1. 연속 메모리 할당
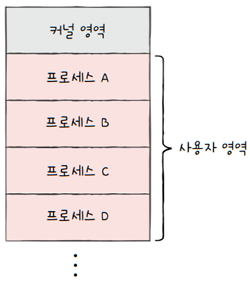
지금까지는 메모리 내에 프로세스들이 연속적으로 배치되는 상황을 가정했습니다.
- e.g.
프로세스 A는 A의 크기만큼 메모리 주소를 할당받아 연속적으로 배치되고, 프로세스 B는 프로 세스 A 이후에 또 B의 크기만큼 연속적인 메모리 주소를 할당받아 배치되는 식
이렇게 프로세스에 연속적인 메모리 공간을 할당하는 방식을 연속 메모리 할당 방식이라고 합니다.
- 이번 절에서는 이와 같이 프로세스들을 메모리에 연속적으로 할당할 때 무엇을 고려해야 하는지,
- 그리고 어떤 잠재적인 문제가 있는지 알아보겠습니다.
1.1 스와핑(swapping)
먼저, 운영체제가 메모리를 관리하는 아주 기본적인 기능 중에 스와핑에 대해 이해할 필요가 있습니다.
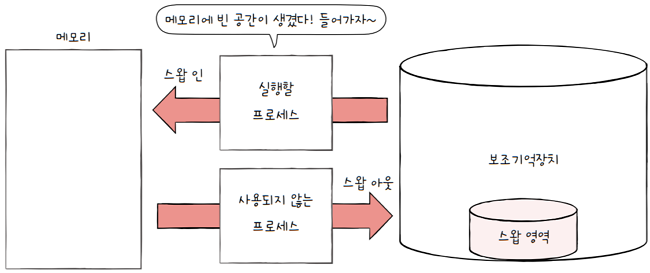
스와핑- 현재 사용되지 않는 프로세스들을 보조기억장치의 일부 영역으로 쫓아내고,
- 그렇게 생긴 빈 공간에 새 프로세스 적재하는 방식
- 프로세스들이 쫓겨나는 보조기억장치의 일부 영역을
스왑 영역(swap space)이라고 합니다. 스왑 아웃(swap-out): 현재 실행되지 않는 프로세스가 메모리에서 스왑 영역으로 옮겨지는 것스왑 인(swap-in): 스왑 영역에 있던 프로세스가 다시 메모리로 옮겨오는 것- cf. 스왑 아웃되었던 프로세스가 다시 스왑 인될 때는
- 스왑 아웃되기 전의 물리 주소와는 다른 주소에 적재될 수 있습니다.
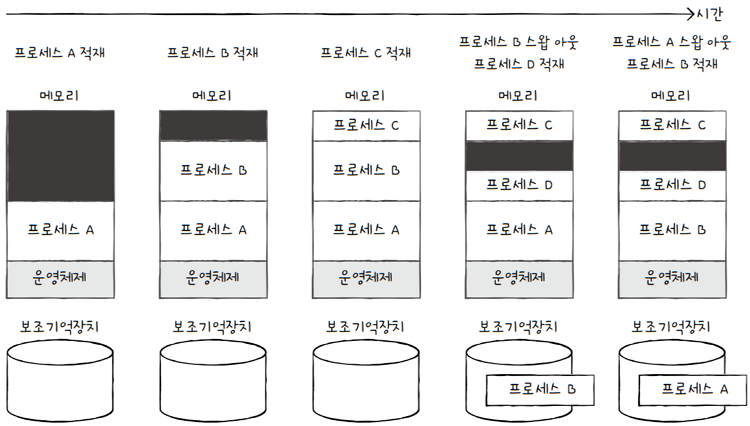
스와핑을 이용하면,
프로세스들이 요구하는 메모리 주소 공간의 크기 > 실제 메모리 크기인 경우에도- 프로세스들을 동시 실행할 수 있습니다.
- 위 그림을 보면,
- 프로세스 A, B, C, D의 크기를 합하면 실제 물리 메모리의 크기보다 크지만,
- 스와핑을 통해 4개의 프로세스를 동시에 실행 가능합니다.
- C까지 적재되어 메모리가 꽉 찬 상태에서,
- 지금 당장 D를 실행해야 되고, 지금 당장 B를 실행할 필요가 없다면,
- B를 스왑 아웃시켜 스왑 영역으로 옮기고,
- D를 메모리에 적재합니다.
- 또 지금 당장 B를 실행해야 된다면, 스왕 영역에 있는 B를 스왑 인시켜서 메모리에 적재하고
- 지금 당장 실행될 필요가 없는 A를 스왑 아웃시킵니다.
- cf. 그림 속 검은색 부분은
프로세스를 적재할 수 있는 메모리 영역
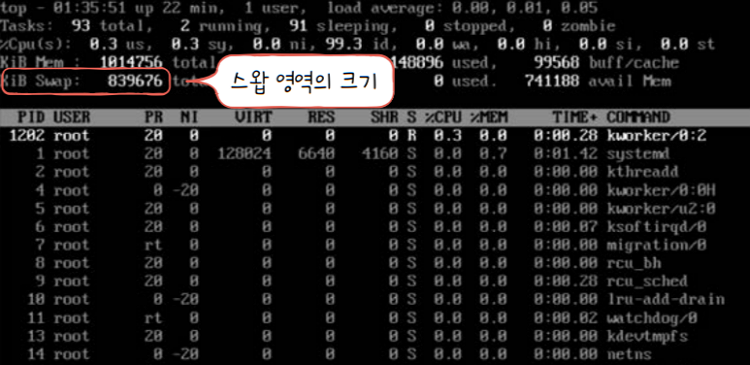
💡 스왑 영역 확인하기
유닉스와 리눅스, macOS에서는
free, top 명령어등을 통해 스왑 영역의 크기를 확인할 수 있습니다. 스왑 영역의 크기와 사용 여부는 사용자가 임의로 설정할 수 있습니다.1[root@localhost ~]# free -h2total used free shared buff/cache available3Mem: 990M 144M 749M 6.7M 96M 724M4Swap: 819M 0M 819M
1.2 메모리 할당
프로세스는 실행되기 위해서 메모리 내의 빈 공간에 적재되어야 합니다.
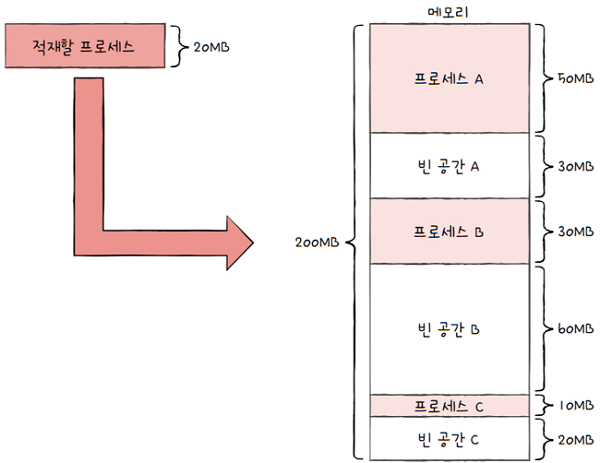
e.g. 위 그림처럼 메모리의 사용자 영역은 총 200MB인 상황에서, 20MB 크기의 프로세스를 적재하고 싶다면,
- 빈 공간에 할당해야 합니다.
- 프로세스를 적재할 수 있는 빈 공간은 빈 공간 A, 빈 공간 B, 빈 공간 C 3군데가 있습니다.
- 메모리 내에 빈 공간이 여러 개 있다면 프로세스를 어디에 배치해야 할까요?
- 여기에는 대표적으로
최초 적합,최적 접합,최악 적합방식이 있습니다.
1.2.1 최초 적합(first-fit)
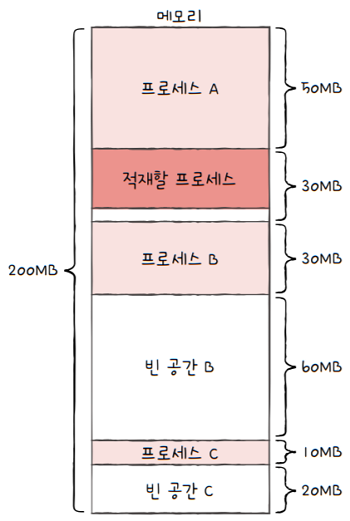
- 운영체제가 메모리 내의 빈 공간을 순서대로 검색하다가, 적재할 수 있는 공간을 발견하면,
- 그 공간에 프로세스를 배치하는 방식
- e.g. 빈 공간 A → 빈 공간 B → 빈 공간 C 순으로 빈 공간을 검색했다면,
- 프로세스는 빈 공간 A에 적재
- 장점은 검색을 최소화할 수 있고, 결과적으로 빠른 할당이 가능합니다.
1.2.2 최적 적합(best-fit)
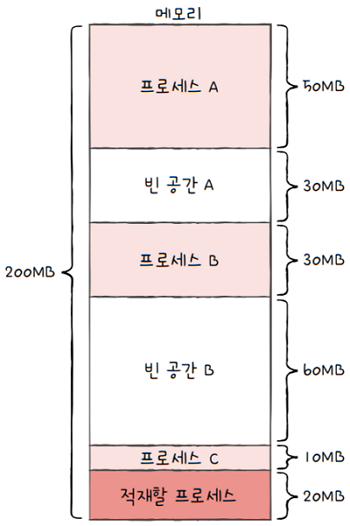
- 운영체제가 빈 공간을 모두 검색해본 후,
- 프로세스가 적재될 수 있는 공간 중 가장 작은 공간에 프로세스를 배치하는 방식
- e.g. 위 그림에서 프로세스가 적재될 수 있는 빈 공간 중 가장 작은 공간은 빈 공간 C입니다.
- 그렇기에 최적 적합 방식으로 메모리를 할당하면, 프로세스는 빈 공간 C에 할당됩니다.
1.2.3 최악 적합(worst-fit)
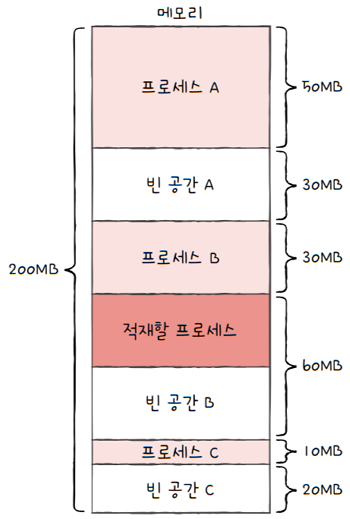
- 운영체제가 빈 공간을 모두 검색해 본 후,
- 프로세스가 적재될 수 있는 공간 중 가장 큰 공간에 프로세스를 배치하는 방식
- e.g. 프로세스가 적재될 수 있는 빈 공간 중 가장 큰 공간은 빈 공간 B입니다.
- 그렇기에 최악 적합 방식으로 메모리를 할당하면 프로세스는 빈 공간 B에 할당됩니다.
1.3 외부 단편화
1.3.1 외부단편화 발생 과정
프로세스를 메모리에 연속적으로 배치하는 연속 메모리 할당은 언뜻 들으면 당연하게 느껴질 수 있지만,
- 사실 이는 메모리를 효율적으로 사용하는 방법이 아닙니다.
- 왜냐하면 연속 메모리 할당은
외부 단편화(external fragmentation)라는 문제를 내포하고 있기 때문입니다. - 외부 단편화가 무엇이며 왜 발생하는지 알아보겠습니다.
아무런 프로세스도 적재되지 않은 상태의 메모리 전체를 그려보면 위 그림과 같이 표현할 수 있습니다. 운영체제(커널) 영역에는 운영체제가 적재되어 있고, 사용자 영역에는 어떠한 프로세스도 적재되어 있지 않습니다.
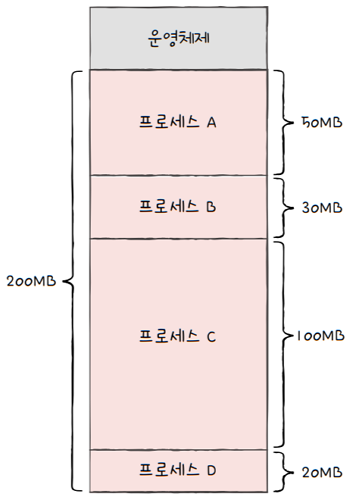
이제 사용자 영역에 하나 둘씩 프로세스들이 적재되는 상황을 상상해 봅시다. (설명의 편의를 위해 사용자 영역의 크기는 200MB이라고 가정)
- 사용자 영역에 크기가 50MB인 프로세스 A
- 30MB인 프로세스 B
- 100MB인 프로세스 C
- 20MB인 프로세스 D를 차례대로 적재해야 한다면,
- 이 프로세스들을 메모리에 어떻게 배치하는 것이 좋을까요?
