1. LAN을 넘어서는 네트워크 계층
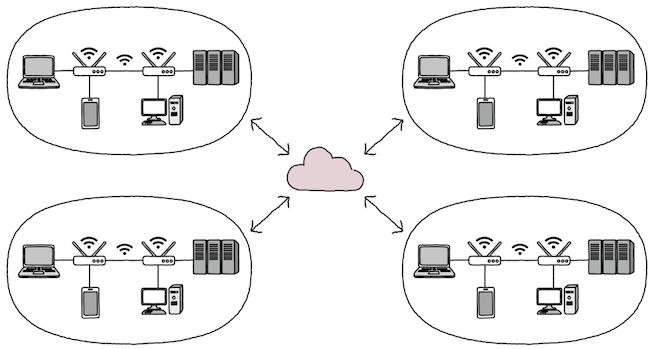
지금까지 학습한 네트워크의 범위는 일반적으로 LAN에 한정된다.
- 하지만, LAN을 넘어서 다른 네트워크와 통신하기 위해서는 네트워크 계층의 역할이 필수적이다.
네트워크 계층에서는 IP 주소를 이용해 송수신지 대상을 지정하고,다른 네트워크에 이르는 경로를 결정하는 라우팅을 통해 다른 네트워크와 통신한다.
1.1 데이터 링크 계층의 한계
물리 계층과 데이터 링크 계층만으로 LAN을 넘어서, 다른 도시나 다른 국가에 있는 친구와 통신할 수 있을까?
- 데이터 링크 계층에는 송수신지를 특정할 수 있는 정보인
MAC 주소개념이 있기에 언뜻 들으면 가능할 것 같다.- 이 정보를 바탕으로 다른 도시, 다른 국가에 있는 수신지로 전송하면 될 것 같다.
- 그러나 결론부터 말하면
물리 계층과데이터 링크 계층만으로는 LAN을 넘어서 통신하기 어렵다.- 대표적으로 2가지 이유가 있다.
- 이 이유들은 네트워크 계층의 핵심 기능과도 직결된다.
(1) 물리 계층과 데이터 링크 계층만으로는 다른 네트워크까지의 도달 경로를 파악하기 어렵다.
물리 계층과 데이터 링크 계층은 기본적으로 LAN을 다루는 계층이다.
- 하지만, LAN에 속한 호스트끼리만 통신하지는 않는다.
- 지구 반대편의 컴퓨터와 통신하려면,
- 해당 패킷과 서로에게 도달하기까지 수많은 네트워크 장비를 거치며 다양한 경로를 통해 이동한다.
- e.g.
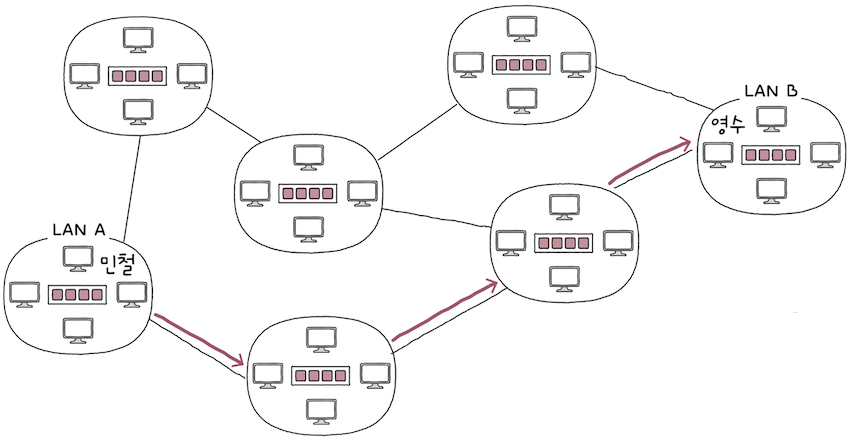
LAN A에 속한 호스트‘민철’이LAN B에 속한 호스트 ‘영수’에게 전송하는 패킷은 다양한 경로를 통해 이동할 수있다.- 통신을 빠르게 주고받으려면, 이 중에 최적의 경로로 패킷이 이동해야 한다.
- 이렇게 패킷이 이동할 최적의 경로를 결정하는 것을
라우팅(routing)이라고 한다.
- 물리 계층과 데이터 링크 계층의 장비로는 라우팅을 수행할 수 없지만, 네트워크 계층의 장비로는 가능하다.
- 라우팅을 수행하는 대표적인 장비로는
라우터(router)가 있다.
- 라우팅을 수행하는 대표적인 장비로는
- cf. 라우터의 개념과 라우터가 수행하는 다양한 방법은 뒤에서 학습한다.
(2) MAC 주소만으로는 모든 네트워크에 속한 호스트의 위치를 특정하기 어렵다.
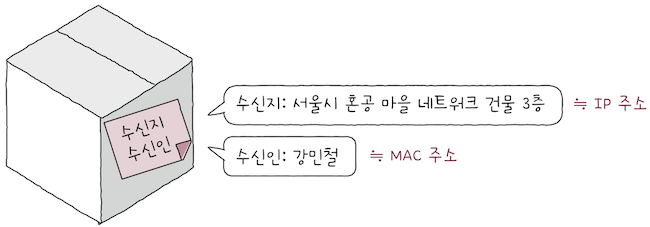
현실적으로 모든 호스트가 모든 네트워크에 속한 모든 호스트이 MAC 주소를 서로 알기는 어렵다.
- 그래서
MAC 주소만으로는 이 세상 모든 호스트를 특정하기 어렵다. - 네트워크를 통해 정보를 주고받는 과정은 택배를 송수신하는 과정과 같고,
MAC 주소는네트워크 인터페이스(NIC)마다 할당된 일종의 개인정보와도 같다.
- 택배를 보낼 떄 받는 사람의 개인정보만 택배에서 적어서 보내지는 않죠?
- 인물을 특정하는 정보 외에도 당연히 수신지도 써야 한다.
- 수신지를 쓰지 않는다면, 택배기사 입장에서는 받는 사람이 현재 어디 사는지 알 수 없다.
- 네트워크 역시 마찬가지다.
- 택배의 수신인 역할을 하는 정보가
MAC 주소면, 수신지 역할을 하는 정보는네트워크 계층의 IP주소다.- 택배 배송 과정에서 ‘수신인’과 ‘수신지’를 모두 활용하고, ‘수신인’보다 ‘수신지’를 우선으로 고려하는 것처럼,
네트워크에서도 MAC 주소와 IP주소를 함께 사용하고, 기본적으로 IP주소를 우선 활용한다.
MAC 주소를물리 주소라고 부르고,IP주소는논리 주소라고도 부른다.MAC 주소는 일반적으로 NIC마다 할당되는 고정된 주소이지만,IP주소는 호스트에 직접 할당이 가능하다.
DHCP(Dynamic Host Configuration Protocol)라는 특정 프로토콜을 통해 자동으로 할당받거나,- 사용자가 직접 할당할 수 있고, 한 호스트가 복수의 IP주소를 가질 수도 있다.
💡 정리하면,
물리 계층과데이터 링크 계층만으로는 네트워크 간의 통신이 어렵고,
네트워크 계층이 다른 네트워크와의 통신을 가능하게 한다.- 이는
IP주소를 이용해 수신지 주소를 설정하거나,
- 해당 수신지까지의 최적의 경로를 결정하는
라우팅이 네트워크 계층에서 이루어지기 떄문이란 사실을 기억하자.
1.2 인터넷 프로토콜
네트워크 계층의 가장 핵심적인 프로토콜 하나를 뽑으면, 인터넷 프로토콜(IP; Internet Protocol)이다.
- IP에는 2가지 버전이 있는데, IP버전 4(이하
IPv4)와 IP버전 6(이하IPv6)이다. - 일반적으로 IP 혹은 IP 주소를 이야기할 떄는 주로 IPv4를 의미하는 경우가 많다.
- 여기서도 IPv4를 중심으로 살펴본다.
1.2.1 IP 주소 형태
IP주소는 4바이트(32비트)로 주소를 표현할 수 있고,
- 숫자당 8비트로 표현되기에, 0~255 범위 안에 있는 4개의 10진수로 표기된다.
- 각 10진수는
점(.)으로 구분되며, 점으로 구분된 8비트(0~255범위의 10진수)를옥텟(octet)이라고 한다. 192.168.1.1은 각각은 8비트로 표현된 옥텟인 셈이다.
1.2.2 IP의 기능
IP 기능은 다양하지만 대표적인 기능에는 크게 2가지가 있는데, IP 주소 지정과 IP 단편화이다.
- IP(IPv4)를 정의한 인터넷 표준 문서(RFC 791)에서도 이를 명확히 명시하고 있다.
- 이 두 역할을 중심으로 IPv4와 IPv6를 알아보자
1# RFC 7912The internet protocol implements two basic functions: addressing and fragmentation.3# ^ addressing : IP 주소 지정4# ^ fragmentation : IP 단편화
💡RFC(Request for Comments) 문서
RFC 문서는 네트워크/인터넷 관련 신기술 제안, 의견 등을 남긴 문서이다.
- 언뜻 들으면 가볍게 느껴질 수 있는 이름과는 다르게, 일부 RFC는 오늘까지 사용되는 인터넷 표준이 되기도 한다.
