로 쿠키가 적용될 경로를 명시하면 된다.
- 그러면 path로 지정된 경로와 그 앞부분이 일치하는 경로(하위 경로)에서 해당 쿠키 정보를 활용할 수 있게 된다.
응답 메시지
1Set-Cookie: name=minchul path=/lectures
다음 예시를 살펴보먄, Expires/Max-Age라는 열도 있다. 이는 쿠키의 유효 기간을 나타낸다.
- 쿠키마다 보통 유효 기간이 정해져 있다.
Expires는 [유효, DD-MM-YY-HH:MM:SS GMT] 형식으로 표기되는 쿠키 만료 시점을 의미하고,Max-Age는 초 단위 유효 기간을 의미한다.- Expires로 명시된 시점이 지나거나, Max-Age로 명시된 유효 기간이 지나면,
- 해당 쿠키는 삭제되어 전달되지 않는다.
응답 메시지
1Set-Cookie: sessionID=abc123; Expires=Fir, 23 Aug 2024 09:00:00 GMT2Set-Cookie: sessionID=abc123; Max-Age=2592000
쿠키를 학습할 떄는 쿠키의 한계도 알아두는 것이 좋다.
쿠키의 대표적인 한계는 바로 보안이다.- 쿠키에 개인 정보를 비롯해 보안에 민감한 정보를 담아 송수신하고 저장하는 것이 바람직하지 않다.
- 쿠키 정보가 쉽게 노출되거나 조작될 수 있기 때문이다.
이를 보완하기 위한 속성으로 Secure와 HttpOnly라는 속성이 있다.
Secure는 HTTPS 프로토콜이 사용되는 경우에만 쿠키를 전송되도록 하는 속성이다.
- 7장에서 학습하지만,
HTTPS 프로토콜은 HTTP를 더 안전한 방식으로 전송할 수 있는 프로토콜이다.
HttpOnly는 HTTP 송수신을 통해서만 쿠키를 이용하도록 제한하는 속성이다.
- 지금까지 설명한 바에 따르면,
쿠키는 HTTP 헤더를 통해 송수신되었다.- 다시 말해,
쿠키와 관련한 데이터는 HTTP 송수신을 통해서만 확인이 가능했다.
- 다시 말해,
- 그런데 사실 쿠키 관련 데이터는 JavaScript를 통해서도 접근이 가능하다.
- 악의적 의도를 가진 해커는 (정상적인 HTTP 송수신을 통해서가 아닌)
- JS로 쿠키를 중간에 가로채거나 위변조할 수 있다.
HttpOnly는 이런 상황을 방지하기 위해 JS에서 쿠키에 접근하지 못하도록 하는 속성이다.- JS에 대해 잘 모르면 ‘HttpOnly는 쿠키의 위변조를 방지하기 위한 속성이다’ 정도로 이해하면 된다.
💡 웹 스토리지: 로컬 스토리지와 세션 스토리지
쿠키는 서버가 생성하고 클라이언트가 저장되는 정보다.
- 이를 통해 클라이언트의 상태를 추측할 수 있다.
- 쿠키 이외에도 클라이언트가 저장하고, 클라이언트의 상태를 추측할 수 있는
<키-값>쌍 형태의 정보가 있다.
- 바로
웹 스토리지(web storage)다.웹 스토리지는 웹 브라우저 내의 저장 공간으로, 일반적으로 쿠키보다 더 큰 데이터를 저장할 수 있다.
- 또
쿠키는 서버로 자동 전송되지만,웹 스토리지의 정보는 서버로 자동 전송되지 않는다. 필요할 떄 조회할 수도 있다.
웹 스토리지에는 크게
로컬 스토리지(local storage)와세션 스토리지(session storage)가 있다.
- 개발자 도구를 열고 [Application] [Storage]를 보면,
로컬 스토리지와세션 스토리지를 확인할 수 있다.세션 스토리지는 세션이 유지되는 동안(쉽게 말해 브라우저가 열려있는 동안) 유지되는 정보고,로컬 스토리지는 별도로 삭제하지 않는 한 영구적으로 저장이 가능한 정보다.
3.4 콘텐츠 협상과 표현
한국에서 접속하거나 한국어 계정으로 특정 URL에 접속하면, 한국어로 된 웹 페이지를 볼 수 있고, 다른 지역에서 접속하거나 영어 계정과 같은 URL에 접속하면 영어로 된 웹 페이지를 볼 수 있다.
조금 이상하지 않나요? 클라이언트가 서버에 자원을 요청하고, 서버는 요청받은 자원을 응답한다고 했다.
