1. 프로세스 개요
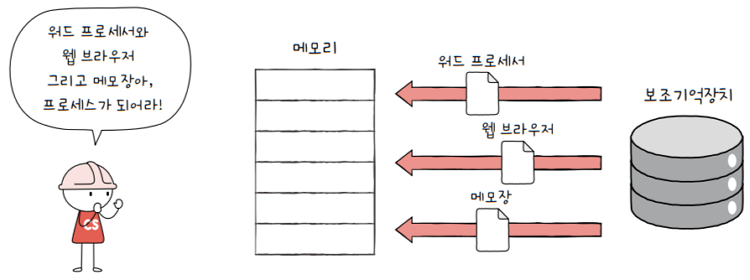
프로세스(process)=== 실행 중인 프로그램- 프로그램은 실행되기 전까지는 그저 보조기억장치에 있는
데이터 덩어리일 뿐이지만, - 메모리에 적재하고 실행하는 순간 그 프로그램은
프로세스가 됩니다. - 그리고 이 과정을
프로세스를 생성한다라고 표현합니다.
1.1 프로세스 직접 확인하기
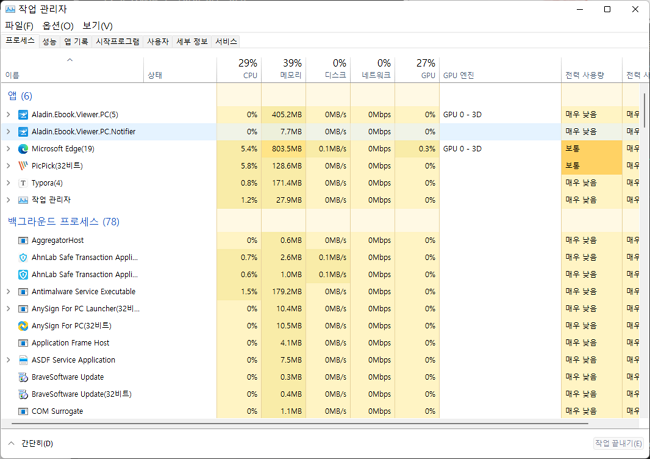
컴퓨터가 부팅되는 순간부터 수많은 프로세스들이 실행됩니다.
- 윈도우에서는
작업 관리자의 [프로세스] 탭에서 확인할 수 있고, - 유닉스 체계의 운영체제(MacOS, Linux) 에서는
ps 명령어로 확인할 수 있습니다
1berenickt@berenickt:~$ ps -ef2UID PID PPID C STIME TTY TIME CMD3root 1 0 0 14:04 ? 00:00:00 /init4root 4 1 0 14:04 ? 00:00:00 plan9 --control-socket 5 --log-level 4 --server-fd 65root 8 1 0 14:04 ? 00:00:00 /init6root 9 8 0 14:04 ? 00:00:00 /init7berenic+ 10 9 0 14:04 pts/0 00:00:00 -bash8berenic+ 220 10 0 14:04 pts/0 00:00:00 ps -ef
실제로 컴퓨터를 켜고 확인해보면,
- 여러분이 실행한 프로세스 외에도 알 수 없는 여러 프로세스가 실행되고 있는 것을 볼 수 있습니다.
- 프로세스의 종류를 크게 나눠보면 다음과 같이 나눠볼 수 있습니다.
포그라운드 프로세스(foreground process): 사용자가 보는 앞에서 실행되는 프로세스백그라운드 프로세스(background process): 사용자가 보지 못하는 뒤편에서 실행되는 프로세스
백그라운드 프로세스는 크게 2가지 종류가 있습니다.
- 사용자와 직접 상호작용할 수 있는 백그라운드 프로세스
- 사용자와 상호작용하지 않고 그저 묵묵히 정해진 일만 수행하는 백그라운드 프로세스
- 이러한 백그라운드 프로세스를
- 유닉스 체계의 운영체제에서는
데몬(daemon)이라고 부르고, - 윈도우 운영 체제에서는
서비스(service)라고 부릅니다.
1.2 프로세스 제어 블록(PCB)
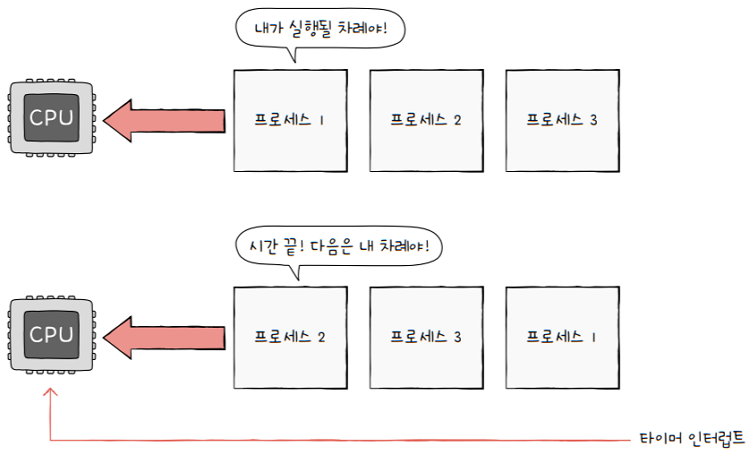
- 모든 프로세스는 실행을 위해 CPU가 필요합니다.
- But, CPU 자원은 한정되어 있습니다.
- 그래서 프로세스들은 차례대로 돌아가며 한정된 시간 만큼만 CPU를 이용합니다.
- 자신의 차례가 되면, 정해진 시간만큼 CPU를 이용하고,
- 시간이 끝났음을 알리는
인터럽트(타이머 인터럽트)가 발생하면, - 자신의 차례를 양보하고 다음 차례가 올 때까지 기다립니다.
- cf.
타이머 인터럽트- 클럭 신호를 발생시키는 장치에 의해 주기적으로 발생하는 하드웨어 인터럽트
타임아웃 인터럽트라고도 부름
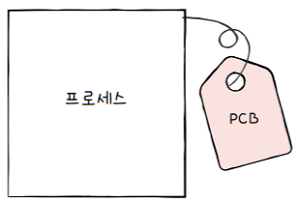
빠르게 번갈아가면서 수행되는 프로세스들을 관리하기 위해 등장한 자료구조가 PCB입니다.
프로세스 제어 블록(PCB; Process Control Block)
- 프로세스 관련 정보를 저장하는 자료구조
- 마치 옷이나 가전제품같은 상품에 달린 태그와 같은 정보
- PCB에는 해당 프로세스를 식별하기 위해 꼭 필요한 정보들이 저장됨
- 프로세스 생성 시
커널 영역에 생성, 종료 시 폐기- 옷가게 점원이 많은 옷들 사이에서 태그로 특정 옷을 식별하고, 관련 정보를 판단하는 것처럼
- 운영체제도 수많은 프로세스들 사이에서 PCB로 특정 프로세스를 식별하고,
- 해당 프로세스를 처리하는 데 필요한 정보를 판단합니다.
- e.g.
- 새로운 프로세스가 생성되었다 === 운영체제가 PCB를 생성했다
- 프로세스가 종료되었다 === 운영체제가 해당 PCB를 폐기했다
1.3 PCB에 담기는 정보
그렇다면 PCB에는 어떤 정보들이 담길까요? PCB에 담기는 정보는 운영체제마다 차이가 있지만, 대표적인 정보는 아래와 같습니다.