- 간단히 생각해 보았을 때 다음와 같이 적재할 수 있습니다.
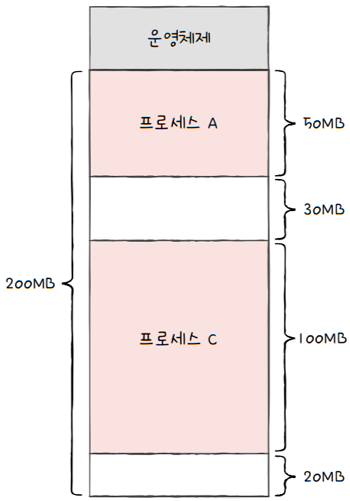
이제 프로세스 B와 D의 실행이 끝났다고 해봅시다.
- 이 프로세스들은 더 이상 메모리에 남아 있을 필요가 없습니다.
- 프로세스 B와 D가 메모리를 떠나면, 위와 같이 프로세스 B와 D가 있던 자리에 는 빈 공간이 생깁니다
여기서 질문을 드리겠습니다. 현재 메모리에 남아 있는 빈 공간의 총합은 몇 MB일까요? 너무 당연 한 질문을 하는 것 같이 느낄 수도 있겠습니다. 답은 50MB입니다.
그렇다면 두 번째 질문을 드리겠습니다. 위 그림과 같은 상황에서 50MB 크기의 프로세스를 적재할 수 있을까요? 답은 불가능합니다. 빈 공간의 총합은 50MB일지라도, 어느 빈 공간에도 50MB 크기의 프로세스가 적재될 수 없기 때문이죠.
1.3.2 개념
프로세스들이 메모리에 연속적으로 할당되는 환경에서는
- 위와 같이 프로세스들이 실행되고 종료되기를 반복하며 메모리 사이 사이에 빈 공간들이 생깁니다.
- 프로세스 바깥에 생기는 이러한 빈 공간들은 분명 빈 공간이지만,
- 그 공간보다 큰 프로세스를 적재하기 어려운 상황을 초래하고,
- 결국 메모리 낭비로 이어집니다.
- 이러한 현상을
외부 단편화(external fragmentation)라고 합니다. - 즉, 외부 단편화 = 프로세스를 할당하기 어려울 만큼 작은 메모리 공간들로 인해 메모리가 낭비되는 현상
1.3.3 예시
실은 앞서 설명한 스와핑과 메모리 할당을 설명한 예시에서도 외부 단편화는 발생했습니다.
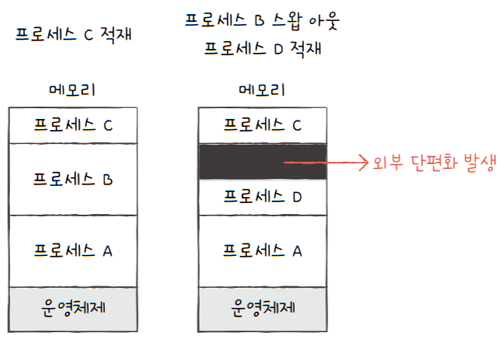
위 그림을 다시보면,
프로세스 B가 스왑 아웃되고,프로세스 B보다 작은 프로세스 D가 적재되었을 때, 외부 단편화가 발생하는 것을 볼 수 있습니다.- cf. 그림에서 검은색으로 칠한 부분이
외부 단편화가 발생한 부분
1.3.4 예시 2
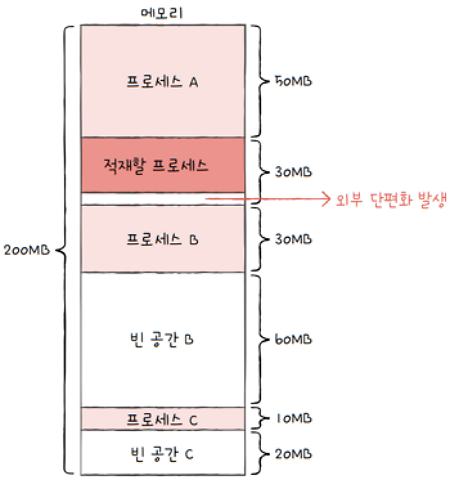
‘적재할 프로세스’ 바로 아래에 작은 빈 공간이 생겼지요? 이 또한 외부 단편화가 발생한 예라고 볼 수 있습니다.
1.4.5 해결방법 : 메모리 압축(compaction)
앞 예시들에서는 메모리에 프로세스가 몇 개 없는 간단한 상황을 가정했기에,
- 외부 단편화가 큰 문제가 아닌 것처럼 보일 수 있지만,
- 실제로는 이보다 메모리 용량도 크고 적재되는 프로세스도 많기 때문에,
- 외부 단편화로 인해 낭비되는 공간은 더욱 큽니다.
- 그렇기에
외부 단편화 문제는 반드시 해결해야 할 문제입니다.
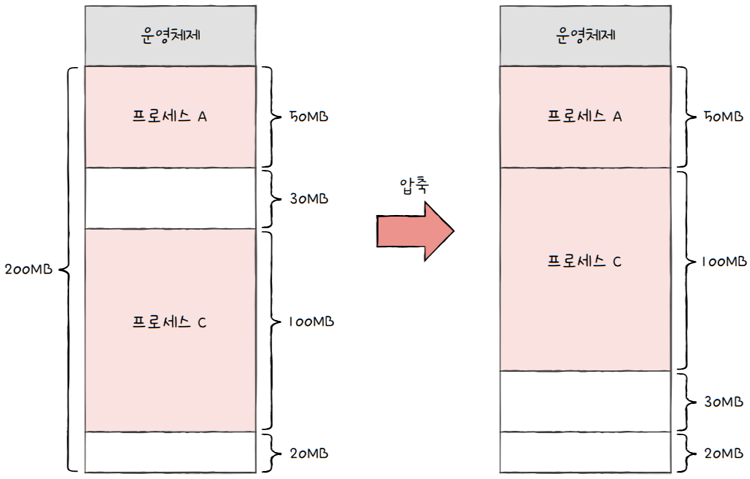
- 외부 단편화를 해결할 수 있는 대표적인 방안 :
메모리 압축(compaction) - cf.
메모리 조각 모음이라고도 부릅니다. - 메모리 내에 저장된 프로세스를 적당히 재배치시켜,
- 여기저기 흩어져 있는 작은 빈 공간들을 하나의 큰 빈 공간으로 만드는 방법
다만 압축 방식은 여러 단점이 있습니다.
- 작은 빈 공간들을 하나로 모으는 동안 시스템은 하던 일을 중지해야 하고,
- 메모리에 있는 내용을 옮기는 작업은 많은 오버헤드를 야기하며,
- 어떤 프로세스를 어떻게 움직여야 오버헤드를 최소화하며,
- 압축할 수 있는지에 대한 명확한 방법을 결정하기 어렵습니다.
그래서 외부 단편화를 없앨 수 있는 또 다른 해결 방안이 등장했는데,
- 이것이 오늘날까지도 사용되는
가상 메모리 기법, 그 중에서도페이징 기법입니다. - 다음 절에서는 페이징에 대해 자세히 알아보 겠습니다.
2. 페이징을 통한 가상 메모리 관리
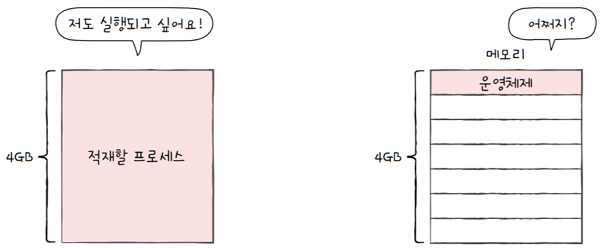
프로세스를 메모리에 연속적으로 할당하는 방식은 2가지 문제를 내포하고 있습니다.
외부 단편화물리 메모리보다 큰 프로세스 실행 불가- e.g. 4GB 메모리가 설치된 컴퓨터로는 4GB 이상의 프로그램을 실행 불가
가상 메모리(virtual memory)
- 실행하고자 하는 프로그램을 일부만 메모리에 적재하여,
- 실제 물리 메모리 크기보다 더 큰 프로세스를 실행할 수 있게 하는 기술
- cf. 가상 메모리 관리 기법에는 크게 페이징과 세그멘테이션이 있지만,
- 이 책에서는 현대 대부분의 운영체제가 사용하는 페이징 기법을 다룹니다.
- 페이징 기법을 이용하면 물리 메모리보다 큰 프로세스를 실행할 수 있을 뿐만 아니라
- 앞선 절에서 배운 외부 단편화 문제도 해결할 수 있습니다.
2.1 페이징(paging)
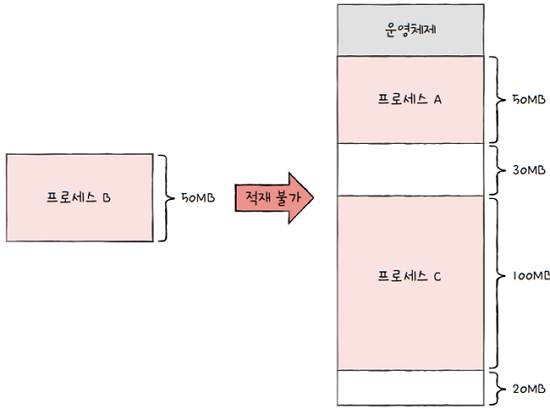
- 연속 메모리 할당 방식에서 외부 단편화가 발생했던 근본적인 문제는?
- 각기 다른 크기의 프로세스가 메모 리에 연속적으로 할당되었기 때문입니다.
만일 메모리와 프로세스를 일정한 단위로 자르고, 이를 메모리에 불연속적으로도 할당할 수만 있다면?
- 외부 단편화는 발생하지 않습니다.
- e.g. 위 그림에서 메모리 공간과 프로세스들을 10MB 단위의 일정한 크기로 자르고,
- 잘린 메모리 조각들에 프로세스 조각들을 불연속적으로 적재할 수 있다면
- 외부 단편화는 발생하지 않습니다.
- 이것이 바로
페이징입니다.
2.1.1 페이징 개념
- 프로세스의 논리 주소 공간을
페이지(page)라는 일정한 단위로 자르고, - 메모리 물리 주소 공간을
프레임(frame)이라는 페이지와 동일한 크기의 일정한 단위로 자른 뒤, - 페이지를 그대로 프레임에 할당하는 가상 메모리 관리 기법
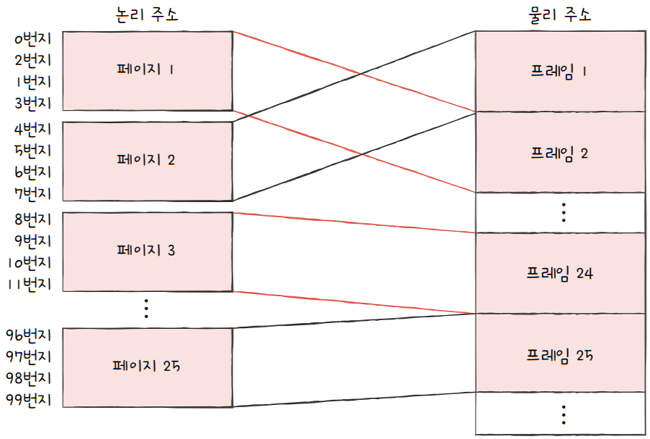
e.g 위 그림을 보면,
- 물리 주소에 적재되는 대상들이 연속 메모리 할당 방식에 비하면,
- 조금 더 균일한 크기를 갖고 있기 때문에,
- 당연하게도 외부 단편화는 발생하지 않습니다.