- 인터넷 표준이 된 RFC를 비롯한 영향력있는 RFC 문서에는 번호가 부여되어 있다.
- IP(IPv4)를 정의한 인터넷 표준 문서를
RFC 791라고 했었다.- 여기서
791이RFC 번호이다.- 번호를 부여받은 RFC 문서는 새로운 RFC 문서로 개정 출판이 되지, 폐지되거나 수정되지 않아서,
- 웹 브라우저에
RFC + RFC번호(e.g. RFC 791)를 검색하면, 어렵지 않게 원문을 찾아볼 수 있다.- cf. 엄밀하고 정확한 내용을 설명하고, 알고 싶을 떄, RFC 문서를 자주 참조하자.
IP 주소 지정(IP addressing)은 IP 주소를 바탕으로 송수신 대상을 지정하는 것을 의미한다.
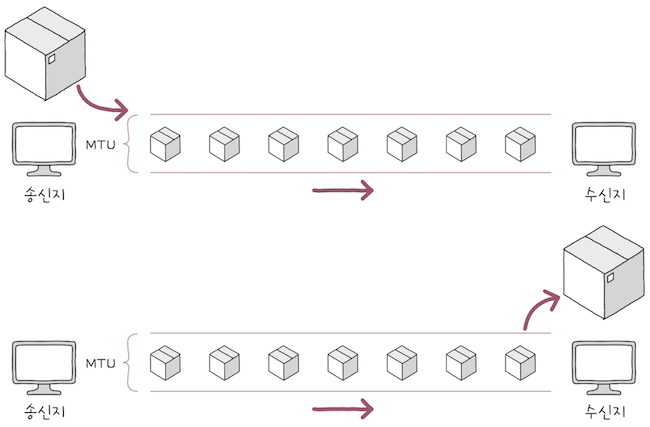
IP 단편화(IP fragmentation)는 전송하고자 하는패킷의 크기가 MTU라는 최대 전송 단위보다 클 경우,- 이를 MTU 크기 이하의 복수의 패킷으로 나누는 것을 의미한다.
MTU(Maximum Transmission Unit)란 한 번에 전송 가능한 IP 패킷의 최대 크기를 의미한다.- IP 패킷의 헤더도 MTU 크기에 포함된다는 점을 주의하자.
- 일반적인 MTU 크기는 1500바이트이며, MTU 크기 이하로 나누어진 패킷은 수신지에 도착하면 다시 재조합된다.
그렇다면, IP로 주소받는 패킷에는 어떤 정보가 포함되어 있어서, IP 주소 지정과 IP 단편화가 가능할까?
1.2.3 IPv4
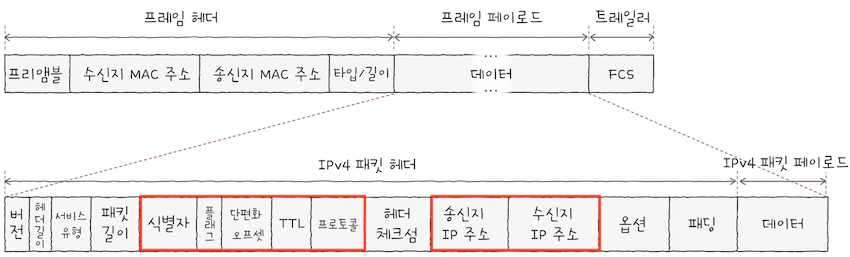
프레임의 데이터 필드에는상위 계층에서 전달받거나,상위 계층으로 전달해야 할 내용이 명시된다.- IPv4 패킷은 위 그림과 같은 형식을 띤다.
- 모든 필드 중에서도 가장 핵심이 되는 부분인 필드는 붉은 테두리로 표기한
- (1) 식별자, (2) 플래그, (3) 단편화 오프셋, (4) TTL, (5) 프로토콜, (6) 송신지 IP주소, (7) 수신지 IP 주소이다.
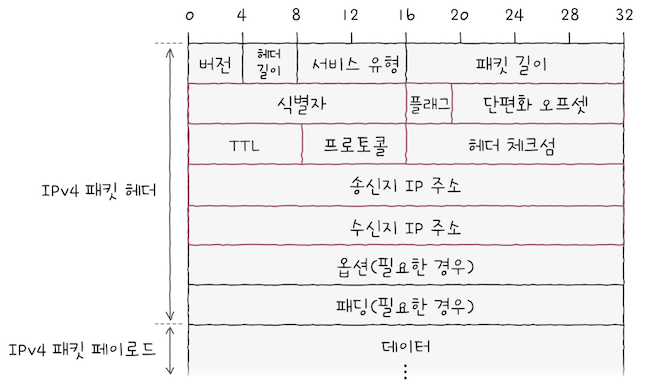
이 중에서 식별자, 플래그, 단편화 오프셋 필드는 IP 단편화 기능에 관여하고,
송신지 IP 주소, 수신지 IP 주소는 IP 주소 지정에 관여한다.
(1) 식별자(identifier)
식별자는 패킷에 할당된 번호다.- 만일 메시지 전송 과정에서 IPv4 패킷이 여러 조각으로 쪼개져서 전송되었다면,
- 수신지에서는 이들을 재조립해야 한다.
- 이떄 잘게 쪼개져서 수신지에 도착한 IPv4 패킷들이
- 어떤 메시지에서부터 쪼개졌는지를 인식하기 위해서 식별자를 사용한다.
(2) 플래그(flag)

플래그는 총 3개의 비트로 구성된 필드이다.- 이 중에서
첫 번째 비트는 항상 0으로 예약된 비트로 현재 사용되지 않는다. - 사용되는
나머지 2개의 비트중에서 하나는DF라는 이름이 붙은 비트이다.- DF는 Don’t Fragment의 약어로, IP 단편화를 수행하지 말라는 표시다.
- DF 비트가 1로 설정되면, IP 단편화를 수행하고,
- 0으로 설정되면, IP 단편화가 가능하다.
- 또 하나의 비트는
MF라는 비트다.- MF는 More Fragment의 약어로, 단편화된 패킷이 더 있는지를 나타낸다.
- MF 비트가 0이면, 이 패킷이 마지막 패킷임을 의미하고,
- MF 비트가 1이면, 쪼개진 패킷이 아직 더 있다는 것을 의미한다.
(3) 단편화 오프셋(fragment offset)
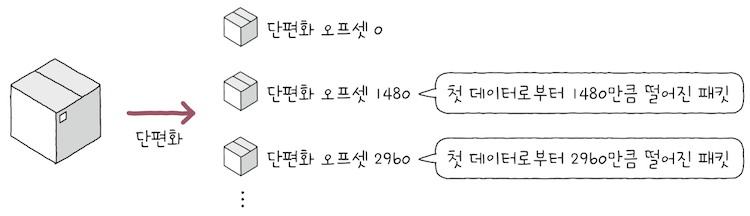
단편화 오프셋은 패킷이 단편화되기 전에, 패킷의 초기 데이터에서 몇 번쨰로 떨어진 패킷인지를 나타낸다.- 단편화되어 전송되는 패킷들은 수신지에 순서대로 도착하지 않을 수 있다.
- 따라서 수신지가 패킷들을 순서대로 재조합하려면,
- 단편화된 패킷이 초기 데이터에서 몇 번쨰 데이터에 해당하는 패킷인지 알아야 한다.
- 이를 활용하기 위해
단편화 오프셋이 활용된다.
(4) TTL(Time To Live)
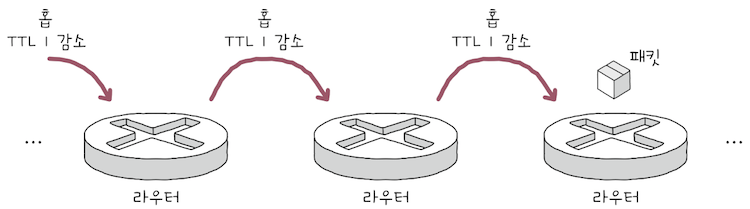
TTL은 패킷의 수명을 의미한다.- 멀리 떨어진 호스트끼리 통신할 떄,
패킷은 여러 라우터를 거쳐 이동할 수 있다. 패킷이 하나의 라우터를 거칠 때마다 TTL이 1씩 감소하며, TTL값이 0으로 떨어진 패킷은 폐기된다.패킷이 호스트 또는 라우터에 한 번 전달되는 것을홉(hop)이라고 한다.- 즉,
TTL 필드의 값은 홉마다 1씩 감소한다. - TTL 필드의 존재 이유는 무의미한 패킷이 네트워크 상에 지속적으로 남아있는 것을 방지하기 위함이다.
- 즉,
- cf. TTL 필드가 0이 되면, 해당 패킷은 폐기되고,
- 패킷을 송신한 호스트에게
시간 초과(Time Exceeded)메시지가 전송된다. - 이를 알려주는 프로토콜이
ICMP이다. 뒤에서 배운다.
- 패킷을 송신한 호스트에게
(5) 프로토콜
IP 패킷의 프로토콜은 상위 계층의 프로토콜이 무엇인지를 나타내는 필드다.- e.g. 전송 계층의 대표적인 프로토콜인
TCP는 6번,UDP는 17번이다.