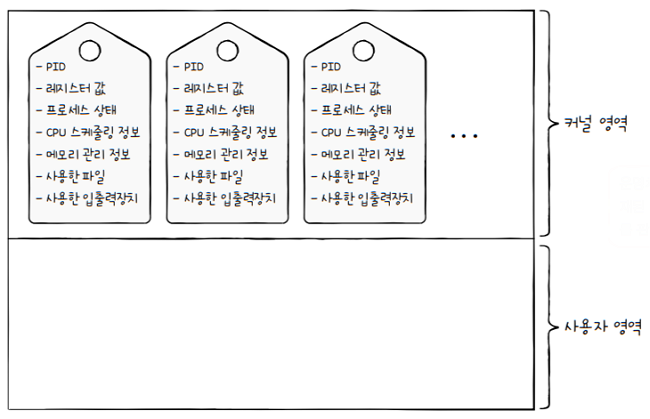
프로세스 ID (PID; Process ID)- 특정 프로세스를 식별하기 위해 부여하는 고유한 번호
- e.g. 학교의 학번, 회사의 사번
- 같은 일을 수행하는 프로그램이라 할지라도, 2번 실행하면 PID가 다른 2개의 프로세스가 생성됩니다.
- 윈도우 작업 관리자에서 [프로세스]에서,
- [마우스 오른쪽 클릭]해서 [프로세스 이름]을 클릭하면, PID를 확인 가능
레지스터 값- 프로세스는 자신의 실행 차례가 오면, 이전까지 사용한 레지스터 중간 값을 모두 복원합니다.
- 그래야만 이전까지 진행했던 작업들을 그대로 이어 실행할 수 있으니까
- 그래서 PCB 안에는 해당 프로세스가 실행하며,
- 사용했던 프로그램 카운터를 비롯한 레지스터 값들이 담깁니다.
- 프로그램 카운터, 스택 포인터 등등…
- 프로세스는 자신의 실행 차례가 오면, 이전까지 사용한 레지스터 중간 값을 모두 복원합니다.
프로세스 상태- 현재 프로세스가 입출력장치를 사용하기 위해 기다리고 있는 상태인지,
- CPU를 사용하기 위해 기다리고 있는 상태인지,
- 아니면 CPU를 이용하고 있는 상태인지 등의 프로세스 상태 정보가 PCB에 저장됩니다.
CPU 스케줄링 정보- 프로세스가 언제, 어떤 순서로 CPU를 할당받을지에 대한 정보도 PCB에 기록됩니다.
메모리 관리 정보- 프로세스마다 메모리에 저장된 위치가 다릅니다.
- 그래서 PCB에는 프로세스가 어느 주소에 저장되어 있는지에 대한 정보가 있어야 합니다.
- PCB에는 베이스 레지스터, 한계 레지스터 값과 같은 정보들이 담깁니다.
- 또한 프로세스의 주소를 알기 위한 또 다른 중요 정보 중 하나인 페이지 테이블 정보도 PCB에 담깁니다.
- cf. 페이지 테이블과 관련해서는 14장에서 다룹니다.
- 지금은 ‘PCB에는 프로세스의 메모리 주소를 알 수 있는 정보들이 담기는구나’ 정도로 이해
사용한 파일과 입출력장치 목록- 프로세스가 실행 과정에서 특정 입출력장치나 파일을 사용하면, PCB에 해당 내용이 명시됩니다.
- 즉, 어떤 입출력장치가 이 프로세스에 할당되었는지,
- 어떤 파일들을 열었는지에 대한 정보들이 PCB에 기록됩니다.
1.4 문맥 교환(context switch)
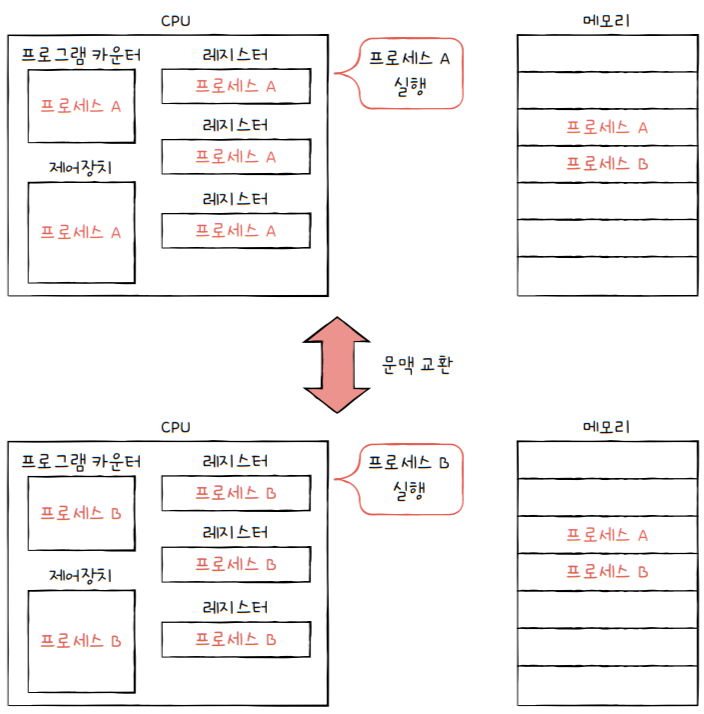
한 프로세스(e.g. 프로세스 A)에서다른 프로세스(e.g. 프로세스 B)로 실행 순서가 넘어간다면?- 기존에 실행되던
프로세스 A는 지금까지의 중간 정보를 백업합니다.- 프로그램 카운터 등 각종 레지스터 값, 메모리 정보, 열었더 파일, 사용한 입출력장치 등
- 이러한 중간 정보 ===
문맥(context)문맥: 다음 차례가 왔을 떄, 실행을 재개하기 위한 정보
- “실행 문맥을 백업해두면, 언제든 해당 프로세스의 실행을 재개할 수 있다.”
하나의 프로세스 문맥은 해당 프로세스의 PCB에 표현되어 있습니다.- PCB에 기록되는 정보들을
문맥이라고 봐도 무방합니다. - 문맥을 잘 백업해두면,
- 프로세스가 CPU를 사용할 수 있는 시간이 다 되거나, (=타이머 인터럽트)
- 예기치 못한 상황이 발생하여 인터럽트가 발생하더라도,
- 언제든지 해당 프로세스의 실행을 재개할 수 있습니다.
- 그리고 뒤이어 실행할
프로세스 B의 문맥을 복구합니다.- 이렇게 자연스럽게 실행 중인 프로세스가 바뀌는 것이지요.
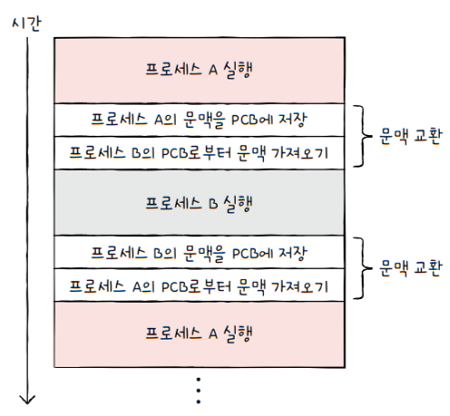
이러한 과정을 과정을 문맥 교환(context switching)이라고 합니다.