2.1.2 페이징에서의 스와핑
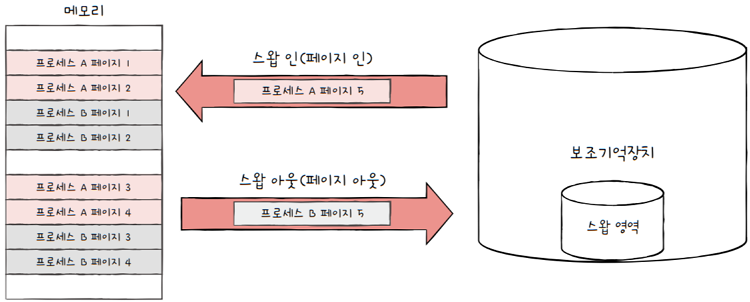
참고로 페이징에서도 스와핑을 사용할 수 있습니다. 페이징에서의 스와핑은
- 프로세스 단위의 스왑 인, 스왓 아웃이 아닌 페이지 단위의
스왑인,스왑 아웃 - 메모리에
- 적재될 필요가 없는 페이지들은 보조기억장치로
스왑 아웃(페이진 인) - 실행에 필요한 페이지들은 메모리로
스왑 인(페이지 아웃)
- 적재될 필요가 없는 페이지들은 보조기억장치로
- cf. 페이징 시스템에서의
- 스왑 아웃은
페이지 아웃(page out), - 스왑 인은
페이지 인(page in)이라고 부르기도 합니다.
- 스왑 아웃은
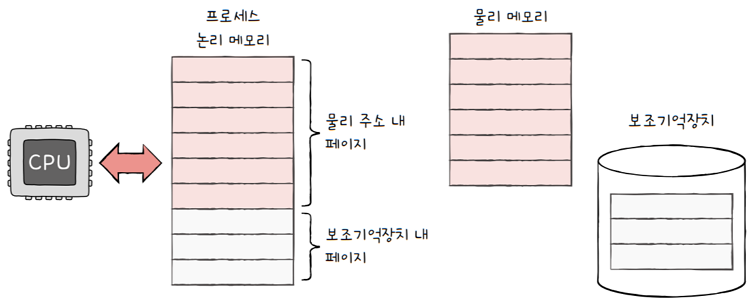
다르게 말하면, **‘한 프로세스를 실행하기 위해 프로세스 전체가 메모리에 적재될 필요가 없다‘**는 말과 같습니다. 프로세스를 이루는 페이지 중 실행에 필요한 일부 페이지만을 메모리에 적재하고, 당장 실행에 필요하지 않은 페이지들은 보조기억장치에 남겨둘 수 있습니다. 이와 같은 방식을 통해 물리 메모리보다 더 큰 프로세스를 실행할 수 있습니다.
2.2 페이지 테이블(page table)
그런데 여기서 문제가 있습니다.
- 프로세스를 이루는 페이지가 어느 프레임에 적재되어 있는지, CPU가 모두 알고 있기란 어렵습니다.
- 프로세스가 메모리에 불연속적으로 배치되어 있다면,
CPU 입장에서 이를 순차적으로 실행할 수가 없습니다.- 즉, 프로세스가 메모리에 불연속적으로 배치되면,
- CPU 입장에서 ‘다음에 실행할 명령어 위치’를 찾기가 어려워집니다.
이를 해결하기 위해 사용되는 개념이 바로 페이징 테이블입니다.
- (실제 메모리 내의 주소인) 물리 주소에 불연속적으로 배치되더라도,
- (CPU가 바라보는 주소인) 논리 주소에는 연속적으로 배치되도록 하는 방법
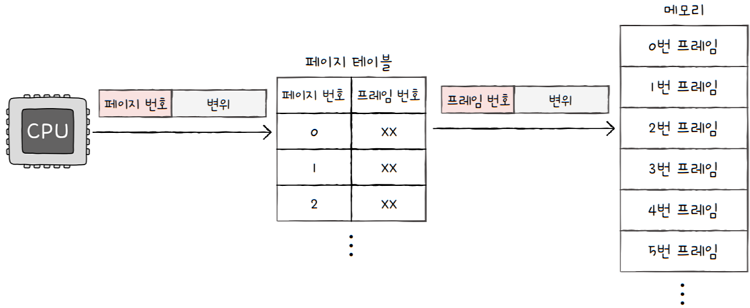
- 페이지 테이블은 페이지 번호와 프레임 번호를 짝지어 주는 일종의 이정표
- CPU로 하여금 페이지 번호만 보고, 해당 페이지가 적재된 프레임을 찾을 수 있게 합니다.
- 다시 말해, 페이지 테이블은 현재 어떤 페이지가 어떤 프레임에 할당되었는지를 알려줍니다.
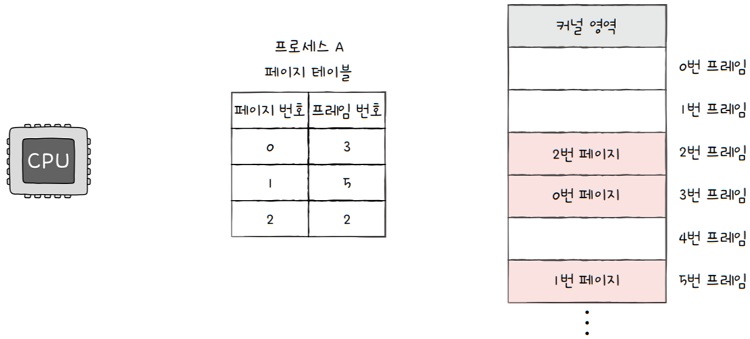
프로세스마다 각자의 프로세스 테이블이 있습니다. e.g. 프로세스 A의 페이지 테이블이 위 그림과 같다면, CPU는 이를 보고,
0번 페이지는 3번 프레임에,1번 페이지는 5번 프레임에,2번 페이지는 2번 프레임에 할당되어 있다’라는 사실을 알 수 있습니다.- 즉, 페이지 테이블의 페이지 번호를 이용해 페이지가 적재된 프레임을 찾을 수 있습니다.
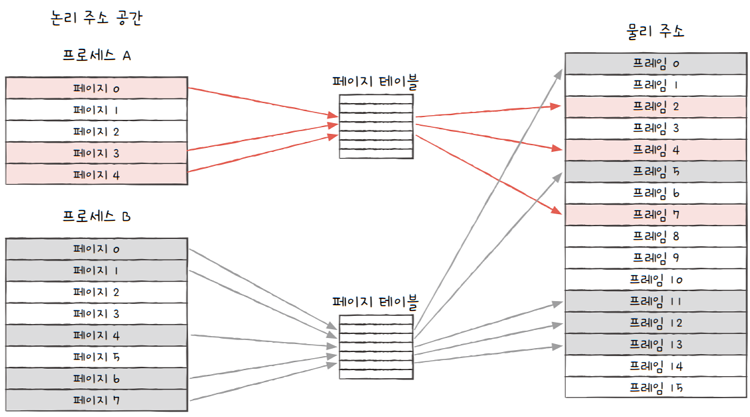
위 그림과 같이
- 물리적으로는 분산되어 저장되어 있더라도, CPU 입장에서 바라본 논리 주소는 연속적으로 보임
CPU는 그저 논리 주소를 순차적으로 실행하기만 하면 됩니다.
💡 내부 단편화(internal fragmentation)
페이징은
외부 단편화문제를 해결할 수 있지만,내부 단편화라는 또 다른 문제를 야기할 수 있습니다.
- 페이징은 프로세스의 논리 주소 공간을
페이지라는 일정한 크기 단위로 자른다고 했습니다.- 그런데 모든 프로세스가 페이지 크기에 딱 맞게 잘리는 것은 아닙니다.
- 다시 말해, 모든 프로세스 크기가 페이지의 배수는 아닙니다.
- e.g.
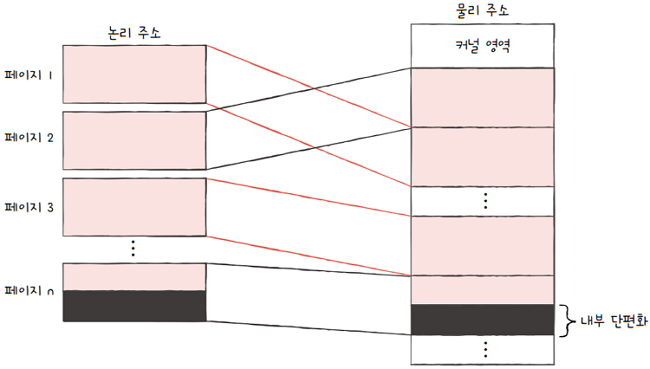
페이지 크기가 10KB인데,프로세스의 크기가 108KB라고 해볼까요?
- 이 경우 마지막 페이지는 2KB만큼의 크기가 남습니다.
- 이러한 메모리 낭비를
내부 단편화라고 합니다.- 즉, 2KB의 내부 단편화가 발생합니다.
내부 단편화는 하나의 페이지 크기보다 작은 크기로 발생합니다.
- 그렇기에 하나의 페이지 크기가 작다면,
- 발생하는 내부 단편화의 크기는 작아질 것으로 기대할 수 있습니다.
- 하지만 하나의 페이지 크기를 너무 작게 설정하면,
- 그만큼 페이지 테이블의 크기도 커지기 때문에, 페이지 테이블이 차지하는 공간이 낭비됩니다.
- 그렇기에 내부 단편화를 적당히 방지하면서,
- 너무 크지 않은 페이지 테이블이 만들어지도록 페이지의 크기를 조정하는 것이 중요합니다.
cf. 리눅스의 경우 아래와 같이 간단한 명령으로 페이지 크기를 알아낼 수 있습니다.
1[root@localhost ~]# getconf PAGESIZE24096cf. 리눅스를 포함한 일부 운영체제에서는
- 위와 같이 기본적으로 설정된 페이지 크기보다 더 큰 크기의 페이지도 일부 허용하며 메모리에 유지하는 경우도 있습니다. 기본적으로 설정된 페이지보다 큰 페이지를 대형 페이지(huge page)라고 합니다.
2.3 PTBR : 프로세스 테이블 베이스 레지스터
프로세스마다 가지고 있는 페이지 테이블 또한 어딘가에 저장되어 있어야 합니다. 그리고 CPU는 각각의 페이지 테이블이 어디에 저장되어 있는지 알아야 합니다.
그래서 각각의 프로세스가 갖고 있는 페이지 테이블이 어디에 저장되어 있는지를 나타내기 위해,
사용되는 특별한 레지스터가 PTBR입니다.
다시 말해, PTBR은 각 프로세스 페이지 테이블이 적재되어 있는 주소를 가리키고 있습니다.
💡 프로세스 테이블 베이스 레지스터(PTBR, Page Table Base Register)
- 프로세스마다 각자의 프로세스 테이블을 가지고 있고,
- 각 프로세스의 페이지 테이블들은 CPU 내의
프로세스 테이블 베이스 레지스터(PTBR)가 가리킵니다.
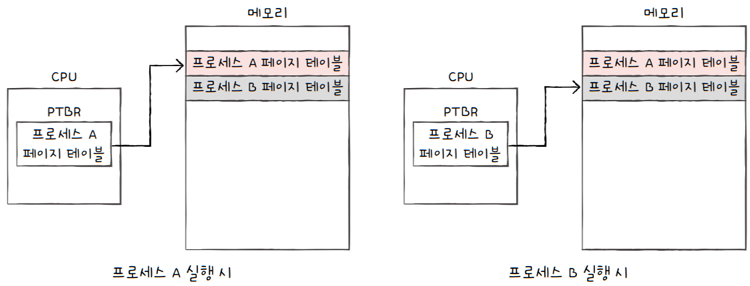
e.g.
프로세스 A가 실행될 때,PTBR은 프로세스 A의 페이지 테이블을 가리키고,CPU는프로세스 A의 페이지 테이블을 통해,프로세스 A의 페이지가 적재된 프레임을 알 수 있습니다.
- 프로세스 B가 실행될 때,
PTBR이 프로세스 B의 페이지 테이블을 가리키고,CPU는프로세스 B의 페이지 테이블을 통해,프로세스 B의 페이지가 적재된 프레임을 알 수 있습니다.
💡 참고
이러한 각 프로세스들의 페이지 테이블 정보들은 각 프로세스의 PCB에 기록됩니다. 그리고 프로세스의 문맥 교환이 일어날 때, 다른 레지스터와 마찬가지로 함께 변경됩니다.
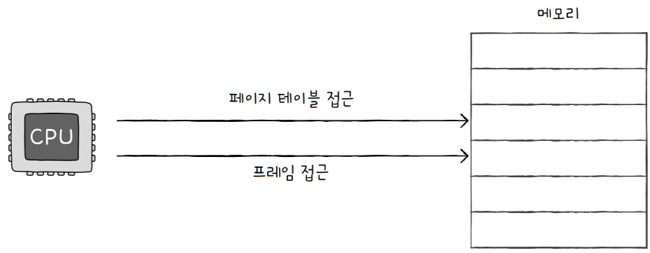
그런데 이렇게 페이지 테이블을 메모리에 두면 문제가 있습니다.