(6) 송신지 IP 주소(Source IP Address), (7) 수신지 IP 주소(Destination IP Address)
- 이름 그대로 송수신지의 IPv4 주소를 알 수 있다.
💡 요약하면,
- IPv4는
식별자, 플래그, 단편화 오프셋으로 단편화와 재조합을 할 수 있고,프로토콜 필드로 상위 계층 프로토콜을 알 수 있으며,TTL로 패킷의 남은 수명을 파악할 수 있다.- 또한
송신지 IP 주소, 수신지 IP 주소를 통해 IP 주소를 지정할 수 있다.
1.2.4 IPv6
IPv4 주소는 4바이트(32비트)로 표현되고, 0~255 범위의 4개의 10진수로 표기되는 주소다.
- 그리고 이 주소를 이용해 네트워크 상의 호스트를 식별할 수 있지만, 여기에 문제가 있다.
- 이론적으로 할당 가능한 IPv4 주소는 총 개로 약 43억개다.
- 전 세계 인구가 하나씩 IP 주소를 가지고 있어도, 부족한 숫자다.
- IP 주소를 할당할 수 있는 장치가 스마트폰, 데스크톱, 노트북, 냉장고, TV 등 여러 개이다.
- 43억개라는 IPv4의 주소 총량은 쉽게 고갈되므로, 이러한 이유로 등장한 것이
IPv6다.
- IPv4 주소 :
192.168.1.1- IPv6 주소 :
2001:0230:abcd:ffff:0000:0000:ffff:1111
IPv6는 16바이트(128비트)로 주소를 표현할 수 있고, 콜론(:)으로 구분된 8개의 그룹의 16지수로 표기된다.
- 다시 말해, 할당 가능한 IPv6 주소는 이론적으로 개로 사실상 무한에 가까운 개수를 할당할 수 있다.

IPv6 패킷은 위 그림과 같다. IPv6 패킷의 기본 헤더는 IPv4에 비해 간소화되어 있다.
- (1) 다음 헤더, (2) 홉 제한, (3) 송신지 IP 주소, (4) 수신지 IP 주소, 4개의 주요 필드를 알아보자
(1) 다음 헤더(next header)
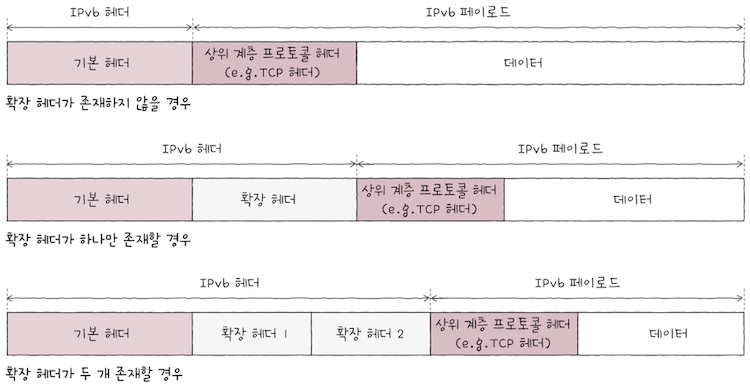
다음 헤더는 상위 계층의 프로토콜을 가리키거나, 확장 헤더를 가리킨다.- 여기서 확장 헤더란 무엇일까? IPv6의 기본 헤더는 IPv4에 비해 간소화되어 있다.
- 위 그림에 표현된 IPv6의 헤더는
기본 헤더이다. - IPv6는 추가적인 헤더 정보가 필요한 경우에 기본 헤더와 더불어
확장 헤더(extention header)라는 추가 헤더를 가질 수 있다. - 확장 헤더는 위 그림처럼 기본 헤더와 페이로드 데이터 사이에 위치한다.
- 또한 마치 꼬리에 꼬리를 물듯 또 다른 확장 헤더를 가질 수 있다.
- 확장 헤더의 종류는 다양하기 떄문에, 상황에 맞는 다양한 정보를 운반할 수 있다.
- 암기할 필요는 없지만, 대표적인 확장 헤더 종류는 다음과 같이 있다.
- 송신지에서 수신지에 이르듯 모든 경로의 네트워크 장비가 패킷을 검사하도록
홉 간 옵션(Hop-by-Hop Option) - 수신지에서만 패킷을 검사하도록 하는
수신지 옵션(Destination Options) - 라우팅 관련 정보를 운반하는
라우팅(Routing) - 단편화를 위한
단편(Fragment) - 암호화와 인증을 위한
ESP(Encapsulating Security Payload),AH(Authentication Header)
- 송신지에서 수신지에 이르듯 모든 경로의 네트워크 장비가 패킷을 검사하도록
💡 IPv6의 단편화
- IPv6는 IPv4와 달리 기본 헤더에 단편화 관련 필드가 없고, 단편화 확장 헤더를 통해 단편화가 이루어진다.
- 단편화 확장은 위와 같은 구조로 이루어진다.
- 단편화 호가장 헤더에도
다음 헤더필드가 있다.
기본 헤더처럼확장 헤더에도 다음 헤더 필드가 있는 것은 또 다른 확장 헤더 혹은 상위 프로토콜을 가리키기 위함이다.
예약됨(reserved)과예약(res)필드는 0으로 설정되어 사용되지 않는다.
단편화 오프셋(fragment offset)과M 플래그(M flag),식별자(identification)필드는 각각 IPv4의 단편화 오프셋, MF 플래그, 식별자 필드와 같은 역할을 수행한다.단편화 오프셋은 전체 메시지에서 현재 단편화된 패킷의 위치를 나타낸다.M 플래그는 1일 경우 더 많은 단편화된 패킷이 있음을, 0일 경우 마지막 패킷임을 나타낸다.식별자는 동일한 메시지에서부터 단편화된 패킷임을 식별하기 위해 사용된다.

(2) 홉 제한(hop limit)
- 홉 제한 필드는 IPv4 패킷의 TTL 필드와 비슷하게 패킷의 수명을 나타내는 필드다.
(3) 송신지 IP 주소(source address), (4) 수신지 IP 주소(destination address)
송신지 주소와수신지 주소를 통해 IPv6 주소 지정이 가능하다.- 위 그림의 IPv4의 패킷 그림을 보면,
옵션이나 패딩필드는 헤더에 포함되어 있는 정보이지만, 선택적으로 존재한다. - 즉,
IPv4헤더 길이는 가변적이다. 반면,IPv6기본 헤더는 40바이트로 고정적이다. - IPv6 또한 현재 윰아한 프로토콜로 떠오르고 있는 만큼 다수의 장비에서 지원한다.
- 그래도 아직까지는 IPv4가 많이 사용된다.
- 여기서도 특별한 언급이 없는 한
IP 혹은 IP 주소는IPv4를 지칭한다.
1.3 ARP
택배를 전송할 떄 송신지 주소와 송신자, 수신지 주소와 수신자를 함께 명시하되,
- 수신자보다는 수신지를 우선 고려하는 것처럼,
MAC 주소와IP 주소는 함께 사용하지만, 기본적으로IP주소를 사용한다.
- 이 과정에서 ‘상대 호스트의 IP주소는 알지만, MAC 주소는 알지 못하는 상황’이 있을 수 있다.
- 이럴 떄
ARP 프로토콜을 사용한다.
- 이럴 떄
ARP(Address Resolution Protocol)는 IP 주소를 통해 MAC 주소를 알아내는 프로토콜이다.- 동일 네트워크 내에 있는
송수신 대상의 IP 주소를 통해 MAC 주소를 알아낼 수 있다.
- 동일 네트워크 내에 있는
위 그림처럼 호스트 A와 B가 모두 동일한 네트워크에 속한 상태에서 A가 B에게 패킷을 보내고 싶다고 가정하면,
A는B의 IP 주소(10.0.0.2)를 알고 있지만,MAC 주소는 모르는 상황이다.- 네트워크에서 기본적으로 사용되는 주소는
IP주소이지만,- 패킷을 올바르게 송신하려면, 상대 호스트의 MAC 주소까지 알아야 한다.
- 하지만 현재
A는B의 MAC 주소를 알지 못한다. - 여기서
ARP가 사용된다.
ARP의 동작 과정은 다음과 같다.- ARP 요청
- ARP 응답
- ARP 테이블 갱신
- cf. MAC 주소 학습의 주체는
스위치이다.스위치가 MAC 주소를 학습했다 해서 호스트들끼리 서로 MAC 주소를 학습한 것은 아니다.
1.3.1 ARP 요청
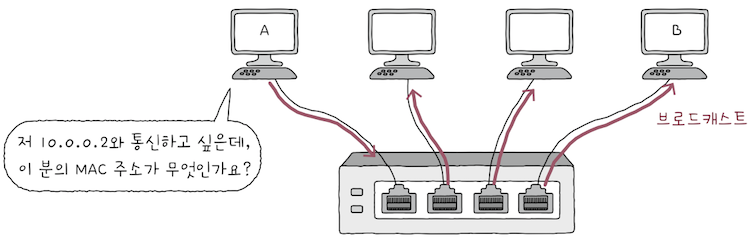
A는 네트워크 내 모든 호스트에게브로드캐스트 메시지를 보낸다.- cf.