- 기존 프로세스의 문맥을 PCB에 백업하고,
- 새로운 프로세스를 실행하기 위해 문맥을 PCB로부터 복구하여 새로운 프로세스를 실행하는 것
문맥 교환은 여러 프로세스가 끊임없이 빠르게 번갈아가며 실행되는 원리입니다.
- 문맥 교환이 자주 일어나면, 프로세스는 그만큼 빨리 번갈아가며 수행되기 때문에,
- 여러분의 눈에는 프로세스들이 동시 에 실행되는 것처럼 보입니다.
- cf. 문맥 교환을 너무 자주 하면, 오버헤드가 발생할 수 있기 때문에,
- 문맥 교환이 자주 일어난다고 해서 반드시 좋은 건 아닙니다.
1.5 프로세스의 메모리 영역
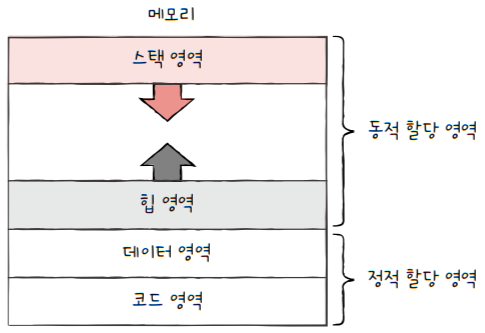
프로세스가 생성되면 커널 영역에 PCB가 생성된다고 했습니다. 그렇다면 사용자 영역에는 프로세스가 어떻게 배치될까요? 하나의 프로세스는 사용자 영역에 대표적으로 4가지 영역으로 나뉘어 저장됩니다.
코드 영역(=텍스트 영역)데이터 영역힙 영역스택 영역
1.5.1 코드 영역(Code Segment)
텍스트 영역(text segment)이라고도 부릅니다.- 실행할 수 있는 코드, 기계어로 이루어진 명령어가 저장됩니다.
- 데이터가 아닌 CPU가 실행할 명령어가 담겨 있기 때문에 쓰기가 금지된 영역
- 즉,
읽기 전용(read-only)공간
- 즉,
1.5.2 데이터 영역(Data Segment)
- 잠깐 썼다가 없앨 데이터가 아닌 프로그램이 실행되는 동안 유지할 데이터가 저장되는 공간
- e.g. 전역 변수(global variable)
1.5.3 힙 영역(Heap Segment)
- 프로그램을 만드는 사용자, 즉 프로그래머가 직접 할당할 수 있는 저장 공간
- 프로그래밍 과정에서 힙 영역에 메모리 공간을 할당했다면, 언젠가는 해당 공간을 반환해야 합니다.
- ‘메모리 공간을 반환한다’ === ‘더 이상 해당 메모리 공간을 사용하지 않겠다’
- 메모리 공간을 반환하지 않는다면,
- 할당한 공간은 메모리 내에 계속 남아 메모리 낭비를 초래합니다.
- 이런 문제를
메모리 누수(Memory Leak)라고 합니다. - 많은 개발자가 자주 마주치는 문제 중 하나이지요.
1693848==ERROR: LeakSanitizer: detected memory leaks # 888바이트의 메모리가 낭비되었습니다.23Direct leak of 888 byte(s) in 1 object(s) allocated from:4#0 0xffff8222ea30 in __interceptor_malloc (/lib/aarch64-linux-gnu/libasan.so.5+0xeda30)5#1 0xaaaacfbea224 in load_symtab /home/ubuntu/leak/uftrace/utils/symbol.c:4106#2 0xaaaacfbf6234 in load_module_symbol /home/ubuntu/leak/uftrace/utils/symbol.c:10607#3 0xaaaacfbf68f4 in load_module_symtab /home/ubuntu/leak/uftrace/utils/symbol.c:10968#4 0xaaaacfbf6fe8 in load_module_symtabs /home/ubuntu/leak/uftrace/utils/symbol.c:11729#5 0xaaaacfafb3d4 in load_session_symbols /home/ubuntu/leak/uftrace/cmds/record.c:146910#6 0xaaaacfb03570 in write_symbol_files /home/ubuntu/leak/uftrace/cmds/record.c:199011#7 0xaaaacfb04ee4 in do_main_loop /home/ubuntu/leak/uftrace/cmds/record.c:209412#8 0xaaaacfb06028 in command_record /home/ubuntu/leak/uftrace/cmds/record.c:220913#9 0xaaaacfa674d0 in main /home/ubuntu/leak/uftrace/uftrace.c:136914#10 0xffff812ea08c in __libc_start_main (/lib/aarch64-linux-gnu/atomics/libc.so.6+0x2408c)15#11 0xaaaacfa5a660 (/home/ubuntu/leak/uftrace/uftrace+0x2a7660)1617SUMMARY: AddressSanitizer: 888 byte(s) leaked in 1 allocation(s).
요즘은 프로그래밍 언어가 알아서 사용하지 않는 메모리를 반환해주는 경우가 있는데,
- 이를
가비지 컬렉션(Garbage Collection)이라고 합니다. - C언어같은 옛날 언어의 경우, 가비지 컬렉션이 없어서 일일이 메모리를 반환하는 과정을 거쳐야 합니다.
1.5.4 스택 영역(Stack Segment)
- 데이터를 일시적으로 저장하는 공간
- 데이터 영역에 담기는 값과는 달리 잠깐 쓰다가 말 값들이 저장되는 공간
- e.g. 매개변수, 지역변수
- 일시적으로 저장할 데이터는 스택 영역에 PUSH되고,
- 더 이상 필요하지 않은 데이터는 POP됨으로 써 스택 영역에서 사라집니다.
💡 정적 할당 영역 vs 동적 할당 영역
코드 영역과데이터 영역은 그 크기가 변하지 않습니다.- 프로그램을 구성하는 명령어들이 갑자기 바뀔 일이 없으니, 코드 영역의 크기가 변할리 없고,
데이터 영역에 저장될 내용은 프로그램이 실행되는 동안에만 유지될 데이터니까요.- 그래서
코드 영역과데이터 영역은 **‘크기가 고정된 영역’**입니다.
- 그래서 이 두 영역을
정적 할당 영역이라고도 부릅니다.
반면
힙 영역과스택 영역은 **‘프로세스 실행 과정에서 그 크기가 변할 수 있는 영역’**입니다.
- 그래서 이 두 영역을
동적 할당 영역이라고도 부릅니다.- 일반적으로
힙 영역은 메모리의 낮은 주소 → 높은 주소로 할당- 일반적으로
스택 영역은 메모리의 높은 주소 → 낮은 주소로 할당- 이렇게 해야만 힙 영역과 스택 영역에 데이터가 쌓여도, 새롭게 할당되는 주소가 겹칠 일이 없겠죠.
2. 프로세스 상태와 계층 구조
윈도우 운영체제를 사용해봤다면, 위와 같은 보기만 해도 아찔한 화면을 본 적이 있을 겁니다.
이는 해당 프로세스 상태가 **‘응답 없음’**을 알려주는 화면입니다.