- 페이지 테이블이 메모리에 있으면? 메모리 접근 시간이 2배로
- 메모리에 있는 페이지 테이블을 접근(페이지 테이블 참조) 위해 1번
- 프레임에 접근하기(페이지 참조하기) 위해 1번
2.4 TLB (Translation Lookaside Buffer)
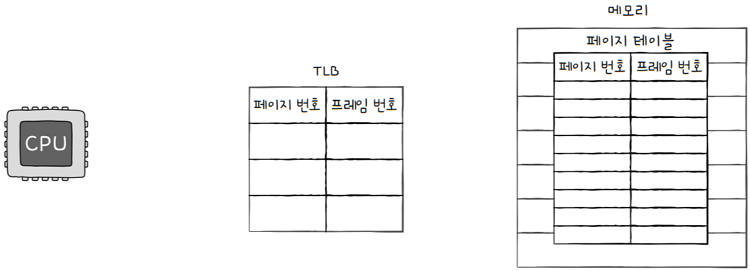
이와 같은 문제를 해결하기 위해 CPU 곁에 TLB라는 페이지 테이블의 캐시 메모리를 둡니다.
TLB: CPU 곁에 페이지 테이블의 캐시 메모리 (일반적으로 CPU의 MMU 내에)- 페이지 테이블의 일부를 가져와 저장
- 참조 지역성에 근거해 주로 최근에 사용된 페이지 위주로 가져와 저장
2.4.1 TLB hit와 TLB miss
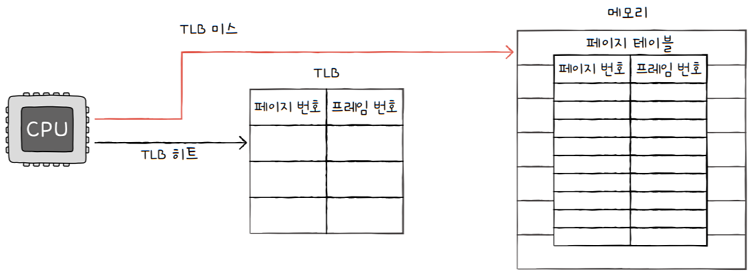
- CPU가 접근하려는 논리 주소가 TLB에 잇다면?
TLB 히트(TLB hit)- 이 경우 페이지가 적재된 프레임을 알기 위해, 메모리에 접근할 필요가 없습니다.
- 그래서 메모리 접근 1번만 하면 됩니다.
- CPU가 접근하려는 논리 주소가 TLB에 없다면?
TLB 미스(TLB miss)- 이 경우 페이지가 적재된 프레임을 알기 위해, 메모리 내의 페이지 테이블에 접근하는 수 밖에 없습니다.
- 그래서 메모리 접근 1번만 하면 됩니다.
2.5 페이징에서의 주소 변환
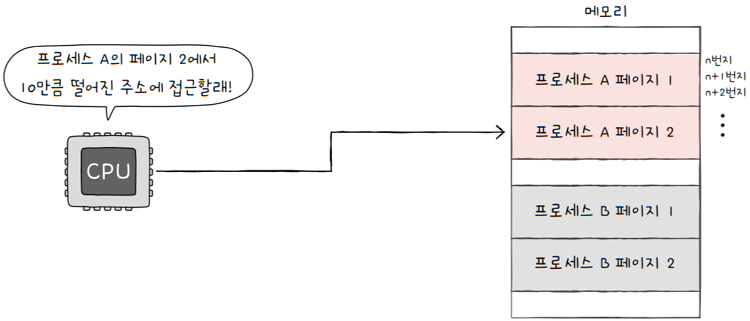
하나의 페이지 혹은 프레임은 여러 주소를 포괄하고 있습니다.
그렇다면, 특정 주소에 접근하고자 한다면, 어떤 정보가 필요할까?
- 어떤 페이지 혹은 프레임에 접근하고 싶은지
- 접근하려는 주소가 그 페이지 혹은 프레임으로부터 얼마나 떨어져 있는지
e.g. 위 그림에 프로세스 A의 페이지 1번에 n+2번지가 포함되어 있고, CPU는 n+2번지에 접근하고 싶다고 가정하면,
- CPU 입장에서 알아야 되는 정보는
- 내가 어떤 페이지, 어떤 프레임에 접근해야 되는지 알아야 되고,
- 그리고 내가 접근하려는 주소가 그 페이지에서 얼마나 떨어져 있는지를 알아야 됩니다.
2.5.1 페이지 번호와 변위

그렇기에 페이징 시스템에서는 모든 논리 주소가
- 기본적으로
페이지 번호(page number)와변위(offset)로 이루어져 있습니다. - e.g. CPU가 32비트 주소를 내보냈다면, 이 중 N비트는 페이지 번호, 32-N비트는 변위, 이런 식
💡 페이지 번호와 변위
페이지 번호
- 말 그대로 접근하고자 하는 페이지 번호
- 페이지 테이블에서 해당 페이지 번호를 찾으면, 페이지가 어떤 프레임에 할당되었는지를 알 수 있음
변위
- 접근하려는 주소가 프레임의 시작 번지로부터 얼만큼 떨어져 있는지를 알기 위한 정보
- 즉, 논리 주소
<페이지 번호, 변위>는 페이지 테이블을 통해 물리 주소<프레임 번호, 변위>로 변환
<페이지 번호, 변위>로 이루어진 논리 주소는페이지 테이블을 통해<프레임 번호, 변위>로 변환된다.- cf. 변환된 물리 주소 ===
<프레임 번호, 변위> - cf. 논리 주소 상의 변위와 물리 주소 상의 변위는 같습니다.
위 과정은 말보다 예제를 통해 이해하는 것이 빠릅니다.
e.g. CPU와 페이지 테이블, 메모리의 상태가 위 그림과 같다고 합니다. 하나의 페이지/프레임이 4개의 주소로 구성되어 있는 간단한 상황을 가정하고,
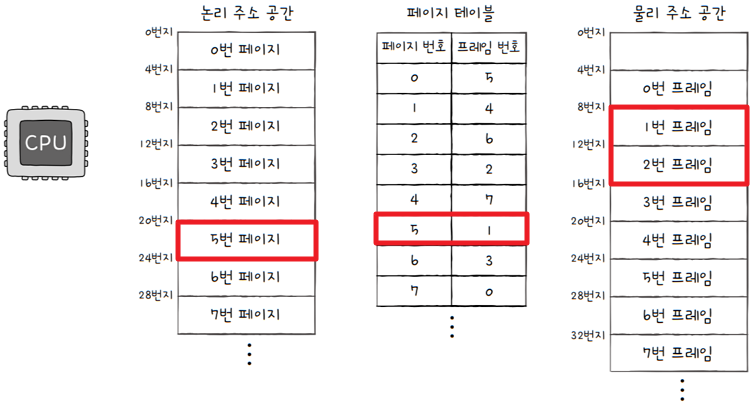
CPU가 5번 페이지, 변위 2라는 논리 주소(<5, 2>)에 접근하고 싶어한다고 가정하면,
- CPU가 접근하게 될 물리 주소는 어디일까요?
- 페이지 테이블을 보면,
5번 페이지는현재 1번 프레임에 있습니다. - 그렇다면
CPU는 1번 프레임, 변위 2에 접근하게 됩니다. 1번 프레임은 8번지부터 시작하지요? 즉,CPU는 10번지에 접근하게 됩니다.
2.6 페이지 테이블 엔트리(PTE)
페이지 테이블을 조금 자세히 들여다봅시다.
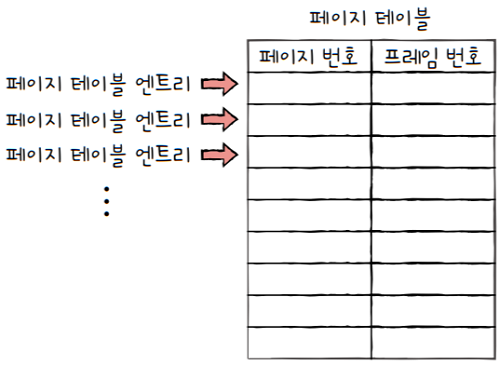
- 페이지 테이블의 각 엔트리,
- 다시 말해, 페이지 테이블의 각각의 행들을
페이지 테이블 엔트리(PTE; Page Table Entry)라고 합니다.
지금까지는 페이지 테이블 엔트리에 담기는 정보로 페이지 번호, 프레임 번호만을 설명했지만,
- 실은 페이지 테이블 엔트리에는 이외에도 다른 중요한 정보들이 있습니다.
- 대표적인 것이
유효 비트,보호 비트,참조 비트,수정 비트입니다. - cf. 구체적인 정보들은 운영체제마다 다를 수 있습니다.
- 그래서 대표적이고 핵심적인 것들만 배웁니다.
2.6.1 유효 비트(valid bit)
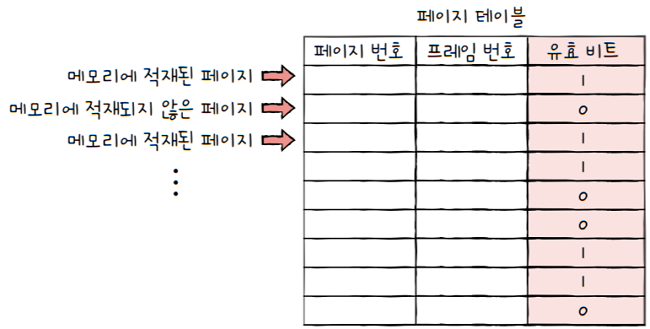
유효 비트: 현재 해당 페이지에 접근 가능한지 여부를 표시해주는 비트- 페이지 테이블 엔트리에서 프레임 번호 다음으로 중요한 정보
- 페이지가 스왑 영역에 있는지 아닌지 여부를 표시
- 페이지가 메모리에 적재되어 있다면,
유효 비트가 1 - 페이지가 메모리에 적재되어 있지 않다면(보조 기억장치),
유효 비트가 0
- 페이지가 메모리에 적재되어 있다면,
만일 CPU가 유효 비트가 0인 메모리에 적재되어 있지 않은 페이지로 접근하려고 하면?
페이지 폴트(page fault)라는 인터업트가 발생합니다.
CPU가 페이지 폴트를 처리하는 과정은 하드웨어 인터럽트를 처리하는 과정과 똑같이 처리됩니다.
- CPU는 기존의 작업 내역을 백업합니다.
- 페이지 폴트 처리 루틴을 실행합니다.
- 페이지 처리 루틴은 원하는 페이지를 메모리로 가져온 뒤 유효 비트를 1로 변경해 줍니다.
- 페이지 폴트를 처리했다면, 이제 CPU는 해당 페이지에 접근할 수 있게 됩니다.
2.6.2 보호 비트(protection bit)
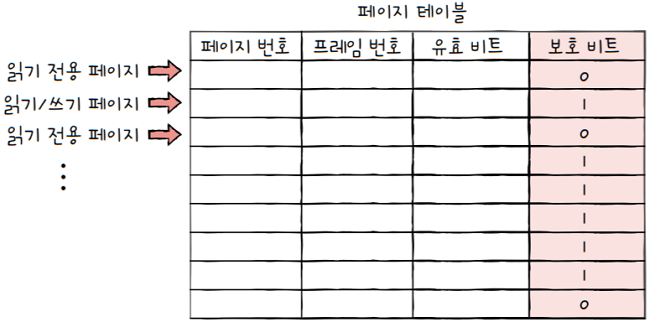
보호 비트: 페이지 보호 기능을 위해 존재하는 비트- 해당 페이지가 읽고 쓰기가 모두 가능한 페이지인지, 혹은 읽기만 가능한 페이지인지 표시해줌
- 해당 페이지는 읽기만 가능한 페이지면, 보호 비트가 0
- 해당 페이지는 읽고 쓰기가 모두 가능한 페이지면, 보호 비트가 1
앞서 프로세스를 이루는 요소 중 코드 영역은 읽기 전용 영역이라고 설명한 것을 기억하나요?
이러한 읽기 전용 페이지에 쓰기를 시도하면, 운영체제가 이를 막아줍니다.
이와 같은 방식으로 페이지들을 보호합니다.