브로드캐스트는 자신을 제외한 네트워크 상의 모든 호스트에게 전송하는 방식이다.
- cf.
- 이 메시지는
ARP 요청(ARP Request)라는 ARP 패킷이다. ARP 요청은 ‘10.0.0.2와 통신하고 싶은데, 이 분의 MAC 주소는 무엇인가요?’라고 묻는 것과 같다.
1.3.2 ARP 응답
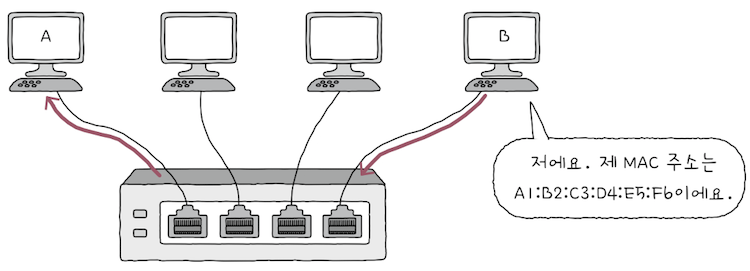
네트워크 내 모든 호스트가ARP 요청 메시지를 수신하지만,B를 제외한 나머지 호스트는 자신의 IP 주소가 아니므로, 이를 무시한다.
B는 자신의 MAC 주소를 담은 메시지를A에게 전송한다.- 이때 B가 보내는 메시지는
유니캐스트메시지는ARP 응답(ARP Reploy)이라는ARP 패킷이다.- cf.
유니캐스트는 하나의 수신지에 메시지를 전송하는 방식이다.
- cf.
B의 MAC 주소가 포함된 메시지를 수신한A는B의 MAC 주소를 알게 된다.
💡ARP 패킷
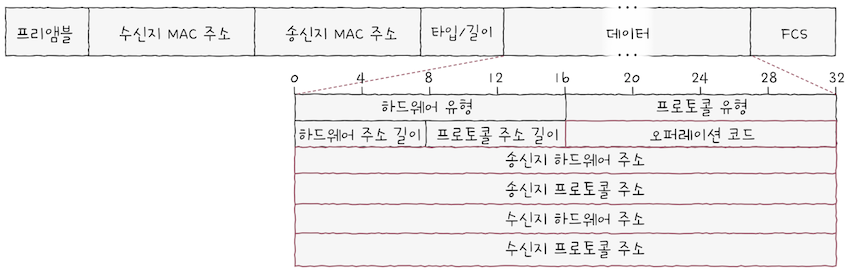
ARP 요청, ARP 응답 과정에서는 ARP 패킷이 전송된다. ARP 패킷은 위 그림과 같은 형식으로, 프레임의 페이로드에 포함되어 전송된다. ARP 패킷에서 핵심 필드를 하나씩 살펴보면,
오퍼레이션 코드(Opcode; Operation Code): ARP 패킷의 유형을 나타낸다.
- ARP 요청의 경우 1, ARP 응답의 경우 2로 설정된다.
송신지 하드웨어 주소(Sender Hardware Address)와수신지 하드웨어 주소(Target Hardware Address)
- 각각 송신지와 수신지의 MAC 주소가 명시된다.
- cf. ARP 요청 시 이더넷 프레임의 ‘수신지 MAC 주소’에는
- 브로드 캐스트 메시지임을 나타내는
ff:ff:ff:ff:ff:ff가 명시되고,- ARP 패킷의 ‘수신지 하드웨어 주소’에는
00:00:00:00:00:00이 명시된다.송신지 프로토콜 주소(Sender Protocol Address)와수신지 프로토콜 주소(Target Protocol Address):
- 각각 송신지와 수신지의 IP 주소가 명시된다.
1.3.3 ARP 테이블 갱신
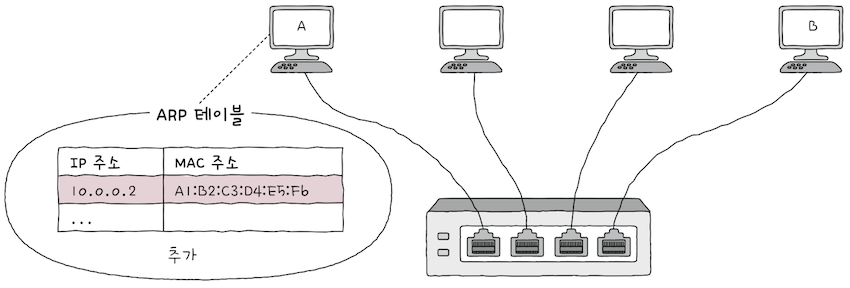
ARP를 활용할 수 있는 모든 호스트는 ARP 테이블(ARP Table)이라는 정보를 유지한다.
ARP 테이블은IP 주소와 그에 맞게MAC 주소 테이블을 대응하는 표다.- A는 (1)과 (2) 단계를 통해 B의 MAC 주소를 알게되면,
- 위 그림처럼
호스트 B의IP 주소와MAC 주소의 연관 관계를ARP 테이블에 추가한다. - 이
ARP 테이블은 일정 시간이 지나면 삭제되고, 임의로 삭제할 수도 있다. - 여기까지 이루어지면, 앞으로
A는B와 통신할 떄, 굳이 브로드캐스트로 ARP 요청을 보낼 필요가 없다.
- 위 그림처럼
- cf.
ARP 테이블은ARP 캐시(ARP cache),ARP 캐시 테이블(ARP cache table)이라고도 부른다.
ARP 테이블은 직접 확인해보면, 윈도우 명령 프롬프트(CMD)나 맥OS 터미널에서 arp -a라고 입력해보세요.
- IP 주소와 그에 대응된 MAC 주소를 볼 수 있다.
1$ arp -a2? (192.168.0.2) at 1a:2b:3c:4d:5e:6e on en6 [ethernet]3? (192.168.0.1) at 1b:2c:3d:4d:5e:6e on en0 [ethernet]4? (192.168.0.1) at 1c:2d:3e:4d:5e:6e on en6 [ethernet]5? (192.168.0.7) at 1d:2e:3f:4d:5e:6e on en6 [ethernet]6...
ARP는 ‘동일 네트워크’ 내에 있는 호스트의 IP 주소를 통해 MAC 주소를 알아내는 프로토콜이라고 했다.
- 그렇다면 통신하고자 하는 호스트 A와 B가 서로 다른 네트워크에 속해있으면 어떻게 될까?
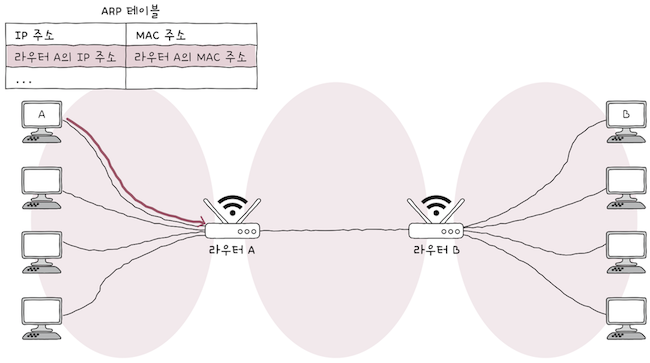
앞선 예시와 달리, 호스트 A가 호스트 B가 동일한 네트워크에 있지 않다.
- 만일
호스트 A가라우터 A의 MAC 주소를 모른다면,ARP 요청 - ARP 응답과정을 통해라우터 A의 MAC 주소를 얻어와서 이를 향해 패킷을 전송한다.
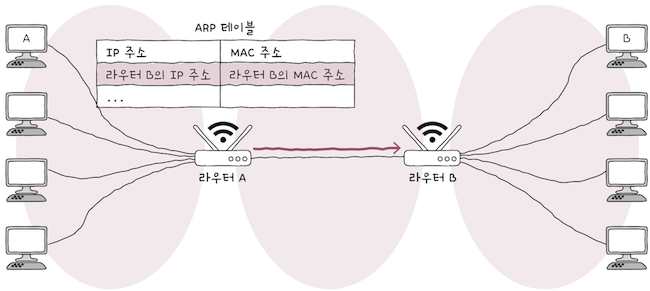
호스트 A에서 패킷을 전달받은 라우터 A는 패킷을 라우터 B로 전달해야 한다.
- 만일
라우터 A가라우터 B의 MAC 주소를 모른다면,- 한 번 더
ARP 요청 - ARP 응답과정을 거쳐,라우터 B의 MAC주소를 얻어오게 된다.
- 한 번 더
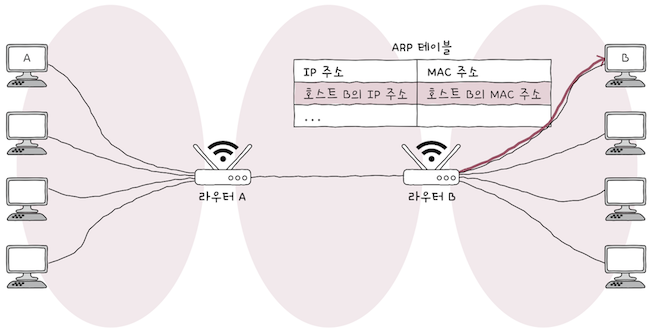
이제 라우터 B는 호스트 B에게 패킷을 전달해야 한다.