- 그리고 자원은 URI를 통해 식별 가능하다고 했다.
- 분명 같은 자원을 요청했는데, 어떻게 다른 결과를 얻는걸까?
이는 HTTP의 콘텐츠 협상(content negotiation)을 통해 이루어진다.
콘텐츠 협상이란, 같은 URI에 대해 가장 적합한 ‘자원의 형태’를 제공하는 메커니즘을 의미한다.- 같은 URI로 식별 가능한 HTML 문서라 해도,
- 영어로 요청하면 영어로 된 형태로 제공하고,
- 한국어로 요청하면 한국어로 된 형태를 제공하는 것이다.
- 이떄, ‘송수신 가능한 자원의 형태’를 자원의
표현(representation)이라고 한다.- 즉,
콘텐츠 협상은 클라이언트에게 가장 적합한 자원의 표현을 제공하는 메커니즘을 의미한다.
- 즉,
표현이 무엇인지 배웠다면, 이를 고려해 앞서 배운 GET 메서드를 조금 더 엄밀하게 정의할 수 있다.
- 이전에는
GET 메서드를 ‘자원을 습득하기 위한 메서드’라 정의했다.- 하지만 이제는 자원에 대한 다양한 표현이 가능하고,
- 클라이언트가 습득하는 것은 다양한 표현 중 하나라는 점을 배웠다.
- 그렇다면
GET 메서드는 ‘자원의 특정 표현을 습득하기 위한 메서드’라 정의할 수 있다.- 실제로 GET 메서드의 공식적인 정의는 다음과 같다.
- requests transfer of a current selected representation for the target resource.
- (대상 자원에 대해 현재 선택된 표현의 전송을 요청한다.)
다시 콘텐츠 협상 이야기로 돌아와보면,
- 자원에 대한 다양한 표현 중 클라이언트가 선호하는 표현을 반영하고자 콘텐츠 협상 관련 HTTP 헤더들이 사용된다.
- 주요 헤더로는 선호하는 미디어 타입을 나타내기 위한
Accept 헤더,- 선호하는 언어를 나타내기 위한
Accept-Language 헤더, - 선호하는 문자 인코딩과 압축 방식을 나타내기 위한
Accept-Charset 및 Accept-Encoding 헤더등이 있다.
- 선호하는 언어를 나타내기 위한
e.g. 클라이언트가 선호하는 언어가 한국어일 경우, Accept-Language: ko를 헤더에 추가해 서버에 요청하면 된다.
- 그러면 서버는 클라이언트가 선호하는 언어를 인식하여 한국어로 표현된 자원을 보내주게 된다.
- 또한 클라이이언트가 HTML 문서 타입을 선호한다면,
- 헤더에
Accept: text/html을 추가해 서버에 요청하면 된다.
- 헤더에
- 다음은 이런 콘텐츠 협상 헤더들을 사용해 서버에 요청을 보낸 예시다.
요청 메시지
1GET /index.html HTTP/1.12Host: example.com3Accept-Language: ko4Accept: text/html
콘텐츠 협상에서 중요한 점은 선호도에 우선순위를 반영할 수 있다는 점이다.
- e.g. 클라이언트가 ‘언어는 한국어를 가장 선호하지만, 영어도 받을 용의가 있다’라는 식으로
- 여러 선호도를 담은 요청 메시지를 보낼 수도 있다.
- 혹은 ‘미디어 타입은 HTML 문서를 가장 선호하지만, XML을 그 다음으로 선호하고,
- 일반 텍스트를 그다음으로 선호한다’라는 식으로 여러 선호도를 담은 요청 메시지를 보낼 수도 있다.
이러한 우선순위는 콘텐츠 협상 관련 헤더의 q 값으로 표현된다.
q는Quality Value의 약자로, 특정 표현을 얼마나 선호하는지를 나타내는 값이다.- 생략되었을 경우에는 1을 의미하고, 범위는 0부터 1까지이며, 값이 클수록 우선순위가 높다.
다음은 방금 설명한 예시에 대한 요청 헤더다.
- 한국어(ko-KR, ko), 영어(en-US, en)순으로 선호하고,
- HTML, XML, 일반 텍스트 순으로 선호한다는 것을 알 수 있다.
요청 메시지
1GET /index.html HTTP/1.12Host: example.com3Accept-Language: ko-KR, ko;q=-0.9,en-US;q=0.8,en;q=0.74Accept: text/html,application/xml;q=0.9,text/plain;q=0.6,*/*;q=0.5