이번에는 윈도우 작업 관리자의 [세부 정보] 탭에서 프로세스의 [상태] 탭을 한 번 볼까요?
- 어떤 프로세스는 ‘실행 중’ 상태이고, 어떤 프로세스는 ‘일시 중단됨’ 상태입니다
- 이렇듯 프로세스는 모두 저마다의 상태가 있습니다.
- 운영체제는 이런 프로세스의 상태를
PCB에 기록하여 관리합니다. - 그리고 많은 운영체제는 이처럼 동시에 실행되는 수많은 프로세스를 계층적으로 관리합니다.
- 이번 절에서는 프로세스들의 상태와 계층적 관리에 대해 자세히 알아보겠습니다.
2.1 프로세스 상태
여러분이 컴퓨터를 사용할 때, 여러 프로세스들이 빠르게 번갈아 가면서 실행된다고 했습니다.
- 그 과정에서
하나의 프로세스는 여러 상태를 거치며 실행됩니다. - 그리고
운영체제는프로세스의 상태를PCB를 통해 인식하고 관리합니다.
프로세스의 상태를 표현하는 방식은 운영체제마다 조금씩 차이가 있지만, 프로세스가 가질 수 있는 대표적인 상태는 다음과 같습니다.
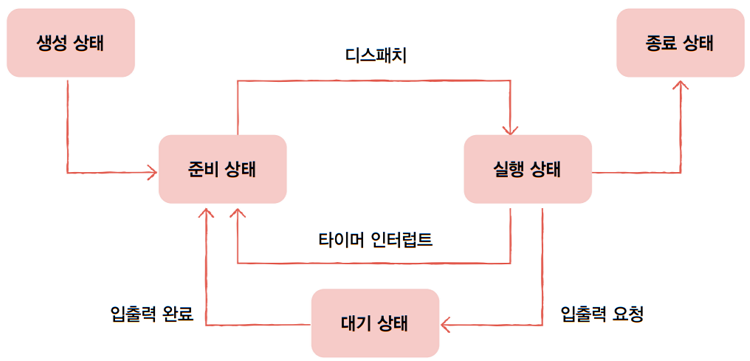
생성 상태(new)- 이제 막 메모리에 적재되어 PCB를 할당 받은 상태
- 준비가 완료되었다면, 준비 상태로
준비 상태(ready)- 당장이라도 CPU를 할당받아실행할 수 있지만,
- 자신의 차례가 아니기에 기다리는 상태
- 자신의 차례가 된다면, 실행 상태로 (=디스패치, dispatch)
실행 상태(running)- CPU를 할당받아 실행 중인 상태
- 할당된 시간 모두 사용 시 (타이머 인터럽트 발생 시) 준비 상태로
- 실행 도중 입출력장치를 사용하면, 입출력 작업이 끝날 떄까지 대기 상태로
대기 상태(blocked)- 프로세스가 실행 도중 입출력장치를 사용하는 경우
- 입출력 작업은 CPU에 비해 느리기에 이 경우 대기 상태로 접어듬
- 입출력 작업이 끝나면 (입출력 완료 인터럽트를 받으면) 준비 상태로
종료 상태(terminated)- 프로세스가 종료된 상태
- 프로세스가 종료되면 운영체제는 PCB와 프로세스가 사용한 메모리를 정리
💡 상태 다이어그램(process state diagram)
위와 같은 도표를 프로세스
상태 다이어그램(process state diagram)이라고 합니다. 이처럼 컴퓨터 내의 여러 프로세스는 생성, 준비, 실행, 대기, 종료 상태를 거치며 실행됩니다. 운영체제는 이 상태를 PCB에 기록하며 프로세스들을 관리하는 것이지요.
💡 대기 상태의 일반적인 정의
프로세스가 대기 상태가 되는 이유에 입출력 작업만 있는 것은 아닙니다.
- 조금 더 일반적으로 표현하자면, 특정 이벤트가 일어나길 기다릴 때, 프로세스는 대기 상태가 됩니다.
- 다만, 프로세스가 대기 상태가 되는 대부분의 원인이 입출력 작업이기 때문에,
- **‘프로세스가 입출력 작업을 하면 대기 상태가 된다’**고 생각해도 무방합니다.
2.2 프로세스 계층 구조
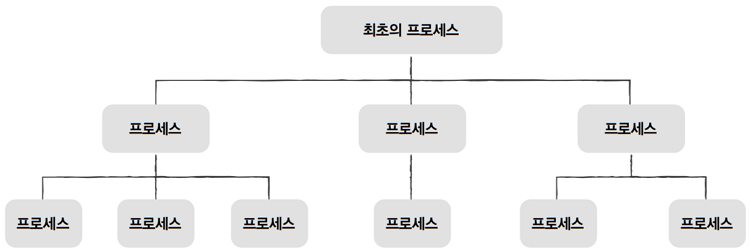
- 대부분의 운영체제에서 프로세스를 계층적으로 관리합니다.
- cf. 엄밀히 따지면, 윈도우는 프로세스를 계층적으로 관리하지 않습니다.
- But 개발자들이 많이 사용하는 UNIX 기반 운영체제는 계층적으로 프로세스를 관리합니다.
- 프로세스는 실행 도중, 시스템 호출을 통해 다른 프로세스를 생성할 수 있습니다.
- 새 프로세스를 생성한 프로세스를
부모 프로세스(parent process) - 부모 프로세스에 의해 생성된 프로세스를
자식 프로세스(child process)
- 새 프로세스를 생성한 프로세스를
- 부모 프로세스와 자식 프로세스는 별개의 프로세스이므로 각기 다른 PID를 가집니다.
- cf. 일부 운영체제에서는 자식 프로세스의 PCB에 부모 프로세스의 PID인
PPID (Parent PID)를 기록하기도 합니다.
- 자식 프로세스는 또 다른 자식 프로세르를 낳을 수 있고,
- 그 자식 프로세스는 또 다른 자식 프로세스를 낳을 수 있고, …
- 이처럼 프로세스가 프로세스를 낳는 계층적인 구조로써 프로세스들을 관리합니다.
- 이 과정을 도표로 그리면, 위 그림과 같은 트리 구조를 띄는데,
- 이를
프로세스 계층 구조라고 합니다.
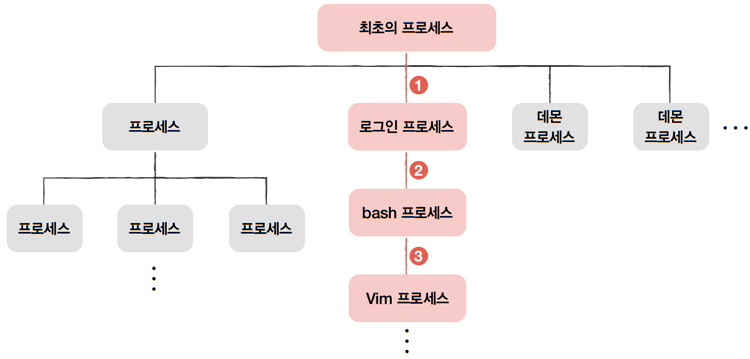
e.g. 사용자가 컴퓨터를 켜고, 로그인 창을 통해 성공적으로 로그인해서, bash 셸(사용자 인터 페이스)로 Vim이라는 문서 편집기 프로그램을 실행했다고 가정해 봅시다.