- 만일
라우터 B가호스트 B의 MAC 주소를 모른다면, - 똑같이
ARP 요청 - ARP 응답과정을 통해B의 MAC 주소를 얻어야만, 비로소호스트 B에게 패킷을 전달할 수 있다.
다만 이 상황은 매우 간략화된 예시로, 실제로는 라우터 간 통신을 주고받을 떄, ARP만 사용하지는 않는다. 라우팅 프로토콜을 비롯한 다양한 고려사항이 있는데, 이는 뒤에서 계속 학습한다. 여기서는 다음 2가지를 기억해야 한다.
ARP는 동일 네트워크에 속한 호스트의 MAC 주소를 알아내기 위해 사용하는 프로토콜이다.다른 네트워크에 속한 호스트에게 패킷을 보내야 할 경우,- 네트워크 외부로 나가기 위한
장비(라우터)의 MAC 주소를 알아내어 패킷을 전송한다.
- 네트워크 외부로 나가기 위한
1.3.4 IP 단편화를 피하는 방법
IP의 대표적인 기능으로 IP 주소 지정으로 IP 단편화가 있다. IP 단편화는 되도록 하지 않는 것이 좋다.
- 데이터를 여러 패킷으로 쪼개지면, 자연스레 전송해야 할 패킷의 헤더들도 많아지고,
- 이는 불필요한 트래픽 증가와 대역폭 낭비로 이어진다.
- 쪼개진 IP 패킷들을 하나로 합치는 과정에서 발생하는 부하도 성능 저하를 야기할 수 있다.
- 따라서
IP 단편화는 가급적 피하는 것이 좋다.
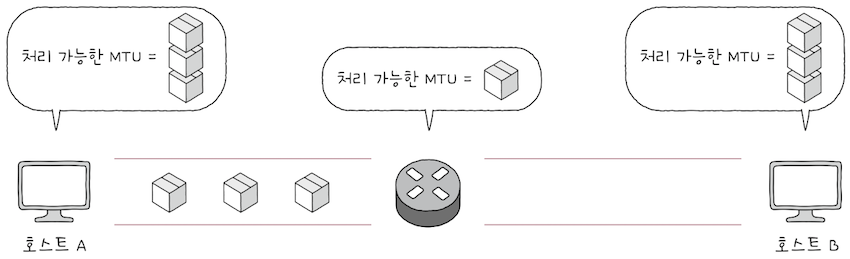
그렇다면 IP 단편화는 어떻게 피할 수 있을까?
- IP 패킷을 주고받는 모든 호스트의 ‘처리 가능한 MTU 크기’를 고려해야 한다.
- 가령 호스트 A, B가 여러 라우터를 거쳐 서로 IP 패킷을 주고받는다고 가정해보면,
- 호스트 A, B가 처리할 수 있는 MTU 크기가 아무리 커도,
- 라우터가 해당 MTU 크기를 지원하지 않으면 IP 단편화를 해야 한다.
- 따라서 IP 단편화를 피하려면, ‘IP 단편화없이 주고받을 수 있는 최대 크기’만큼만 전송해야 한다.
- 이 크기를
경로 MTU(Path MTU)라고 한다. - 다시 말해,
IP 단편화를 피하는 방법은 경로 MTU만큼의 데이터를 전송하는 것이다.
- 이 크기를
경로 MTU를 구하고, 해당 크기만큼만 송수신하여,
- IP 단편화를 회피하는 기술을
경로 MTU 발견(Path MTU discovery)라고 한다. - 오늘날 네트워크에서는 대부분 이를 지원하고,
- 처리 가능한 최대 MTU 크기도 대부분 균일하기 떄문에, IP 단편화는 자주 수행되지 않는다.
뒤에 6장에서 `와이어샤크₩라는 프로그램을 통해 실제 네트워크 속 패킷을 조회하고 분석하는 방법을 배운다.
-
이 프로그램을 통해 실제 IP 패킷을 관찰해보면, 대부분의
IP 패킷에DF 플래그가 설정되어 있는 것을 볼 수 있다. -
이는 오늘날 네트워크에서는 대부분
경로 MTU 발견을 지원하는 것을 보여준다. -
경로 MTU 발견은 기본적으로DF 플래그를 설정한 채 동작하기 떄문이다.1.2.3의 (2) 플래그에서
DF 플래그는 ‘IP 단편화를 수행하지 말라’라는 플래그라고 했다. -
가령 어떤 호스트로부터
처리 불가능한 크기의(처리 가능한 MTU 크기를 넘어선) IP 패킷을 전달받았는데, -
해당
IP 패킷에DF 플래그가 설정되어 있다면,IP 패킷을 전달한 호스트에게 ‘DF 플래그가 설정되어 있는데, 이걸 단편화없이 처리할 수 없다’라는 특징 오류 메시지를 전달하게 된다.
-
그럼
IP 패킷을 전달한 호스트는 이 오류 메시지를 받지 않을 떄까지, 전달하는 데이터 크기를 점차 줄이게 된다. -
이렇게 서로의 경로 MTU를 알아가게 된다.
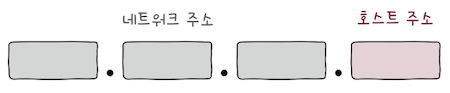
2. IP 주소
택배 배송 과정에서 ‘수신인’보다는 ‘수신지’를 우선으로 고려하듯, 네트워크 통신에서도 IP 주소가 기본으로 사용된다.
- 그만큼 네트워크 계층의
IP 주소는 네트워크에서 핵심적인 역할을 한다. - 하나의 IP 주소는 크게
네트워크 주소와호스트 주소로 이루어진다.- 다시 말해,
네트워크를 표현하는 부분과호스트를 표현하는 부분으로 이루어져 있다. - 전자는 호스트가 속한 특정 네트워크를 식별하는 역할을 하며,
- 후자는 네트워크 내에서 특정 호스트를 식별하는 역할을 한다.
- 다시 말해,
이런 구조로 이루어진 IP 주소를 어떻게 관리하고, 호스트에 할당할 수 있는지 알아보자.
2.1 네트워크 주소와 호스트 주소
네트워크 주소는네트워크 ID,네트워크 식별자(network identifer)등으로 부르기도 하며,호스트 주소는호스트 ID,호스트 식별자(host identifier)등으로도 부른다.

위 그림은 네트워크 주소가 16비트, 호스트 주소가 16비트인 IP 주소의 예시이다.
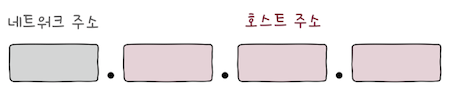
만약 네트워크 주소가 위 그리과 같이 하나의 옥텟으로 이루어져 있다면,
한 네트워크당 호스트 주소 할당에 24비트를 사용할 수 있어서, 상대적으로 많은 호스트에 IP 주소를 할당할 수 있다.- cf. 하나의 옥텟은 8비트다.
또 만약 네트워크 주소가 위와 같이 3개의 옥텟으로 이루어져 있다면,
한 네트워크당 호스트 주소 할당에 8비트를 사용할 수 있어서, 상대적으로 적은 호스트에 IP 주소를 할당할 수 있다.
이처럼 IP 주소에서 네트워크 주소와 호스트 주소를 구분하는 범위는 유동적일 수 있다.
- 그렇다면,
네트워크 주소와호스트 주소의 크기는 각각 어느정도가 적당할까? - 하나의 IP 주소에 호스트 주소의 공간을 얼마나 할당하는 것이 좋을까?
- 호스트의 주소 공간을 무조건 크게 할당하는 것이 좋을까? 아니면 공간을 무조건 작게 할당하는 것이 좋을까?
호스트의 주소 공간을 크게 할당하면, 호스트가 할당되지 않은 다수의 IP 주소가 낭비된다.- 반대로,
호스트의 주소 공간을 작게 할당하면, 호스트가 사용할 IP 주소가 부족해질 수 있다.
- 이런 고민을 해결하기 위해서 생겨난 개념이
IP 주소의 클래스(class)다.
2.2 클래스풀 주소 체계
클래스는 네트워크 크기에 따라 IP 주소를 분류하는 기준이다.
- 클래스를 이용하면, 필요한 호스트 IP 개수에 따라,
- 네트워크 크기를 가변적으로 조정해
네트워크 주소와호스트 주소를 구획할 수 있다. - 클래스를 기반으로 IP 주소를 관리하는 주소 체계를
클래스풀 주소 체계(classful addressing)라고 한다.
- 네트워크 크기를 가변적으로 조정해
- 정의만 읽었는 때는 아리송하지만, 실제 클래스를 보면 이해가 쉽다.
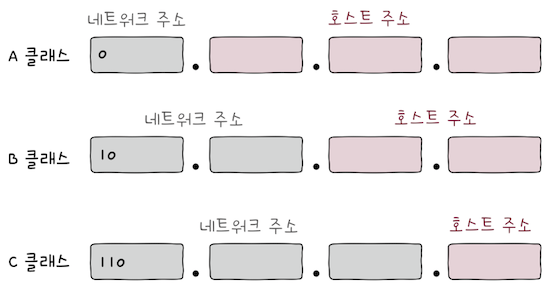
총 5개의 클래스(A, B, C, D, E 클래스)가 있다.