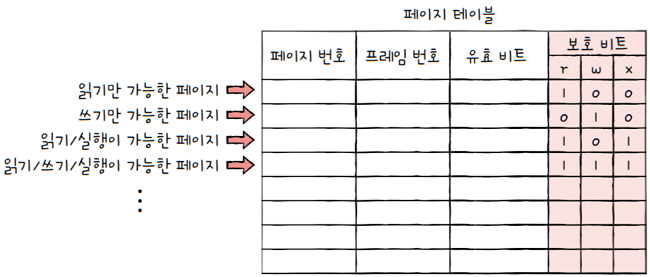
보호 비트는 3개의 비트로 조금 더 복잡하게 구현할 수도 있습니다.
읽기(Read)를 나타내는r쓰기(Write)를 나타내는w실행(eXecute)을 나타내는x의 조합으로- 읽기, 쓰기, 실행하기 권한의 조합을 나타낼 수도 있습니다.
- e.g.
- 보호 비트가 100으로 설정된 페이지의 경우
r은 1,w와 x는 0이므로 이 페이지는 읽기만 가능합니다.
- 보호 비트가 110으로 설정된 페이지의 경우
- 이 페이지는 읽고 쓰기만 가능하고 실행은 불가능합니다.
- 보호 비트가 111로 설정된 페이지는 읽기, 쓰기, 실행이 모두 가능합니다.
- 보호 비트가 100으로 설정된 페이지의 경우
2.6.3 참조 비트(reference bit)
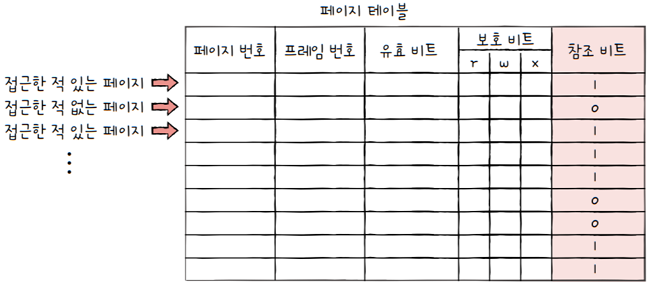
참조 비트: CPU가 이 페이지에 접근한 적이 있는지 여부- 적재 이후 CPU가 읽거나 쓴 페이지는
참조 비트가 1로 세팅되고, - 적재 이후 한 번도 읽거나 쓴 적이 없는 페이지는
참조 비트가 0으로 유지됩니다.
2.6.4 수정 비트(modified bit)
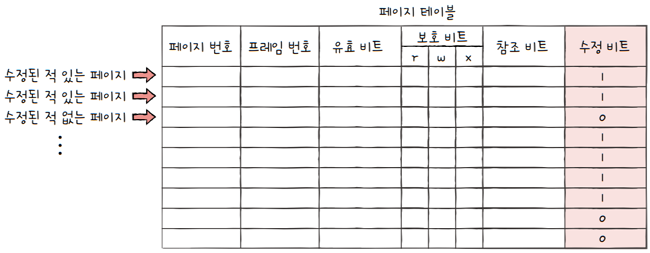
수정 비트: 해당 페이지에 데이터를 쓴 적이 있는지 없는지 수정 여부- cf.
더티 비트(dirty bit)라고도 부르지요. - 변경된 적이 있는 페이지면,
수정 비트가 1 - 변경된 적이 없는 페이지(한 번도 접근한 적 없거나 읽기만 했던 페이지)이면,
수정 비트가 0
수정 비트는 왜 존재하는 것일까요? 바로 스와핑과 관련있습니다.
수정 비트는 페이지가 메모리에서 사라질 때,- 보조기억장치에 쓰기 작업을 해야 하는지,
- 할 필요가 없는지를 판단하기 위해 존재합니다.
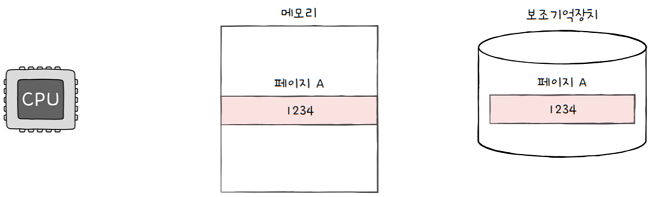
CPU는 메모리를 읽기도 하지만, 메모리에 값을 쓰기도 합니다.
CPU가 한 번도 접근하지 않았거나 읽기만 한 페이지의 경우- 보조기억장치에 저장된 해당 페이지의 내용과 메모리에 저장된 페이지 내용은
- 위 그림과 같이 서로 같은 값을 가지고 있습니다.
- 이렇게 한 번도 수정된 적이 없는 페이지가 스왑 아웃될 경우
- 아무런 추가 작업없이 새로 적재된 페이지로 덮어쓰기만 하면 됩니다.
- 어차피 똑같은 페이지가 보조기억장치에 저장되어 있으니까요.
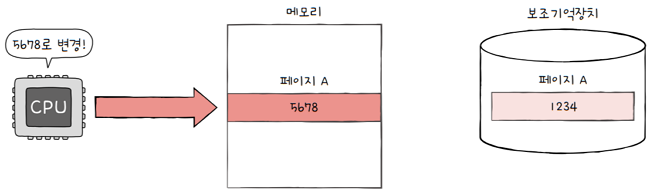
- 하지만
CPU가 쓰기 작업을 수행한 페이지(수정 비트가 1인 페이지)의 경우- 보조기억장치에 저장된 페이지의 내용과 메모리에 저장된 페이지의 내용은
- 서로 다른 값을 갖게 됩니다.
- 이렇게 수정된 적이 있는 페이지가 스왑 아웃될 경우
- 변경된 값을 보조기억장치에 기록하는 작업이 추가되어야 합니다.
- 필요한 페이지인지 아닌지를 판단하기 위해, 페이지 테이블 엔트리에 수정 비트를 두는 것입니다.
💡 심화 내용 참고
많은 전공서는 지금까지 설명한 정도로만 페이지 테이블 엔트리를 설명하지만, 실제 페이지 테이블 엔트리에는 이외에도 다양한 정보가 있습니다. 페이지 테이블에 무엇이 저장되는지만 알아도, 실제로 CPU가 메모리에 어떻게 접근하며 가상 메모리를 어떻게 다루는지 알 수 있습니다. 관심있는 독자 들은 아래 링크 page_table 항목을 참고하기 바랍니다
2.7 페이징의 이점 - 쓰기 시 복사
외부 단편화 문제를 해결한다는 점 이외에도 페이징이 제공하는 이점은 다양합니다.
- 대표적인 것이 **‘프로세스 간에 페이지를 공유할 수 있다‘**는 점입니다.
- 프로세스 간 페이지를 공유하는 사례로는 공유 라이브러리 등 다양하지만,
- 대표적인 예시로
쓰기 시 복사(copy on write)가 있습니다.
10장에서 멀티프로세스를 설명했을 때, 다음과 같은 내용을 배웠습니다.
프로세스를 fork하여 동일한 프로세스 2개가 복제되면,- 코드 및 데이터 영역을 비롯한 모든 자원이 복제되어 메모리에 적재된다
- 프로세스를 통째로 메모리에 중복 저장하지 않으면서,
- 프로세스끼리 자원을 공유하지 않는 방법도 있다
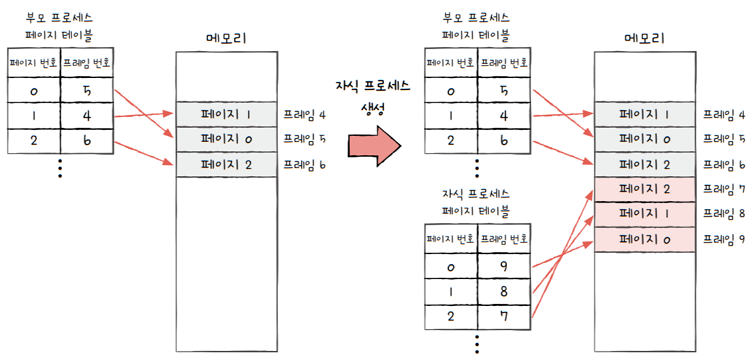
유닉스나 리눅스와 같은 운영체제에서 fork 시스템 호출을 하면,
부모 프로세스의 복사본이자식 프로세스로서 만들어집니다.- **‘프로세스 간에는 기본적으로 자원을 공유하지 않는다’**는 프로세스의 전통적인 개념에 입각하면,
- 새롭게 생성된
자식 프로세스의 코드 및 데이터 영역은 부모 프로세스가 적재된 메모리 공간과는 전혀 다른 메모리 공간에 생성됩니다.
- 새롭게 생성된
- 한 마디로
부모 프로세스의 메모리 영역이 다른 영역에자식 프로세스로서 복제되고,- 각 프로세스의 페이지 테이블은 자신의 고유한 페이지가 할당된 프레임을 가리키지요.
- 하지만 이 복사 작업은 프로세스 생성 시간을 늦출 뿐만 아니라, 불필요한 메모리 낭비를 야기합니다.
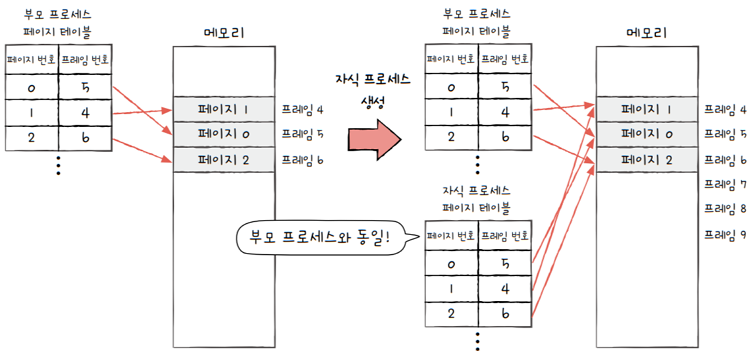
반면 쓰기 시 복사에서는 부모 프로세스와 동일한 자식 프로세스가 생성되면,
- 위 그림과 같이
자식 프로세스로 하여금부모 프로세스와 동일한 프레임을 가리킵니다.- 이로써 굳이
부모 프로세스의 메모리 공간을 복사하지 않고도 - 동일한 코드 및 데이터 영역을 가리킬 수 있습니다.
- 이로써 굳이
- 만일
부모 프로세스와자식 프로세스가 메모리에 어떠한 데이터도 쓰지 않고,- 그저 읽기 작업만 이어 나간다면 이 상태가 지속됩니다.
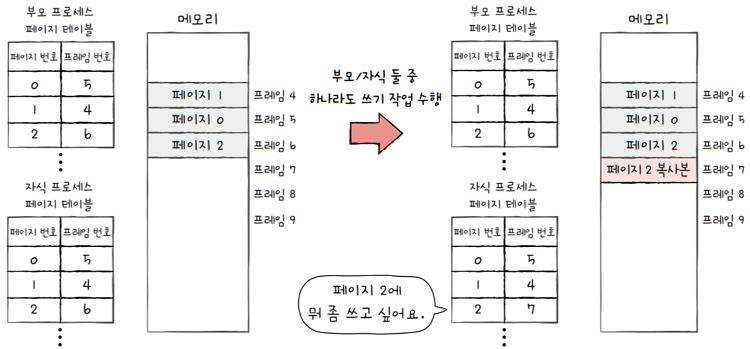
그런데 **‘프로세스 간에는 자원을 공유하지 않는다’**고 했죠?
부모 프로세스혹은자식 프로세스둘 중 하나가 페이지에 쓰기 작업을 하면,- 그 순간 해당 페이지가 별도의 공간으로 복제됩니다.
각 프로세스는 자신의 고유한 페이지가 할당된 프레임을 가리키지요.- 이것이
쓰기 시 복사입니다.
- 이러한
쓰기 시 복사를 통해 프로세스 생성 시간을 줄이는 것은 물론, 메모리 공간 절약도 가능합니다.
2.8 계층적 페이징(hierarchical paging)

페이지 테이블의 크기는 생각보다 작지 않습니다.
프로세스의 크기가 커지면, 자연히프로세스 테이블의 크기도 커지기 때문에,- 프로세스를 이루는
모든 페이지 테이블 엔트리를 메모리에 두는 것은 큰 메모리 낭비입니다. - 그래서 프로세스를 이루는 모든 페이지 테이블 엔트리를
- 항상 메모리에 유지하지 않을 수 있는 방법이 등장했는데,
- 이것이
계층적 페이징입니다.
계층적 페이징은 페이지 테이블을 페이징하여 여러 단계의 페이지를 두는 방식입니다.