- 사용자가 컴퓨터를 켠 순간에 생성된
최초 프로세스는로그인을 담당하는 프로세스를 자식 프로세스로 생성한 것이고,
로그인 프로세스는사용자 인터페이스(bash 셸) 프로세스를 자식 프로세스로 생성한 것이고,사용자 인터페이스(bash) 프로세스는 Vim 프로세스를 생성한 셈입니다.
💡
데몬이나서비스또한 최초 프로세스의 자식 프로세스입니다.
💡 최초의 프로세스
모든 프로세스의 가장 위에 있는 최초의 프로세스는 무엇일까요? 최초의 프로세스는
- 유닉스 운영체제에서는
init- 리눅스 운영체제에서는
systemd- macOS에서는
launchd라고 합니다.최초의 프로세스 PID는 항상 1번이며, 모든 프로세스 최상단에 있는 부모 프로세스입니다. 직접 확인해 볼까요?
pstree명령어는 프로세스 계층 구조를 보여주는 명령어입니다.
- 리눅스에서
pstree명령어를 입력하면systemd가 최상단에 있다는 것을 확인할 수 있고,- macOS에서
pstree명령어를 입력하면launchd가 최상단에 있는 것을 확인할 수 있 습니다.리눅스에서 최초의 프로세스 확인하기
1[root@localhost ~]# pstree2systemd─┬─accounts-daemon───2*[{accounts-daemon}] # systemd가 최상단 프로세스3├─2*[agetty]4├─containerd───9*[{containerd}]5├─cron6├─dbus-daemon7├─2*[dnsmasq]8├─dockerd───10*[{dockerd}]macOS에서 최초의 프로세스 확인하기
1minchul-Mac-mini:~ minchul$ pstree2-+= 00001 root /sbin/launchd # launched가 최상단 프로세스3|--= 00053 root /usr/sbin/syslogd4|--= 00054 root /usr/libexec/UserEventAgent (System)5|--= 00056 root /usr/libexec/wifiFirmwareLoader6|--= 00057 root
2.3 프로세스 생성 기법
부모 프로세스가 자식 프로세스를 어떻게 만들어 내고,
자식 프로세스는 어떻게 자신만의 코드를 실행하는지 조금 더 자세히 알아봅시다.
이하 내용은 윈도우 운영체제와는 관련이 없으나, 수 많은 운영체제의 핵심 개념이니 꼭 알아두세요.
결론부터 말하면, 부모 프로세스를 통해 생성된 자식 프로세스들은 복제와 옷 갈아입기를 통해 실행됩니다.
부모 프로세스는fork 시스템 호출을 통해 자신의 복사본을 자식 프로세스로 생성해내고,- e.g. 복제에 비유
자식 프로세스는exec 시스템 호출를 통해 자신의 메모리 공간을 다른 프로그램으로 교체합니다.- e.g. 옷 갈아입기에 비유
- 만들어진 복사본(자식 프로세스)은
- fork와 exec에 대해 조금 더 자세히 알아봅시다
2.3.1 fork 시스템 호출
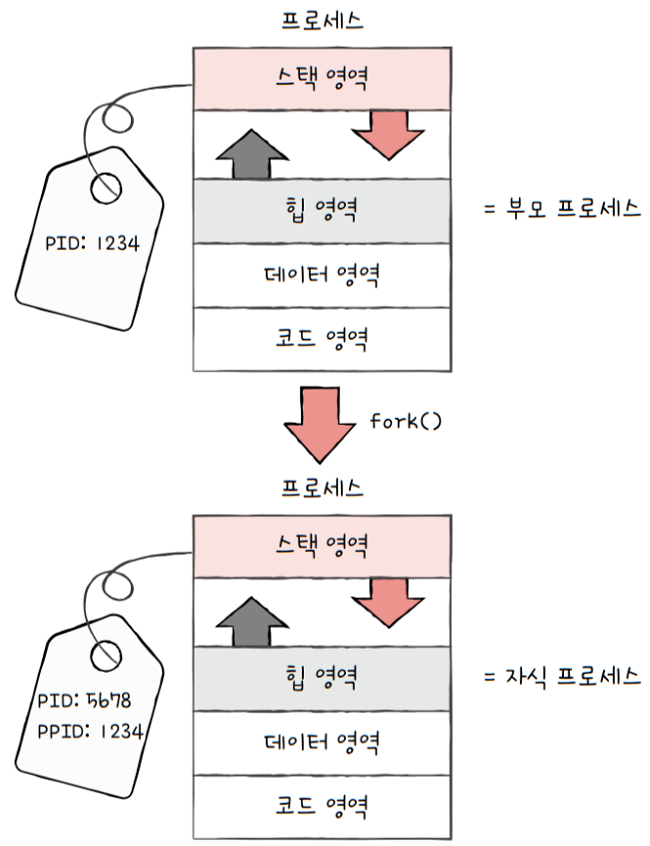
부모 프로세스는fork 시스템 호출을 통해 자신의 복사본을 자식 프로세스로 생성합니다.- 부모 프로세스의 자원들, 이를테면 메모리 내의 내용, 열린 파일의 목록 등이 자식 프로세스에 상속됩니다
- cf. 복사된 자식 프로세스라 할지라도 PID 값이나 저장된 메모리 위치는 다릅니다.
2.3.2 exec 시스템 호출
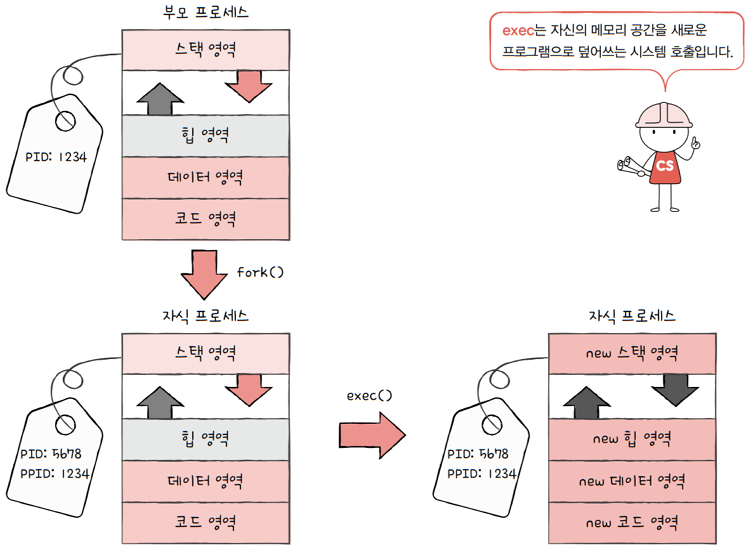
fork를 통해 복사본이 만들어진 뒤에 자식 프로세스는exec 시스템 호출을 통해 새로운 프로그램으로 전환됩니다.
exec는 자신의 메모리 공간을 새로운 프로그램으로 덮어쓰는 시스템 호출입니다.- 다시 말해, 새로운 프로그램 내용으로 전환하여 실행하는 시스템 호출입니다.