- 이 중
D 클래스는 멀티캐스트를 위한 클래스, E 클래스는 특수목적을 위해 예약된 클래스이기 때문에,- 네트워크의 크기를 나누는데 실질적으로 사용되는 클래스는
A, B, C이다.
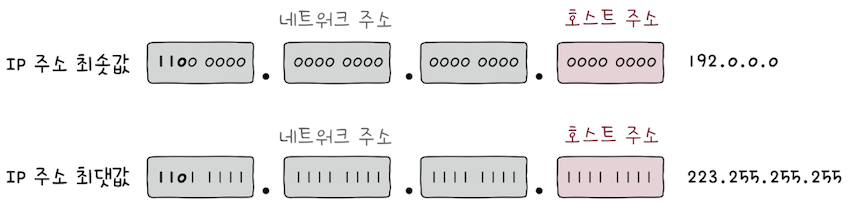
A 클래스는 B와 C 클래스에 비해, 할당 가능한 호스트 주소의 수가 많다.
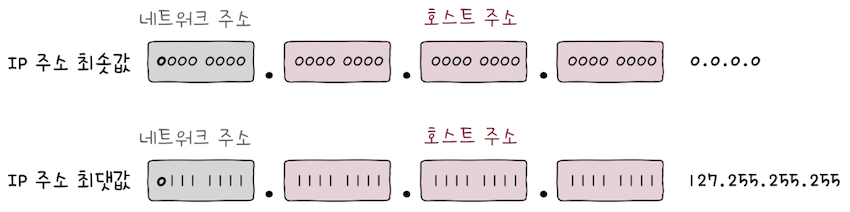
네트워크 주소는비트 ‘0’으로 시작하고1옥텟으로 구성되며,호스트 주소는3옥텟으로 구성된다.- 이론상으로 (128)개의 A클래스 네트워크가 존재할 수 있고,
- (16,777,216)개의 호스트 주소를 가질 수 있다.
A 클래스로 나타낼 수 있는 IP 주소의 최소값을 10진수로 표현하면0.0.0.0,- 최대값을 10진수로 표현하면,
127.255.255.255이다. - 요컨대 가장 처음 옥텟의 주소가 0~127일 경우,
A 클래스 주소임을 짐작할 수 있다.
- 최대값을 10진수로 표현하면,
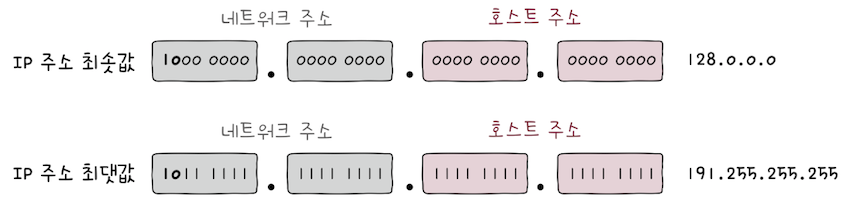
B 클래스의 네트워크 주소는 비트 ‘10’으로 시작하고, 2옥텟으로 구성되며, 호스트 주소도 2옥텟으로 구성된다.
- 이론상으로 (128)개의 B클래스 네트워크와 각 네트워크에 속한 (65,534)개의 호스트 주소를 가질 수 있다.
B 클래스IP 주소의 최소값을 10진수로 표현하면128.0.0.0,- 최대값을 10진수로 표현하면,
191.255.255.255이다. - 따라서 가장 처음 옥텟의 주소가 128~191일 경우,
B 클래스 주소임을 짐작할 수 있다.
- 최대값을 10진수로 표현하면,
C 클래스의 네트워크 주소는 비트 ‘110’으로 시작하고, 3옥텟으로 구성되며, 호스트 주소도 1옥텟으로 구성된다.
- 이론상으로 (2,097,152)개의 C클래스 네트워크와 각 네트워크에 속한 (256)개의 호스트 주소를 가질 수 있다.
C 클래스IP 주소의 최소값을 10진수로 표현하면192.0.0.0,- 최대값을 10진수로 표현하면,
223.255.255.255이다. - 따라서 가장 처음 옥텟의 주소가 192~223일 경우,
C 클래스 주소임을 짐작할 수 있다.
- 최대값을 10진수로 표현하면,
다만 호스트의 주소 공간을 모두 사용할 수 있는 것은 아니다.
호스트 주소가 전부 0인 IP 주소와호스트 주소가 전부 1인 IP 주소는- 특정 호스트를 지칭하는 IP 주소로 활용할 수 없다.
- 전자는 해당 네트워크 자체를 의미하는 네트워크 주소로 사용되고,
- 후자는 브로드캐스트를 위한 주소로 사용되기 때문이다.
| 클래스 | 초기 비트 | 네트워크 주소비트/호스트 주소비트 | 할당가능한 네트워크 수 | 할당가능한 호스트 수 |
|---|---|---|---|---|
| A | 0 | 8/24 | - 2 | |
| B | 10 | 16/16 | - 2 | |
| C | 110 | 24/8 | - 2 |
- 즉,
A 클래스는 이론상으로는 (16,777,216)개의 주소를 호스트에 할당할 수 있지만,- 실제로 할당가능한 주소는
16,777,216 - 2개인16,777,214개이다.
- 실제로 할당가능한 주소는
- 마찬가지로
B 클래스는 이론상 (65,536)개의 주소를 호스트에 할당할 수 있지만,- 실제로 할당 가능한 주소는
65,536 - 2개인65,534개다.
- 실제로 할당 가능한 주소는
C 클래스는 이론상 (256)개의 주소를 호스트에 할당할 수 있지만,- 실제로 호스트에게 할당 가능한 주소는
256 - 2개인254개다.
- 실제로 호스트에게 할당 가능한 주소는
2.3 클래스리스 주소 체계
클래스풀 주소 체계를 이용하면,
- 네트워크의 영역을 결정하고 할당 가능한 호스트의 주소 공간을 유동적으로 관리할 수 있지만, 이 방식에는 한계가 있다.
클래스별 네트워크의 크기가 고정되어 있기에, 여전히 다수의 IP 주소가 낭비될 가능성이 크다는 문제가 있다.- e.g.
A 클래스네트워크 하나당 할당 가능한 호스트 IP 주소는 1,600만 개 이상이고,B 클래스네트워크 하나당 할당 가능한 호스트 IP 주소는 6만개가 넘는다.- 단일 조직에서 이 정도의 호스트가 필요한 경우는 많지 않다.
- 게다가 사전에 정해진
A, B, C 클래스외에는 다른 크기의 네트워크를 구성할 수도 없다.
- e.g. 300명의 직원이 사용할 컴퓨터들을 동일한 네트워크로 구성하고 싶을 떄,
클래스풀 주소체계에서는 어쩔 수 없이B 클래스주소를 이용해야만 한다.C 클래스주소는 호스트에게 할당할 수 있는 IP 주소는 254개뿐이기 때문이다.
그래서 클래스풀 주소 체계보다 유동적이고, 정교하게 네트워크를 구획할 수 있는 클래스리스 주소체계(classless addressing)가 등장했다.
- 이름처럼
클래스 개념없이(classless)클래스에 구애받지 않고,- 네트워크의 영역을 나누어서, 호스트에게 IP 주소 공간을 할당하는 방식이다.
- 오늘날 주로 사용되는 방식으로, 이번 절의 핵심이다.
2.3.1 서브넷 마스크
클래스풀 주소 체계는 클래스를 이용해,네트워크 주소와호스트 주소를 구분하지만,클래스리스 주소 체계는 클래스를 이용하지 않으므로,- IP 주소상에서
네트워크 주소와호스트 주소를 구분짓는 지점은 임의의 지점이 될 수 있다. - 클래스리스 주소 체계에서는
네트워크와호스트를 구분짓는 수단으로서브넷 마스크를 사용한다.
- IP 주소상에서
서브넷 마스크(subnet mask)는 IP 주소 상에서 네트워크 주소는 1, 호스트 주소는 0으로 표기한 비트열을 의미한다.
- 네트워크 내의 부분적인 네트워크(
서브네트워크(subnetwork))를 구분짓는 (마스크(mask)) 비트열인 셈이다. - 서브넷 마스크를 이용해 클래스를 원하는 크기로 더 잘게 쪼개어 사용하는 것을
서브네팅(subnetting)이라 한다.
💡
서브네트워크는IP 주소의 네트워크 주소로 구분가능한네트워크의 부분 집합이다.
서브넷(subnet)이라고 줄여서 부르기도 한다.
클래스풀 주소 체계에서
A 클래스의 네트워크 주소는8비트,B 클래스의 네트워크 주소는16비트,C 클래스의 네트워크 주소는24비트로 이루어져 있다.
그렇기에 A, B, C, D 클래스의 기본 서브넷 마스크는 다음과 같다.