- **‘여러 단계의 페이지를 둔다’**는 점에서
다단계 페이지 테이블(multilevel page table) 기법이라고도 부름 프로세스의 페이지 테이블을 여러 개의 페이지로 자르고,- 바깥쪽에 페이지 테이블을 하나 더 두어, 잘린 페이지 테이블의 페이지들을 가리키게 하는 방식
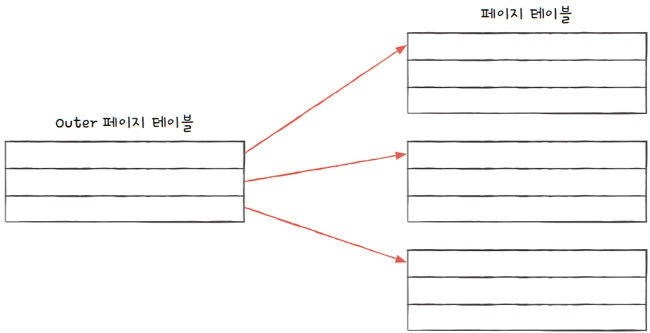
말이 조금 헷갈리지요? 간단합니다. 한 프로세스의 페이지 테이블이 위 그림과 같다고 가정해 봅시다.
- 계층적 페이징 기법을 사용하지 않으면, 이 프로세스 테이블은 전체가 메모리에 있어야 합니다.
이 페이지 테이블을 여러 개의 페이지로 쪼개고,- 이 페이지들을 가리키는 페이지 테이블(그림 속 Outer 페이지 테이블)을 두는 방식이
계층적 페이징입니다.
페이지 테이블을 계층적으로 구성하면, 모든 페이지 테이블을 항상 메모리에 유지할 필요가 없습니다.
페이지 테이블들 중 몇 개는 보조기억장치에 있어도 무방하며,- 추후 해당 페이지 테이블을 참조해야 할 때가 있으면 그때 메모리에 적재하면 그만입니다.
- 막대한 크기의 페이지 테이블로 인해 낭비되는 공간을 줄일 수 있겠죠?
- cf. 다만 CPU와 가장 가까이 위치한 페이지 테이블(Outer 페이지 테이블)은 항상 메모리에 유지해야 합니다.
계층적 페이징을 사용하는 경우 CPU가 발생하는 논리 주소도 달라집니다.

계층적 페이징을 사용하지 않을 경우, 논리 주소는 앞서 학습했듯이 위 그림과 같은 형태로 만들어집니다.

하지만 계층적 페이징을 이용하는 환경에서의 논리 주소는 위와 같은 형태로 만들어집니다.
바깥 페이지 번호는- CPU와 근접한 곳에 위치한(바깥에 위치한) 페이지 테이블 엔트리를 가리키고,
안쪽 페이지 번호는 첫 번째 페이지 테이블 바깥에 위치한 두 번째 페이지 테이블,- 즉, 페이지 테이블의 페이지 번호를 가리킵니다
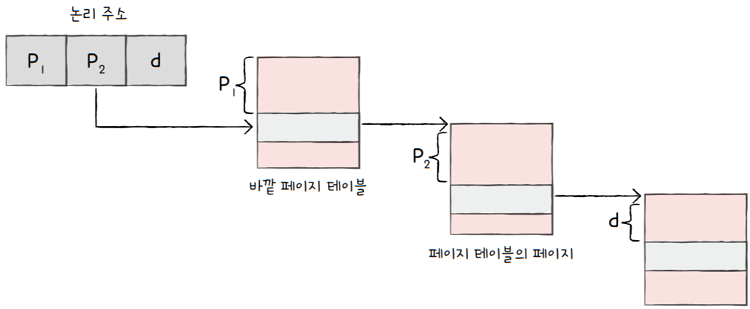
이러한 논리 주소를 토대로 주소 변환은 다음과 같이 이루어집니다.
- 바깥 페이지 번호를 통해, 페이지 테이블의 페이지를 찾기
- 페이지 테이블의 페이지를 통해, 프레임 번호를 찾고 변위를 더함으로서 물리 주소 얻기
위에서는 2개의 계층으로 페이지 테이블을 구성하는(2단계 페이징) 예시를 들었으나
- 페이지 테이블의 계층은 3개, 4개, 그 이상의 계층으로도 구성될 수 있습니다.
- 다만 페이지 테이블의 계층이 늘어날수록,
- 페이지 폴트가 발생했을 경우 메모리 참조 횟수가 많아지므로,
- 계층이 많다고 해서 반드시 좋다고 볼 수는 없습니다.
3. 페이지 교체와 프레임 할당
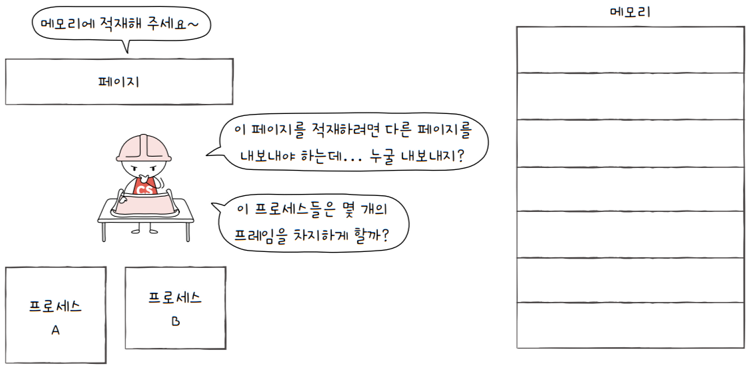
가상 메모리를 통해, 작은 물리 메모리보다 큰 프로세스도 실행할 수 있다고는 하지만, 그럼에도 불구하고 여전히 물리 메모리의 크기는 한정되어 있습니다.
운영체제 입장에서는 다음 2가지 문제를 반드시 해결해야 합니다.
- 기존에 메모리에 적재된 불필요한 페이지를 선별해 보조기억장치로 내보내고,
- 이 문제를 해결할 수 있는 방식이
페이지 교체 알고리즘입니다.
- 이 문제를 해결할 수 있는 방식이
- 프로세스들에게 적절한 수의 프레임을 할당해야 함
- 이 문제를 해결할 수 있는 방식이
프레임 할당입니다.
- 이 문제를 해결할 수 있는 방식이
페이지 교체와 페이지 할당을 본격적으로 학습하기 이전에, 꼭 알아야 용어가 있습니다.
그게 바로 요구 페이징입니다.
3.1 요구 페이징(demand paging)
프로세스를 메모리에 적재할 때,
- 처음부터 모든 페이지를 적재하지 않고, 필요한 페이지만을 메모리에 적재하는 기법
- 실행에 요구되는 페이지만 적재하는 기법
요구 페이징의 기본적인 양상은 다음과 같습니다.
CPU가 특정 페이지에 접근하는 명령어를 실행한다.- 해당 페이지가 현재 메모리에 있을 경우(유효 비트가 1일 경우) CPU는 페이지가 적재된 프레임에 접근한다.
- 해당 페이지가 현재 메모리에 없을 경우(유효 비트가 0일 경우) 페이지 폴트가 발생한다.
페이지 폴트 처리 루틴은 해당 페이지를 메모리로 적재하고, 유효 비트를 1로 설정한다.- 다시 1 번을 수행한다.
💡 참고 : 순수 요구 페이징(pure demand paging) 기법
- 아무런 페이지도 메모리에 적재하지 않은 채, 무작정 실행부터 해버리는 방법
- 이 경우 프로세스의 첫 명령어를 실행하는 순간부터 페이지 폴트가 계속 발생하게 되고,
- 실행에 필요한 페이지가 어느 정도 적재된 이후부터는, 페이지 폴트 발생 빈도가 떨어집니다.
다시 요구 페이징 이야기로 돌아와서, 위와 같은 요구 페이징 시스템이 안정적으로 작동하려면, 필연적으로 다음 2가지를 해결해야 합니다.
- 페이지 교체
- 프레임 할당
3.2 페이지 교체 알고리즘
요구 페이징 기법으로 페이지들을 적재하다 보면, 언젠가 메모리가 가득 차게 됩니다.
- 당장 실행에 필요한 페이지를 적재하려면,
적재된 페이지를보조기억장치로 내보내야 - 이떄, 메모리에 저재된 많은 페이지들 중에서 어떤 페이지를 내보낼까?
- 이를 결정하는 방법(알고리즘)이
페이지 교체 알고리즘
좋은 페이지 교체 알고리즘은 무엇일까요?
- 페이지 폴트를 가장 적게 일으키는 알고리즘을 좋은 알고리즘으로 평가합니다.
- 왜냐하면 페이지 폴트가 발생하면,
- 보조기억장치로부터 필요한 페이지를 가져와야 해서,
- 메모리에 적재된 페이지를 가져오는 것보다 느립니다.
그렇다면 페이지 폴트가 적게 일어났는지 알려면, 페이지 폴트의 횟수를 알 수 있어야 합니다.
-
페이지 폴트 횟수는 어떻게 알 수 있을까?
-
페이지 참조열(page reference string)을 통해 알 수 있습니다.- CPU가 참조하는 페이지들 중 연속된 페이지를 생략한 페이지열
-
e.g. CPU가 아래와 같은 순서로 페이지에 접근했다고 가정
2 2 2 3 5 5 5 3 3 7- 2번 페이지, 2번 페이지, 2번 페이지, 3번 페이지 순, …
- 이 중에서 연속된 페이지를 생략한,
2 3 5 3 7를 페이지 참조열이라고 합니다.
-
연속된 페이지를 생략하는 이유는
-
중복된 페이지를 참조하는 행위는 페이지 폴트를 발생시키지 않기 때문입니다.
-
어차피 연속되는 것에 접근을 하면,
-
이미 페이지 볼트 처리 루틴이 끝난 직후에 처리가 되기 때문에,
-
연속된 페이지가 있다고 해서, 여기서 페이지 폴트를 발생시킬 이유는 없습니다.
-
2 2 2 3 5 5 5 3 3 7- 만약에 5번에서 처음 페이지 폴트가 발생했다면,
- 맨 처음 5번을 가져왔으니, 이후 5번 페이지에서는 페이지 폴트가 발생하지 않겠죠?
-
이런 식으로 연속된 페이지에 대해 페이지 폴트는 발생하지 않기 때문에
-
연속된 페이지를 생략한 페이지 열을
페이지 참조열로 간주합니다.
-
자, 이제 대표적인 페이지 교체 알고리즘에 대해 하나씩 알아보고, 페이지 참조열을 바탕으로 각 알고리즘들의 성능을 평가해 봅시다.
3.2.1 FIFO 페이지 교체
FIFO 페이지 교체 알고리즘(First-In First-Out Page Replacement Algorithm)
- 가장 단순한 방식
- 메모리에 가장 먼저 올라온 페이지부터 내쫓는 방식
- 쉽게 말해 “오래 머물렀다면 나가라”는 알고리즘
e.g. 프로세스가 사용할 수 있는 프레임이 3개 있다고 가정하고, 페이지 참조열이 아래와 같다고 해 봅시다.
2 3 1 3 5 2 3 4 2 3
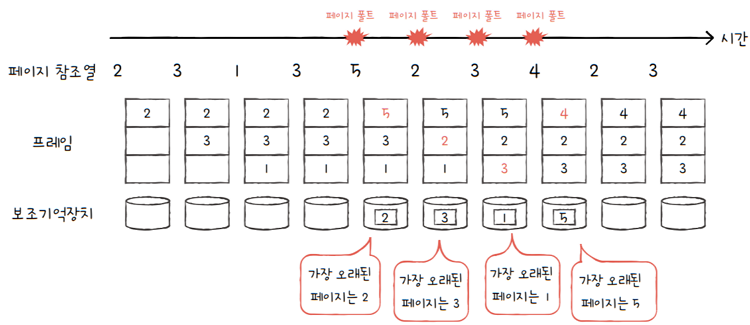
- FIFO 페이지 교체 알고리즘은 위와 같은 순서대로 진행되어
총 4번의 페이지 폴트가 발생합니다. - 메모리에 가장 오랫동안 머물렀던 페이지를 내쫓습니다.
- cf. 페이지가 초기에 적재될 때, 발생할 수 있는 페이지 폴트는 고려하지 않고,
- 적재된 페이지를 교체하기 위해, 발생한 페이지 폴트만을 페이지 폴트로 간주했습니다.
FIFO 페이지 교체 알고리즘은 아이디어와 구현이 간단하지만, 마냥 좋은 것은 아닙니다.
- 프로그램 실행 초기에 적재된 페이지 속에는
- 프로그램 실행 초기에 잠깐 실행되다가 이후에 사용되지 않을 페이지도 있겠지만,
- 프로그램 실행 내내 사용될 내용을 포함하고 있을 수도 있습니다.