- exec는
코드 영역과데이터 영역의 내용이 실행할 프로그램의 내용으로 바뀌고,- 나머지 영역은 초기화됩니다.
- e.g. 메모리 공간에 새로운 프로그램 내용이 덮어 써진다는 점에서
- 이는 자식 프로세스가 새로운 옷으로 갈아입는 것 같음
- e.g. 사용자가 bash 셸에서 ls라는 명령어를 쳤다고 가정해 봅시다.
- 셸 프로세스는 fork를 통해 자신과 동일한 프로세스를 생성하고,
- 그로부터 탄생한 자식 프로세스는 exec를 통해 ls 명령어를 실행하기 위한 프로세스로 전환되어 실행됩니다.
- 자식 프로세스는 ls 명령어를 실행하기 위한 프로세스로 바뀌고,
- 메모리 공간에는 ls 명령어를 실행하기 위한 내용들이 채워집니다.
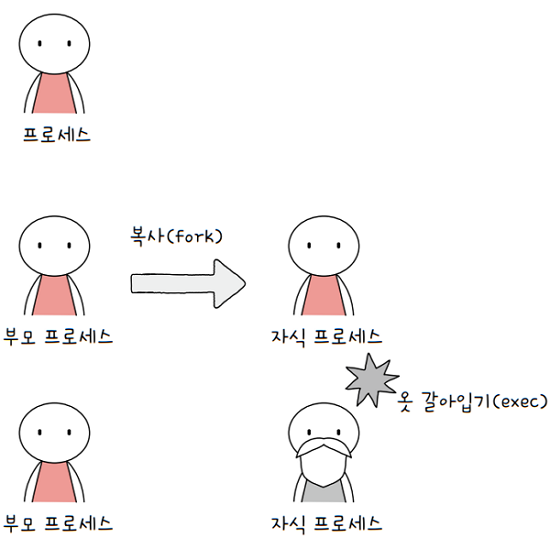
정리하면, 부모가 자식 프로세스를 실행하며, 프로세스 계층 구조를 이루는 과정은
fork과 exec가 반복되는 과정이라 볼 수 있습니다.- 쉽게 말해,
부모 프로세스로부터자식 프로세스가 복사되고,자식 프로세스는 새로운 프로그램으로 옷을 갈아입고,- 또
그 자식 프로세스로부터자식 프로세스가 복사되고, - 옷을 갈아입는 방식으로 여러 프로세스가 계층적으로 실행되는 것입니다.
- 부모 프로세스가 자식 프로세스를 fork한 뒤에
- 부모 프로세스, 자식 프로세스 누구도 exec를 호출 하지 않는 경우도 있습니다.
- 이 경우
부모 프로세스와자식 프로세스는 같은 코드를 병행하여 실행하는 프로세스가 됩니다.
여기까지 프로세스에 대해 알아보았습니다. 아직 한 단계가 더 남아 있습니다.
- 지금까지 배운 내용들을 간단한 소스 코드로 학습해 보는 단계입니다.
- 하드웨어의 큰 그림을 그리고 작동 원리를 학습했었던 컴퓨터 구조 편과는 달리,
- 운영체제 편은 코드와 맞닿아 있는 부분이 많습니다.
- 프로그래밍 언어 입문서만 가볍게 학습한다면, 놓치기 쉬운 중요한 내용들도 많이 포함되어 있지요.
- 그렇기 때문에 프로그래밍 언어를 학습해본 적이 있는 독자라면,
- 필자가 제시하는 아래 링크 속 소스 코드를 직접 실행해 보는 연습을 해보길 권합니다.
- C/C++, Python, Java 등의 프로그래밍 언어로 프로세스를 다루는 예제들은
- 아래 링크 process 항목에 첨부해 두겠습니다.
- https://github.com/kangtegong/self-learning-cs
3. 스레드(thread)
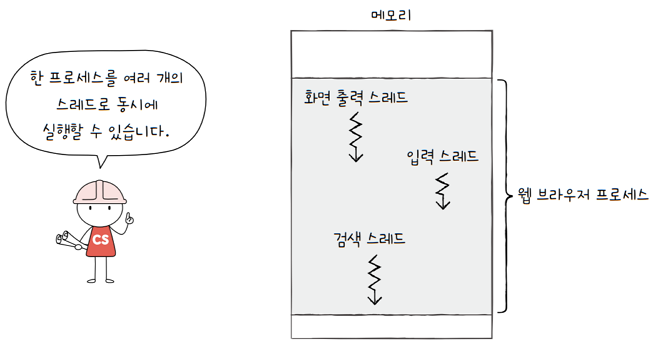
스레드(thread)는 프로세스를 구성하는 실행의 흐름 단위입니다.- 하나의 프로세스는 여러 개의 스레드를 가질 수 있습니다.
- 스레드를 이용하면, 하나의 프로세스에서 여러 부분을 동시에 실행할 수 있습니다.
3.1 프로세스와 스레드
3.1.1 단일스레드 프로세스
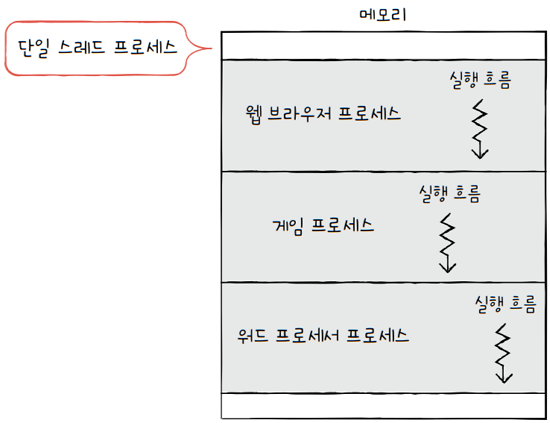
전통적인 관점에서 보면 하나의 프로세스는 한 번에 하나의 일만을 처리했습니다.
- **‘실행의 흐름 단위가 하나인 프로세스’**를
단일 스레드 프로세스라고 합니다. - 앞선 절에서도 한 번에 하나의 작업을 처리하는 프로세스를 상정했습니다.
- e.g. 웹 브라우저, 게임, 워드 프로세서 프로세스가 있을 때,
- 이 모든 프로세스가 하나의 실행 흐름을 가지고,
- 한 번에 하나의 부분만 실행되는 프로세스를 가정했습니다.
3.1.2 멀티스레드 프로세스
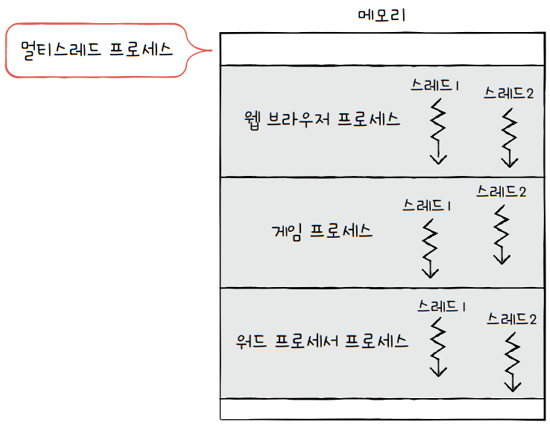
하지만 스레드라는 개념이 도입되면서, 하나의 프로세스가 한 번에 여러 일을 동시에 처리할 수 있게 되었습니다.