A 클래스:255.0.0.0 (1111 1111. 0000 0000. 0000 0000. 0000 0000)B 클래스:255.255.0.0 (1111 1111. 1111 1111. 0000 0000. 0000 0000)C 클래스:255.255.255.0 (1111 1111. 1111 1111. 1111 1111. 0000 0000)
2.3.2 서브네팅: 비트 AND 연산
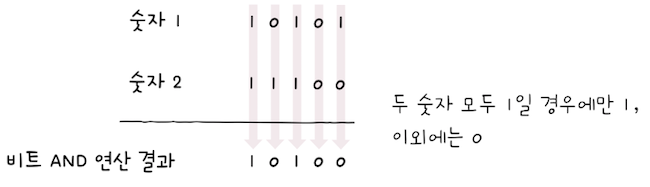
서브넷 마스크를 이용해 네트워크 주소와 호스트 주소를 구분짓는 방법은 단순하다.
IP 주소와서브넷 마스크를 비트 AND 연산하면 된다.비트 AND 연산(bitwise AND operation)이란 피연산자가 모두 1인 경우에는 1,- 아닌 경우에는 0이 되는 연산이다.
다음과 같은 IP 주소와 서브넷 마스크가 있다고 가정해보면,
- IP 주소 :
192.168.219.103 - 서브넷 마스크 :
255.255.255.0
이 IP 주소와 서브넷 마스크를 2진수로 표기하면, 다음과 같다.
- IP 주소 :
1100 0000. 1010 1000. 1101 1011. 0110 0111 - 서브넷 마스크 :
1111 1111. 1111 1111. 1111 1111. 0000 0000

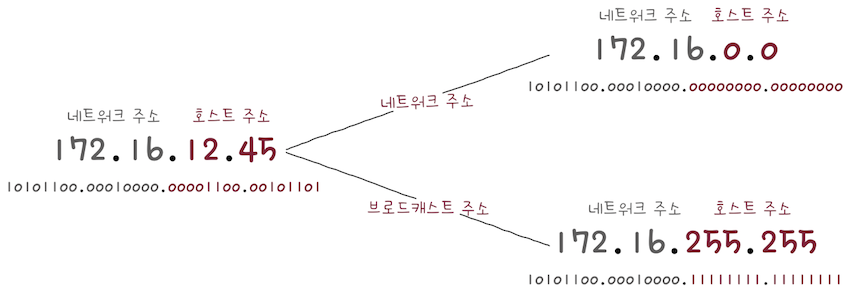
이 둘에 대해 비트 AND 연산을 수행하면, 다음 결과처럼 네트워크 주소 192.168.219.0을 구할 수 있다.
사용된 서브넷 마스크에서 0이 8개이므로, 호스트 주소는 8비트로 표현 가능하다.
따라서 실제로 할당 가능한 호스트 IP주소는
- 호스트 주소가 모두 0인
네트워크 주소 192.168.219.0과 - 호스트 주소가 모두 1인
브로드캐스트 주소 192.168.219.255를 제외한 192.168.219.1~192.168.219.254, 즉 254개가 된다.
정리하면, 클래스리스 주소 체계는 클래스가 아니라, 서브넷 마스크를 이용해 네트워크 주소와 호스트 주소를 구분하는 IP 주소 체계다. 또한 서브넷 마스크와 IP 주소 간에 비트 AND 연산을 수행하면, IP 주소 내의 네트워크 주소를 알아낼 수 있다.
💡
서브넷 마스크는서브넷을 구분하기 위해 사용하는 비트열로,네트워크 주소는 1,호스트 주소는 0으로 표현한다.
2.3.2 서브넷 마스크 표기: CIDR 표기법
서브넷 마스크를 표기하는 방법은 크게 2가지가 있다.
- 위 예시와 같이
서브넷 마스크를255.255.255.0,255.255.255.252처럼 10진수로 직접 표기하는 법 IP 주소/서브넷 마스크상의1의 개수형식으로 표기하는 방법
여기서 2번쨰 방식인 IP 주소/서브넷 마스크상의 1의 개수로 표기하는 형식을 CIDR 표기법(Classless Inter-Domain Routing notation)이라 부른다. IP 주소와 서브넷 마스크를 함께 표현할 수 있는 간단한 표기로 많이 활용된다.
e.g. C 클래스의 기본 서브넷 마스크는 255.255.255.0이다.
- 이를 2진수로 표기하면,
1111 1111. 1111 1111. 1111 1111. 0000 0000이다. - CIDR 표기법을 따르면, 다음과 같이
/24로 표기할 수 있다. IP 주소 192.168.219.103과서브넷 마스크 255.255.255.0→192.168.219.103/24

e.g. 복습을 위해 192.168.0.2/25라는 표기가 있다고 가정하면, 어떤 네트워크에 속한 어떤 호스트를 가리킬까?
- 우선 네트워크 주소와 호스트 주소를 구해보면,
- IP 주소를 나타내는
192.168.0.2를 2진수로 표현하면,1100 0000. 1010 1000. 0000 0000. 0000 0010이다.
- 그리고 서브넷 마스크를 나타내는
/25는 1이 총 25개,1111 1111. 1111 1111. 1111 1111. 1000 0000을 의미한다.- 10진수로 표현하면
255.255.255.128과도 같다.

서브넷 마스크를 IP 주소 192.168.0.2와 비트 AND 연산을 하면 그 결과는 192.168.0.0이다.
- 즉, 네트워크 주소는
192.168.0.0이 된다. 호스트는7비트로 표현할 수 있다.- 할당 가능한
호스트 IP 주소의 범위는192.168.0.0과브로드캐스트 주소는192.168.0.127을 제외하면,192.168.0.1~192.168.0.126이 된다.
- 즉,
192.168.0.2/25는 총 126개의 호스트를 할당할 수 있는192.168.0.0이라는 네트워크에 속한 2라는 호스트를 의미한다.
💡
클래스리스 주소 체계: 클래스를 이용하지 않고, 서브넷 마스크나 CIDR 표기법으로 네트워크 주소와 호스트 주소를 구분짓는 방법
2.4 공인 IP 주소와 사설 IP 주소
IP 주소가 낭비될 수 있다라고 표현했었으니까, IP 주소는 마치 MAC 주소와 같은 유일한 주소라고 생각할 지도 모른다.
- 하지만 이는 반만 맞는 이야기다.
- 전 세계에는
고유한 IP 주소가 있고,고유하지 않은 IP 주소도 있다. - 지금까지는 전자에 대해 설명했고, 이를
공인 IP 주소라고 부른다.
2.4.1 공인 IP 주소
공인 IP 주소(public IP Address)는 전 세계에서 고유한 IP 주소다.
- 네트워크 간의 통신, 이를테면, 인터넷을 이용할 떄 사용하는 IP 주소가
공인 IP 주소다. - 공인 IP 주소는 ISP나 공인 IP 주소 할당 기관을 통해 할당받을 수 있다.
- cf. 한국인터넷정보센터 KRNIC IPv4 주소 신청 웹페이지
2.4.2 사설 IP 주소와 NAT
사설 IP 주소(private IP address)란 사설 네트워크에서 사용하기 위한 IP 주소다.
사설 네트워크란 인터넷, 외부 네트워크에 공개되지 않은 네트워크를 의미한다.- 우리가 사용하는 모든 네트워크 기기의 IP 주소를 전부 별도로 신청해서 할당받지는 않는다.
- 그 이유는
LAN 내의 많은 호스트는 사설 IP 주소를 사용하기 떄문이다.
IP 주소 공간 중에서 사설 IP 주소로 사용하도록, 특별히 예약된 IP 주소 공간이 있다.
다음 범위에 속한 IP 주소는 사설 IP 주소로 간주하기로 약속되어 있다.
10.0.0.0/8 (10.0.0.0 ~ 10.255.255.255)172.16.0.0/12 (172.16.0.0 ~ 172.31.255.255)192.168.0.0/16 (192.168.0.0 ~ 192.168.255.255)
사설 IP 주소의 할당 주체는 일반적으로 라우터다.
할당받은 사설 IP 주소는 해당 호스트가 속한사설 네트워크상에서만 유효한 주소로,- 얼마든지
다른 네트워크상의 사설 IP 주소와 중복될 수 있다.
e.g. 위에 명시한 사설 IP 주소 범위에 속한 192.168.0.2 주소도 타 사설 네트워크 내 호스트와 얼마든지 중복될 수 있다.
- 그래서
192.168.0.2란사설 IP 주소만으로는 일반적인 인터넷 접속을 비롯한 외부 네트워크 간의 통신이 어렵다.
그러면, 사설 IP 주소를 사용하는 호스트가 외부 네트워크와 통신하려면 어떻게 해야할까?
- 이떄 사용되는 기술이
NAT(Network Address Translation)이다. NAT은 IP 주소를 변화하는 기술이다.- 주로 네트워크 내부에서 사용되는
사설 IP 주소와 네트워크 외부에서 사용되는공인 IP 주소를 변환하는데 사용된다. NAT를 통해 사설 IP 주소를 사용하는 여러 호스트는 적은 수의공인 IP 주소를 공유할 수 있다.