- 이런 페이지는 메모리에 먼저 적재되었다고 해서 내쫓아서는 안 되겠죠.
- 그래서 이런 문제점을 보완한 변형 버전이 2차 기회 페이지 교체 알고리즘입니다.
💡 2차 기회 페이지 교체 알고리즘(second chance page replacement algorithm)
FIFO 페이지 교체 알고리즘은
- 자주 참조되는 페이지가 먼저 적재되었다는 이유만으로 내쫓길 수 있다는 문제가 있었습니다.
2차 기회 페이지 교체 알고리즘은
- FIFO 페이지 교체 알고리즘의 부작용을 어느정도 개선한 FIFO 페이지 교체 알고리즘의 변형입니다.
- 이름 그대로 한 번 더 기회를 주는 알고리즘이지요.
2차 기회 페이지 교체 알고리즘은FIFO 페이지 교체 알고리즘과 같이
- 기본적으로 메모리에서 가장 오래 머물렀던 페이지를 대상으로 내보낼 페이지를 선별합니다.
- 차이가 있다면,
페이지의 참조 비트가 1일 경우,
- 당장 내쫓지 않고 참조 비트를 0으로 만든 뒤 현재 시간을 적재 시간으로 설정합니다.
- 메모리에 가장 오래 머물렀다고 할지라도,
- 참조 비트가 1이라는 의미는 CPU가 접근한 적이 있다는 의미이므로
- 한 번의 기회를 더 주는 셈이지요.
- 메모리에 가장 오래 머무른
페이지의 참조 비트가 0일 경우
- 이 페이지는 가장 오래된 페이지이면서, 동시에 사용되지 않은 페이지라고 볼 수 있으므로
- 보조기억 장치로 내보내면 됩니다.
e.g. 5개의 프레임을 가진 메모리에 페이지가
3, 1, 5, 2, 4순으로 적재되었고, 각각의 참조 비트가 다음 그림과 같다고 가정
이런 상황에서
페이지 6이 새롭게 적재되어야 한다면?
FIFO 페이지 교체 알고리즘이었다면, 보조기억장치로 내보낼 페이지는페이지 3입니다.- 하지만
2차 기회 페이지 교체 알고리즘은페이지 3의 참조 비트를 보고,
- 1일 경우 이를 0으로 변경한 뒤 최근에 적재된 페이지로 간주합니다.
- 한 번의 기회를 더 주는 것이지요.
- 그래서 다음 그림처럼 최근에 적재된 페이지로 맨 뒤로 보냅니다.
다음으로 가장 오랫동안 메모리에 머물렀던 페이지는
페이지 1입니다.
참조 비트가 0이군요.- 즉,
페이지 1은 오랫동안 메모리에 머물러 있었으면서, 동시에 CPU가 접근하지 않은 페이지인 셈입니다.- 이 경우
페이지 1을 내보내고,페이지 1이 적재되었던 프레임에페이지 6을 적재하면 됩니다.


3.2.2 최적 페이지 교체
최적 페이지 교체 알고리즘(optimal page replacement algorithm)
- CPU에 의해 참조되는 횟수를 고려
- 메모리에 오랫동안 남아야 할 페이지는 자주 사용될 페이지
- 메모리에 없어도 될 페이지는 오랫동안 사용되지 않을 페이지
- 따라서 오랜 기간 메모리에 있었던 페이지라고 해서, 보조기억장치로 내쫓는 건 비합리적
- 보조기억장치로 내보내야 할 페이지는 앞으로 사용 빈도가 가장 낮은 페이지인 것이 합리적
- 즉, 최적 페이지 교체 알고리즘 === 앞으로의 사용 빈도가 가장 낮은 페이지를 교체하는 알고리즘
e.g. 위에서 들었던 예시를 다시 가져와 보겠습니다.
프로세스가 사용할 수 있는 프레임이 3개 있고, 페이지 참조열이 2 3 1 3 5 2 3 4 2 3와 같습니다.
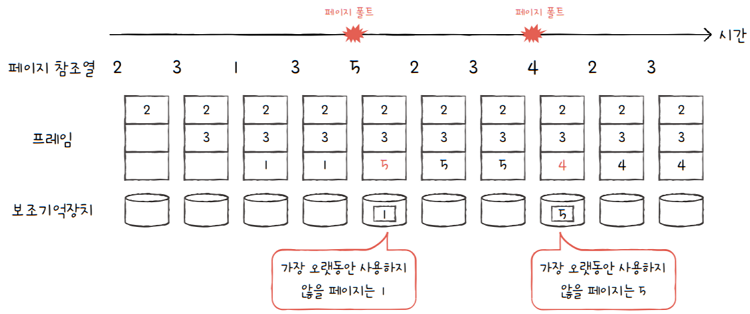
최적 페이지 교체 알고리즘은 위 그림과 같이, 총 2번의 페이지 폴트가 발생합니다.
- FIFO 알고리즘에 비하면, 페이지 폴트 빈도가 훨씬 낮아진 것을 확인할 수 있죠.
최적 페이지 교체 알고리즘은
- 가장 낮은 페이지 폴트율을 보장하는 페이지 교체 알고리즘
- 그래서, 타 페이지 교체 알고리즘에 비해, 페이지 폴트 발생 빈도가 가장 낮습니다
- But, 실제 구현이 어렵다.
- “앞으로 오랫동안 사용되지 않을 페이지를 어떻게 예측하지?”
- 프로세스가 앞으로 메모리 어느 부분을 어떻게 참조할지 미리 알아야 하는데,
- 이는 현실적으로 불가능
- 그 자체를 운영체제에서 사용하기보다는,
- 주로 다른 페이지 교체 알고리즘의 이론상 성능을 평가하기 위한 목적으로 사용
- 최적 페이지 교체 알고리즘을 실행했을 때,
- 발생하는 페이지 폴트 횟수를 페이지 폴트의 하한선으로 간주하고,
- 최적 페이지 교체 알고리즘에 비해,
- 얼만큼 페이지 폴트 횟수가 발생하느냐를 통해 페이지 교체 알고리즘을 평가
3.2.3 LRU 페이지 교체
최적 페이지 교체 알고리즘은 구현하기 어려워도 이와 비슷한 알고리즘은 만들 수 있습니다.
LRU 페이지 교체 알고리즘(LRU; Least Recently Used Page Replacement Algorithm)
최적 페이지 교체: 가장 오랫동안 사용되지 ‘않을’ 페이지를 교체LRU 페이지 교체: 가장 오랫동안 사용되지 ‘않은’ 페이지를 교체- “최근에 사용되지 않은 페이지는 앞으로도 사용되지 않을까?”란 아이디어에서 출발
예시를 다시 한번 가져와 보겠습니다. 페이지 참조열이 2 3 1 3 5 2 3 4 2 3와 같다면,
LRU 알고리즘은 다음과 같이 작동합니다.
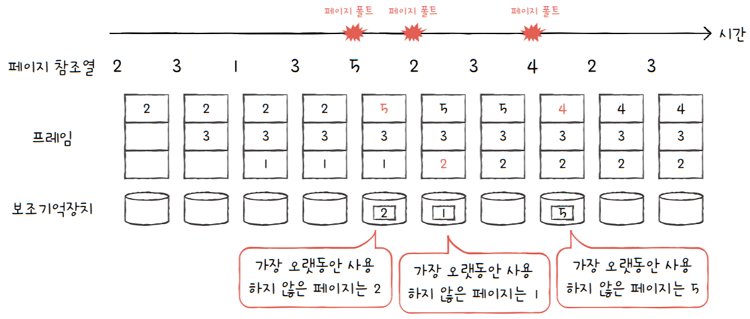
- 페이지 폴트가 3회 발생했습니다.
이외에도 페이지 교체 알고리즘의 종류는 매우 다양합니다.
- 바로 위에서 설명한 LRU 페이지 교체 알고리즘만 하더라도, 많은 파생 알고리즘이 있습니다.
- 다만 페이지 교체 알고리즘을 처음 접한 독자라면,
- 페이지 교체 알고리즘을 단순 암기하기보다는
- 페이지 교체 알고리즘을 왜 사용하는지,
- 무엇이 좋은 페이지 교체 알고리즘인지,
- 대표적인 페이지 교체 알고리즘들의 기본적인 아이디어는 무엇인지를 이해하는 데에 중점을 두길 권합니다.
3.3 스래싱과 프레임 할당
페이지 폴트가 자주 발생하는 이유는 나쁜 페이지 교체 알고리즘만 있는 건 아닙니다.
- 나쁜 페이지 교체 알고리즘을 사용해서
- 프로세스가 사용할 수 있는 프레임 수가 적어도, 페이지 폴트는 자주 발생합니다.
- (사실 이것이 더 근본적인 이유)
- 반대로 프로세스가 사용할 수 있는 프레임 수가 많으면, 일반적으로 페이지 폴트 빈도는 감소합니다.
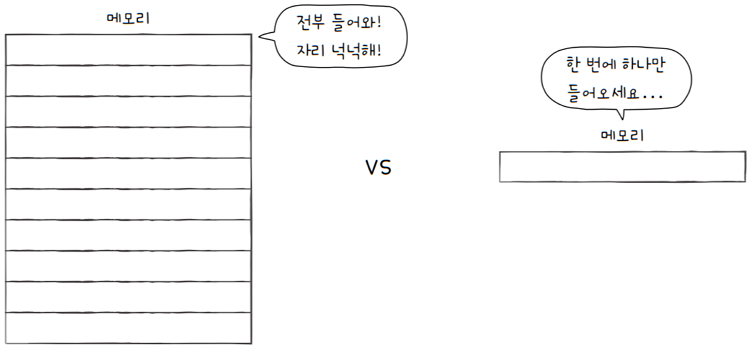
극단적 예시로 프레임이 무한히 많은 컴퓨터와 프레임이 1개 있는 컴퓨터를 비교해보면,
- 전자는 페이지를 수용할 공간이 넉넉하여,
- 모든 프로세스의 페이지가 메모리에 적재될 수 있기 때문에 페이지 폴트 발생 빈도가 적지만,
- 후자는 새로운 페이지를 참조할 때마다 페이지 폴트가 발생합니다.
이처럼 프레임이 부족하면, CPU는 페이지 폴트가 자주 발생할 수밖에 없습니다.
- 실행의 맥이 탁 탁 끊기고, 결과적으로 CPU의 이용률도 떨어집니다.
- CPU가 쉴새 없이 프로세스를 실행해야, 컴퓨터 전체의 생산성도 올라갈 텐데,
- 페이지 교체에 너무 많은 시간을 쏟으면, 당연히 성능에도 큰 악영향이 초래됩니다.
- 이처럼 프로세스가 실제 실행되는 시간보다 페이징에 더 많은 시간을 소요하여 성능이 저해되는 문제를
스래싱이라고 합니다.
3.3.1 스레싱(thrashing)
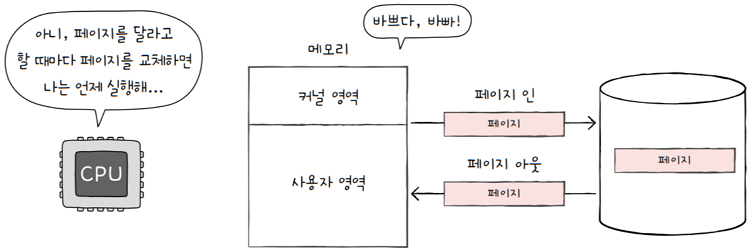
스레싱 : 프로세스가 실제 실행되는 시간보다 페이징에 더 많은 시간을 소요하여 성능(CPU 이용률)이 저해되는 문제
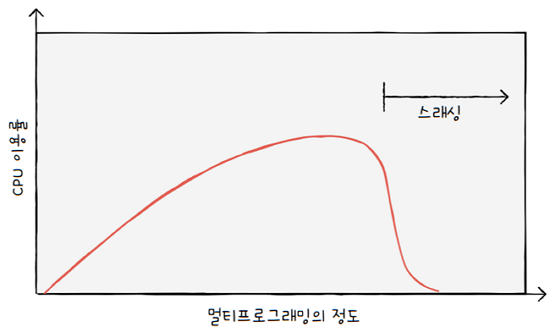
스래싱을 그래프로 표현하면 위와 같습니다.
세로축인 CPU 이용률을 통해, CPU가 얼마나 쉴 새 없이 일을 하고 있는지를 알 수 있습니다.- 이 값이 높으면, CPU는 현재 일을 쉬지 않고 하고 있다는 의미이고,
- 이 값이 낮다면, CPU는 현재 일을 많이 하고 있지 않다는 것을 의미하지요.