- 즉,
프로세스를 구성하는 여러 명령어를 동시에 실행할 수 있게 된 것이지요. - 이런 점에서 볼 때,
스레드는 **‘프로세스를 구성하는 실행 단위’**라고 볼 수 있습니다. - 현재 대부분의 사람들이 사용하는 프로그램같은 경우, 실행흐름이 여러 개인 경우가 많습니다.
- e.g. 웹 브라우저 프로세스는 검색, 입력, 화면출력 프로세스 등등…
- e.g. 워드 프로세서 프로세스는 자동저장, 입력, 화면출력 프로세스 등등…
- 이렇게 실행 흐름이 여러 개인 프로세스를
멀티스레드 프로세스라고 부릅니다.- 프로세르르 이루는 여러 명령어를 동시에 실행 가능
어떻게 실행 흐름의 단위를 스레드로 나누어 실행할 수 있을까요? 이 의문을 알기 위해서는 스레드의 구성 요소를 알아야 합니다.
3.1.3 스레드의 구성 요소
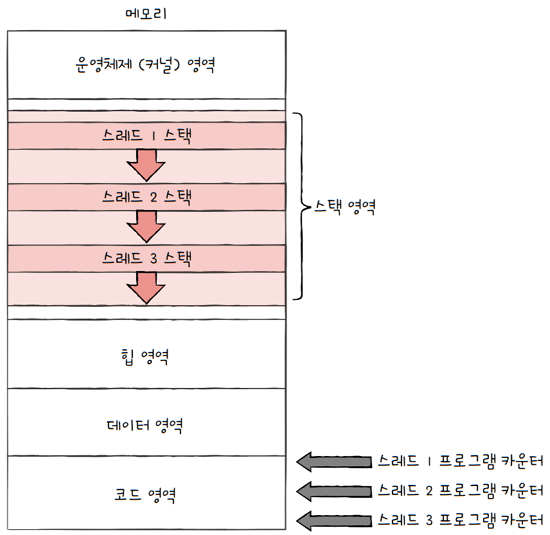
- 프로세스 내에서 각기 다른 스레드 ID, 프로그램 카운터 값을 비롯한 레지스터 값, 스택으로 구성됩니다.
- 각자 프로그램 카운터 값을 비롯한 레지스터 값, 스택을 가지고 있기에,
- 스레드마다 각기 다른 코드를 실행할 수 있습니다.
- 중요한 점은 각 스레드마다 실행에 필요한 최소한의 정보만,
- 유지한 채 프로세스 자원을 공유하며, 실행한다는 점입니다.
- cf. 최소한의 정보 : 프로그램 카운터를 포함한 레지스터, 스택 등
- 프로세스의 자원을 공유한다는 것이 스레드의 핵심입니다.
- 유지한 채 프로세스 자원을 공유하며, 실행한다는 점입니다.
- 위 그림의 예를 보면,
스레드 1, 2, 3모두 똑같은 코드/데이터/힙 영역을 공유하고 있습니다.스레드 1만의 코드/데이터/힙 영역이 있고,스레드 2만의 코드/데이터/힙 영역이 있는게 아니라는 의미입니다.- 그리고 만약에
이 프로세스가 어떤 파일을 열었다면,모든 스레드들은 그 열린 파일에 접근할 수 있습니다.
정리하면, 프로세스가 실행되는 프로그램이라면, 스레드는 프로세스를 구성하는 실행의 흐름 단위입니다.
- 실제로 최근 많은 운영체제는 CPU에 처리할 작업을 전달할 때, 프로세스가 아닌 스레드 단위로 전달합니다.
- 그리고
스레드는 프로세스 자원을 공유한 채, 실행에 필요한 최소한의 정보만으로 실행됩니다.
💡 리눅스 운영체제에서 프로세스 vs 스레드
많은 운영체제가 프로세스와 스레드를 구분하지만,
- 프로세스와 스레드 간에 명확한 구분을 짓지 않는 운영체제도 있습니다.
- 대표적으로 리눅스가 그러합니다.
- 프로세스와 스레드 모두
실행의 문맥(context of execution)이라는 점에서 동등하다고 간주하고,- 이 둘을 크게 구분짓지 않습니다.
- 프로세스와 스레드라는 말 대신
태스크(task)라는 이름으로 통일하여 명명하지요.
위 그림은 “프로세스와 스레드의 개념을 조금 더 분명히 구분 지을 필요가 있다”는 말에 대한
- 리눅스 운영체제 창시자 리누스 토르발스(Linus Torvalds)의 반응입니다.
- 프로세스와 스레드를 바라보는 운영체제 창시자의 철학을 엿볼 수 있는 흥미로운 읽을거리이니
- 전문을 읽어 보고 싶은 독자들은 아래 링크를 참고하길 바랍니다.
- https://lkml.iu.edu/hypermail/linux/kernel/9608/0191.html

3.2 멀티프로세스와 멀티스레드
하나의 프로세스에 여러 스레드가 있을 수 있다는 말을 조금 더 자세히 알아봅시다.
컴퓨터는 실행 과정에서 여러 프로세스가 동시에 실행될 수 있고,
그 프로세스를 이루는 스레드는 여러 개 있을 수 있다고 했습니다.
여기서 한 가지 궁금증이 생깁니다.
- 동일한 작업을 수행하는 단일 스레드 프로세스 여러 개를 실행하는 것과
멀티프로세스(multiprocess)
- 하나의 프로세스를 여러 스레드로 실행하는 것은 무엇이 다를까요?
멀티스레드(multithread)
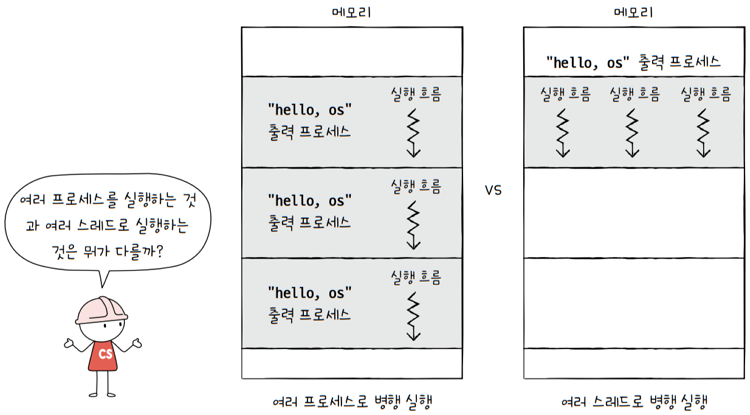
e.g. “hello, os”를 화면에 출력하는 간단한 프로그램이 있다고 해 봅시다.
- 이 프로그램을 3번 fork하여 실행하면, 화면에는 “hello, os”가 세 번 출력됩니다.
- 이 프로그램 내에 “hello, os”를 출력하는 스레드를 3개 만들어 실행해도
- 화면에는 “hello, os”가 세 번 출력됩니다.
- 이 둘은 무엇이 다를까요? “hello, os”가 3번 출력된다는 결과는 같은데 말이죠.
여기에는 큰 차이가 있습니다.
프로세스끼리는 기본적으로 자원을 공유하지 않지만,스레드끼리는 같은 프로세스 내의 자원을 공유한다는 점입니다.
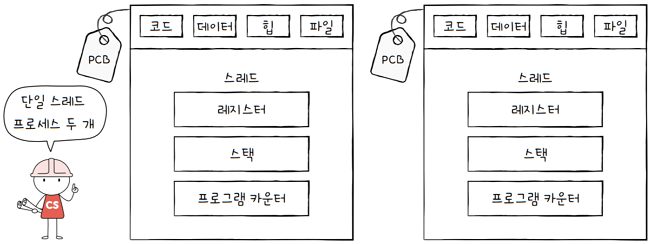
**‘프로세스를 fork하면, 코드/데이터/힙 영역 등 모든 자원이 복제되어 메모리에 저장된다’**고 배웠습니다.
- 즉, 자식 프로세스로서 부모 프로세스의 복제본이 생성됩니다.
- 다시말해, 저장된 메로리 주소(PID)를 제외하면,
- 모든 것이 동일한 프로세스 2개가 통째로 메모리에 적재된 것입니다.
- fork를 4번, 5번 하면 마찬가지로 메모리에는 같은 프로세스가 통째로 3개, 4개 적재됩니다.
- 이는 어찌보면 낭비입니다.
- 같은 프로그램을 실행하기 위해, 메모리에 동일한 내용들이 중복해서 존재하는 것이니까요.
💡 쓰기 시 복사(copy on write) 기법
- fork를 한 직후 같은 프로세스를 통째로 메모리에 중복 저장하지 않으면서,
- 동시에 프로세스끼리 자원을 공유하지 않는 방법도 있습니다.
- 이를
쓰기 시 복사(copy on write)기법이라고 하는데,- 이는 14장의 좀 더 알아보기에서 설명하겠습니다.
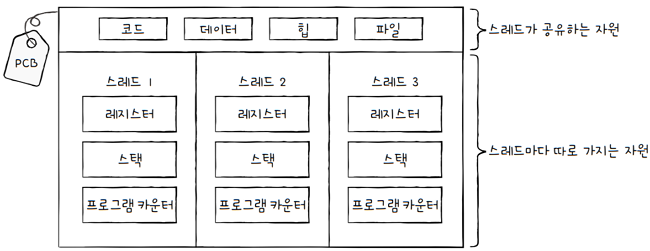
이에 반해, 스레드들은 각기 다른 스레드 ID, 프로그램 카운터 값을 포함한 레지스터 값, 스택을 가질 뿐,
프로세스가 가지고 있는 자원을 공유합니다.
- 같은 프로세스 내의 모든 스레드는 위 그림처럼 동일한 주소 공간의 코드, 데이터, 힙 영역을 공유하고,
- 열린 파일과 같은 프로세스 자원을 공유합니다.
- 여러 프로세스를 병행 실행하는 것보다 메모리를 더 효율적으로 사용할 수 있겠지요.
- 정리하면,
- 프로세스끼리는 자원을 공유하지 않는다 → 남남처럼 독립적으로 실행된다.
- 스레드는 프로세스의 자원을 공유한다 → 협력과 통신에 유리하다.
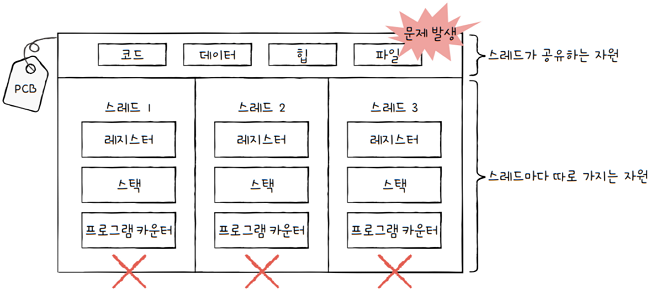
프로세스의 자원을 공유한다는 특성은 때론 단점이 될 수도 있는데,
멀티프로세스 환경에서는 하나의 프로세스에 문제가 생겨도 다른 프로세스에는 지장이 적거나 없지만,멀티스레드 환경에서는 하나의 스레드에 문제가 생기면, 프로세스 전체에 문제가 생길 수 있습니다.- 모든 스레드는 프로세스의 자원을 공유하고,
- 하나의 스레드에 문제가 생기면 다른 스레드도 영향을 받기 때문입니다.
💡 프로세스 간 통신 ( IPC )
프로세스끼리는 ‘기본적으로’ 자원을 공유하지 않지만,
- 프로세스끼리도 충분히 자원을 공유하고 데이터를 주고받을 수 있습니다.
- 프로세스 간의 자원을 공유하고 데이터를 주고받는 것을
프로세스 간 통신(IPC; Inter-Process Communication)이라고 부릅니다.- IPC라고 줄여 부르는 경우가 많지요.
‘통신’이라는 말을 들으면 네트워크를 통해 데이터를 주고 받는 방식만을 떠올리기 쉽지만,
- 같은 컴퓨터 내의 서로 다른 프로세스나 스레드끼리 데이터를 주고받는 것도 통신으로 간주합니다.
- e.g.
- 프로세스 A는 ‘hello.txt’ 파일에 새로운 값을 쓰는 프로세스,
- 프로세스 B는 ‘hello.txt’ 파일을 읽는 프로세스라면
- 두 프로세스는 ‘hello.txt’ 파일 속 데이터를 주고받으므로 프로세스 간의 통신이 이루어져야 합니다.
- 이는 파일을 통한 **프로세스 간 통신(IPC)**으로 볼 수 있습니다.
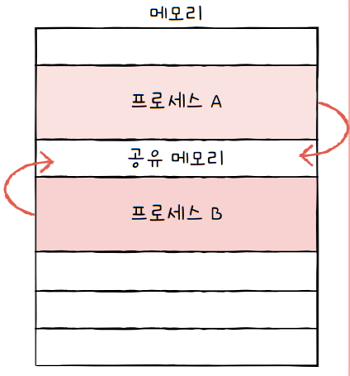
또 프로세스들은 서로 공유하는 메모리 영역을 두어 데이터를 주고받을 수 있습니다.
- 프로세스들이 공유할 수 있는 메모리 영역**을
공유 메모리(shared memory)라고 합니다.- e.g. 프로세스 A와 B가 공유하는 메모리 영역 내에 ‘name’이라는 전역 변수가 있다고 가정하면,
- 프로세스 A가 name 안에 값을 저장한 뒤,
- 프로세스 B가 name 변수 값을 읽어들인다면
- 두 프로세스는 전역 변수 name을 통해 서로 값을 주고받았다고 볼 수 있습니다.
- 이 외에도 프로세스들은 소켓, 파이프 등을 통해 통신할 수 있습니다.
즉,
프로세스들끼리 데이터를 교환하는 것은 모든 자원을 처음부터 공유하고 있는 스레드에 비하면, 다소 까다로운 것일 뿐, 불가능한 것은 아닙니다.
이상으로 스레드에 대해 학습해 보았습니다. 앞선 절과 마찬가지로 지금까지 배운 내용들을 간단한 소스 코드로 학습해 보길 권합니다. C/C++, Python, Java와 같은 언어로 스레드를 다루는 예제들은 아래 링크 thread 항목을 참고하세요.