가로축인 멀티 프로그래밍의 정도를 통해 메모리에 올라와 있는 프로세스의 수를 알 수 있습니다.- 이 값이 높다면, 현재 메모리에는 많은 프로세스가 동시에 실행 중이고,
- 이 값이 낮다면 ,현재 메모리에는 적은 프로세스가 동시에 실행 중이라고 이해하면 됩니다.
- cf.
멀티프로그래밍의 정도(degree of multiprogramming)=== 메모리에서 동시 실행되는 프로세스의 수
위 그래프는 동시에 실행되는 프로세스의 수(멀티프로그래밍의 정도)를 늘린다고 해서,
- CPU 이용률이 그에 비례해서 증가하는 것이 아님을 나타냅니다.
- 동시에 실행되는 프로세스 수가 어느 정도 증가하면 CPU 이용률이 높아지지만,
- 필요 이상으로 늘리면 각 프로세스들이 사용할 수 있는 프레임 수가 적어지기 때문에
- 페이지 폴트가 지나치게 빈번히 발생하고,
- 이에 따라 CPU 이용률이 떨어져 전체적인 성능이 저해되는 것이지요.
- 아무리 CPU의 성능이 뛰어나도, 동시에 실행되는 프로세스를 수용할 물리 메모리가 너무 작다면,
- 전체 컴퓨터의 성능이 안 좋아지는 이유는 이 때문입니다.
스래싱이 발생하는 근본적인 원인은
- 각 프로세스가 필요로 하는 최소한의 프레임 수가 보장되지 않았기 때문입니다.
- 그래서
운영체제는 각 프로세스들이 무리없이 실행하기 위한 최소한의 프레임 수를 파악하고, - 프로세스들에 적절한 수만큼 프레임을 할당해줄 수 있어야 합니다.
- e.g. 프로세스 A를 무리없이 실행하기 위해서는 최소 10개의 프레임이 필요한데,
- 프로세스 A가 5개의 프레임만 이용할 수 있다면,
- A 프로세스는 페이지 폴트가 자주 발생합니다.
- 즉, 스래싱 발생 위험이 높아짐
3.3.2 정적 할당 방식
(1) 균등 할당
우선 가장 단순한 형태의 프레임 할당 방식부터 생각해 봅시다.
균등 할당(equal allocation): 가장 단순한 할당 방식- 모든 프로세스에 균등하게 프레임을 제공하는 방식
- e.g. 3개의 프로세스에 총 300개의 프레임을 할당할 수 있다면,
- 각 프로세스에 100개의 프로세스를 할당하는 방식
하지만 짐작할 수 있다시피 이는 그리 권장할 만한 방법이 아닙니다.
- 실행되는 프로세스들의 크기는 각기 다른데,
- 천편일률적으로 동일한 프레임 개수를 할당하는 것은 비합리적입니다.
- e.g. 크기가 상대적으로 큰
워드 프로세서와 상대적으로 작은메모장이 동시에 실행된다면,워드 프로세서에 프레임을 더 많이 할당해 주고,메모장에는 상대적으로 적은 프레임을 할당하는 것이 더 합리적입니다.
- 이렇게 프로세스의 크기가 크면, 프레임을 많이 할당하고,
- 프로세스 크기가 작으면, 프레임을 적게 나눠 주는 방식을
비례 할당이라고 합니다.
- 프로세스 크기가 작으면, 프레임을 적게 나눠 주는 방식을
(2) 비례 할당
비례 할당(proportional allocation): 프로세스의 크기를 고려하는 방식- 프로세스 크기에 비례하여 프레임 할당
💡 균등 할당과 비례 할당 방식은 정적 할당 방식이라고도 부름
균등 할당과 비례 할당 방식은 프로세스의 실행 과정을 고려하지 않고, 단순히 프로세스의 크기와 물리 메모리의 크기만을 고려한 방식이라는 점에서 정적 할당 방식이라고도 합니다
💡 균등 할당 vs 비례 할당
균등 할당은 모든 프로세스에 동일한 프레임을 배분하는 방식비례 할당은 프로세스 크기에 따라 프레임을 배분하는 방식
하지만 비례 할당 또한 완벽한 방식은 아닙니다.
- 크기가 큰 프로세스인데, 막상 실행해보니 많은 프레임을 필요로 하지 않으면?
- 크기가 작은 프로세스인데, 막상 실행해보니 많은 프레임을 필요로 하면?
- 결국 프로세스가 필요로 하는 프레임 수는 실행해봐야 안다.
3.3.3 동적 할당 방식
프로세스를 실행하는 과정에서 배분할 프레임을 결정하는 방식에는 크게 2가지가 있습니다.
작업 집합 모델(working set model)페이지 폴트 빈도(PFF; Page-Fault Frequency)
(1) 작업 집합 모델
- 프로세스가 실행하는 과정에서 배분할 프레임 결정
- 스레싱이 발생한 이유는 빈번한 페이지 교체 때문
- 그렇다면 CPU가 특정 시간 동안 주로 참조한 페이지 개수만큼만 프레임을 할당하면 된다.
컴퓨터 구조에서 학습한 참조 지역성의 원리를 기억하나요?
CPU가 메모리를 참조할 때, 참조 지역성의 원리에 의거해 주로 비슷한 구역을 집중적으로 참조합니다.- 한 프로세스가 100개의 페이지로 이루어졌다고 해서 100개를 모두 고르게 참조하는 것이 아니라,
- 특정 시간 동안에는 몇몇 개의 페이지(정확히는 몇 개의 페이지 내 주소들)만을 집중적으로 참조하게 되지요.
그렇다면 CPU가 특정 시간 동안 주로 참조한 페이지 개수만큼만 프레임을 할당하면,
- 페이지 교체는 빈번하게 발생하지 않겠죠?
- 만약 CPU가 어떤 프로세스를 실행하는 동안 3초에 7개의 페이지를 집중적으로 참조했다면,
- 운영체제는 그 프로세스를 위해 그 순간만큼은 최소 7개의 프레임을 할당하면 되겠죠.
- 또 만약 CPU가 어떤 프로세스를 실행하는 동안 3초에 20개의 페이지를 집중적으로 참조했다면,
- 운영체제는 그 프로세스를 위해 그 순간만큼은 최소 20개의 프레임을 할당하면 됩니다.
- 실행 중인 프로세스가 일정 시간 동안 참조한 페이지의 집합을
작업 집합(working set)이라고 합니다.- CPU가 과거에 주로 참조한 페이지를 작업 집합에 포함한다면,
- 운영체제는 작업 집합의 크기만큼만 프레임을 할당해주면 됩니다.
- 즉,
작업 집합 모델 기반 프레임 할당 === 작업 집합의 크기만큼만 프레임을 할당하는 방식
💡 작업 집합 구하기
작업 집합을 직접 구해볼까요? 작업 집합은 실행 중인 프로세스가 일정 시간 동안 참조한 페이지의 집합이라고 했습니다. 그렇기에 작업 집합을 구하려면 다음 2가지가 필요합니다.
- 프로세스가 참조한 페이지
- 일정 시간 간격
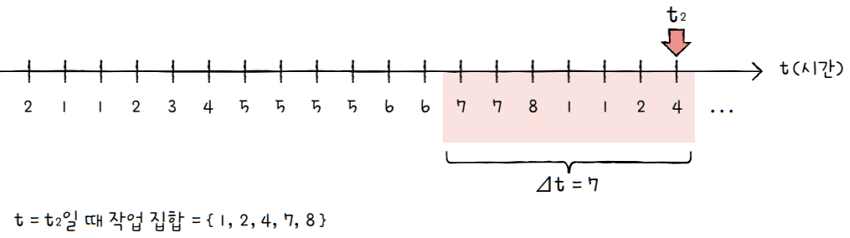
e.g. 프로세스가 참조한 페이지가 위 그림과 같고,
시간 간격(Δt, 델타 t)은 7이었다고 가정
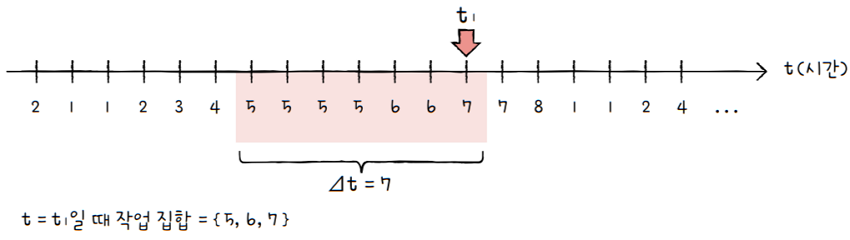
이 경우
시간 t1에서의 작업 집합은 위 그림과 같이{5, 6, 7}이 됩니다. 이는 달리 말해, 이 프로세스는시간 t1에 최소 3개의 프레임이 필요하다고 볼 수 있습니다.
시간 t2에서의 작업 집합은{1, 2, 4, 7, 8}입니다. t1에 비해 작업 집합이 늘었습니다. 이 경우더 많은 프레임(최소 5개의 프레임)이 필요하다고 볼 수 있습니다.
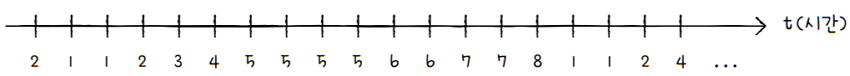
(2) 페이지 폴트 빈도
- 프로세스가 실행하는 과정에서 배분할 프레임 결정
- 다음 2개의 가정에서 생겨난 아이디어
- 페이지 폴트율이 너무 높으면, 그 프로세스는 너무 적은 프레임을 갖고 있다.
- 페이지 폴트율이 너무 낮으면, 그 프로세스가 너무 많은 프레임을 갖고 있다.
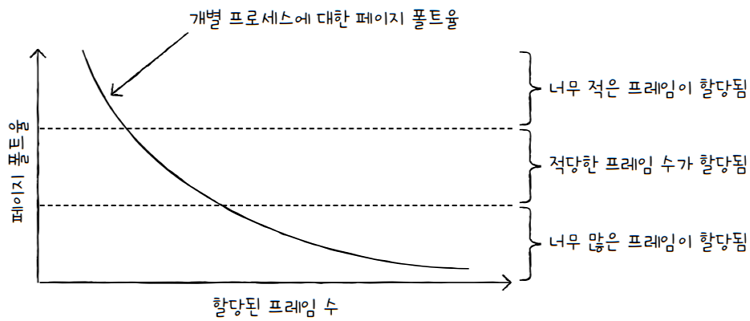
이를 그래프로 표현하면 위 그림과 같습니다.
가로축은 한 프로세스에 할당된 프레임 수,세로축은 페이지 폴트 비율을 나타냅니다.- 이 둘은 반비례 관계를 보이는 것을 알 수 있습니다.
여기서 임의로 페이지 폴트율의 상한선과 하한선을 그어 봅시다.
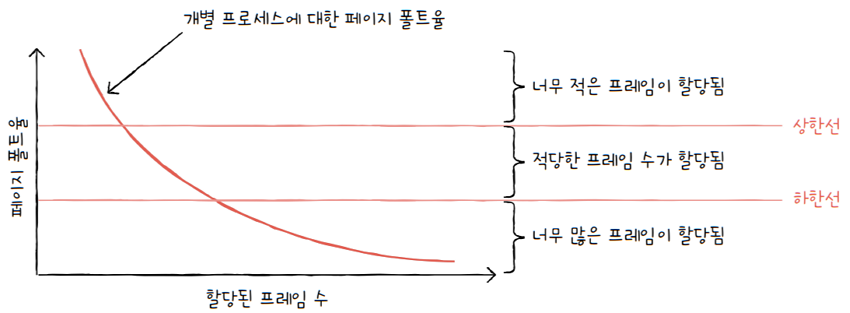
- 만일
페이지 폴트율이 상한선보다 더 높아지면,- **‘그 프로세스는 너무 적은 프레임을 갖고 있다’**고 볼 수 있습니다.
- 이 경우 프레임을 더 할당해주면 됩니다.
- 반대로
페이지 폴트율이 하한선보다 더 낮아지면,- **‘그 프로세스는 너무 많은 프레임을 갖고 있다’**고 볼 수 있습니다.
- 따라서 이 경우 다른 프로세스에 할당하기 위해 프레임을 회수합니다.
- 즉,
페이지 폴트 빈도 기반 프레임 할당 방식은- 페이지 폴트율에 상한선과 하한선을 정하고,
- 이 범위 안에서만 프레임을 할당하는 방식입니다.