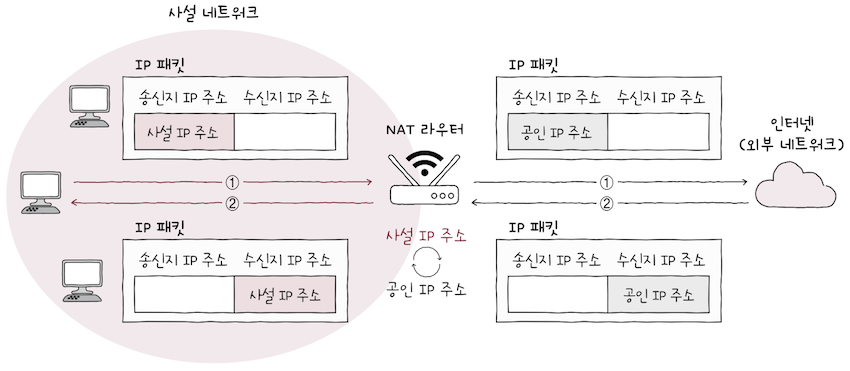
대부분의 라우터와 가정용 공유기는 NAT 기능을 내장하고 있다.
- 그렇기에 (1) 사설 네트워크상에서 만들어진 패킷 속
사설 IP 주소는 공유기를 거쳐공인 IP로 변경되고,- 외부 네트워크로 전송된다.
- (2) 반대로 외부 네트워크로부터 받은 패킷 속
공인 IP 주소는 공유기를 거쳐사설 IP 주소로 변경되어,- 우리들의 사설 네트워크 속 호스트에 이르게 된다.
💡 NAT의 동작 방식을 보다 정확히 이해하려면, 전송 계층의
포트라는 개념을 이해해야 한다.
- 다만 이번 절에는
공인 IP 주소와사설 IP 주소의 차이점과NAT가 어떤 기술인지만 이해해도 좋다.
컴퓨터의 공인 IP 주소와 사설 IP 주소를 간단히 확인해보자.
윈도우운영체제는 명령 프롬프트(CMD)에ipconfig를맥 OS운영체제는 터미널에ifconfig에 입력하면, IP(IPv4) 주소를 조회할 수 있다.- 만일
10.0.0.0/8,172.16.0.0/12,192.168.0.0/16중 하나가 보인다면, 이는사설 IP 주소다.
1$ ipconfig2... 중략3무선 LAN 어댑터 Wi-Fi:4연결별 DNS 접미사 .... :5링크-로컬 IPv6 주소 .... : abcd:abcd:abcd:abcd:abcd%176IPv4 주소 ........... : 192.168.0.3 # 사설 IP 주소7서브넷 마스크 ......... : 255.255.255.08기본 게이트웨이 ........ : 192.168.0.1
네이버나 구글같은 검색 사이트에서도 IP 주소를 확인할 수 있다.
- 웹 브라우저에
www.naver.com혹은www.google.com을 입력했을 떄, 웹 페이지가 보이는 것은 네이버나 구글의 서버 호스트와개인의 컴퓨터가 패킷을 주고받는 과정이라고 볼 수 있다.- 이떄
네이버나 구글의 서버 호스트가 인식한개인 IP 주소는사설 IP 주소가 아닌공인 IP주소다.
네이버 검색창에 내 IP 주소를 입력하거나 구글 검색창에 what is my ip address를 입력해보세요.
- 네이버나 구글은
개인의 사설 IP 주소가 아닌공인 IP 주소를 인식하기 때문에,공인 IP 주소를 표시해준다.
2.5 정적 IP 주소와 동적 IP 주소
호스트에 IP 주소를 할당하는 방법을 알아보자. 여기에는 크게 2가지 방법이 있다.
정적 할당: 수작업을 통해 이루어짐동적 할당: 일반적으로 DHCP 프로토콜을 통해 이루어짐
2.5.1 정적 할당
정적 할당은 호스트에 직접 수작업으로 IP 주소를 부여하는 방식이다.
- 이렇게 호스트에 수작업으로 할당된 IP 주소를
정적 IP 주소(static IP Address)라고 부른다.
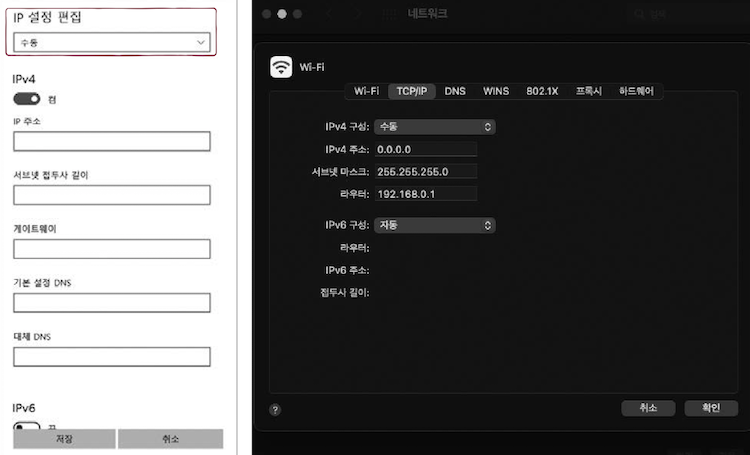
윈도우나 맥 OS 등의 운영체제에서 네트워크 설정을 확인해보면,
- 위 그림처럼
IP 주소를 수동으로 설정할 수 있는 항목이 존재한다. - 이곳에
정적 IP 주소를 부여할 수 있다. 정적 IP 주소를 부여하기 위해 입력해야 하는 값은 대체로 유사하다.- 일반적으로 부여하고자 하는
IP 주소,서브넷 마스크,게이트웨이(라우터) 주소,DNS 주소를 입력한다. - 그러면 해당
호스트는 입력한 IP 주소에 해당하는 고정된 주소를 가지게 된다. - cf. DNS는 5장에서 배운다. 실습을 겸하고 있다면,
8.8.8.8을 입력하면 된다.
💡 기본 게이트웨이(default gateway)
게이트웨이의 일반적인 의미는 서로 다른 네트워크를 연결하는 하드웨어/소프트웨어적 수단을 의미한다.
- 그 중에서도
기본 게이트웨이는 호스트가 속한 네트워크 외부로 나가기 위한 기존적인 첫 경로(첫 번쨰 홉)을 의미한다.- 그래서 기본 게이트웨이는 네트워크 외부와 연결된 라우터(공유기)의 주소를 의미하는 경우가 많다.
- IP 할당의 맥락에서 사용된
게이트웨이라는 용어는 기본 게이트웨이를 의미하기 때문에,
- 위 화면 속
[게이트웨이]항목과[라우터]항목에는- 공통적으로 기본 게이트웨이 역할을 하는
라우터(공유기)의 주소를 적어주면 된다.- cf.
IP 주소의 정적 할당은 사용자가 호스트에 직접 고정된 IP 주소를 할당하는 방식이다.
2.5.2 동적 할당과 DHCP
IP 주소를 정적으로만 할당하다 보면, 호스트의 수가 많아질 경우 관리가 곤란해질 수 있다.
- 의도치 않게 잘못된 IP 주소를 입력할 수도 있고, 중복된 IP 주소를 입력할 수도 있다.
이럴 떄 사용 가능한 IP 주소 할당 방식이 동적할당이다.
동적 할당은정적 할당과는 달리,IP 주소를 직접 일일이 입력하지 않아도,호스트에IP 주소가 동적으로 할당하는 방식이다.
- 이렇게 할당된 IP 주소는
동적 IP 주소(dynamic IP Address)라고 부른다.
동적 IP 주소는 사용되지 않을 경우 회수되고, 할당받을 때마다 다른 주소를 받을 수 있다.
- 스마트폰이나 노트북을 이용할 떄, 수동으로
IP 주소를 설정하지 않고,- 인터넷을 이용할 수 있는 것은 십중팔구
IP 주소가 동적으로 할당되었기 때문이다. - 그만큼
동적할당과동적 IP 주소는 일살적으로 사용된다.
- 인터넷을 이용할 수 있는 것은 십중팔구
IP 동적 할당에 사용되는 대표적인 프로토콜이 DHCP(Dynamic Host Configuration Protocol)이다.
동적 IP 주소를 일상적으로 사용하는 만큼,DHCP또한 빈번히 사용된다.- 그렇다면 DHCP는 호스트에게 IP 주소를 어떻게 할당할까?
- DHCP는 사실 응용 계층에 속하지만, 네트워크 계층의 개념을 이해하는데 도움이 되므로 동작과정을 살펴보자.
- cf. IPv4 주소를 동적으로 할당하는 프로토콜은
DHCPv4이고,- IPv6 주소를 동적으로 할당하는 프로토콜은
DHCPv6이다. - 이어질 내용은 DHCPv4를 기본으로 설명한다.
- IPv6 주소를 동적으로 할당하는 프로토콜은
DHCP를 통한 IP 주소 할당은 IP 주소를 할당받고자 하는 호스트(이하 클리이언트)와 해당 호스트에게 IP 주소를 제공하는 DHCP 서버(DHCP Server) 간에 메시지를 주고받음으로써 이루어진다.
- 여기서
DHCP 서버의 역할은 일반적으로라우터(공유기)가 수행하지만,특정 호스트에DHCP 서버기능울 추가할 수도 있다.
DHCP 서버는클라이언트에게 할당가능한 IP 주소 목록을 관리하다가,클라이언트가 요청할 떄, IP 주소를 할당한다.
주의할 점은 DHCP로 할당받은 IP 주소는 사용할 기간(임대 기간)이 정해져 있다는 점이다.
- 임대기간은 DHCP 서버에서 설정하기 나름이지만, 일반적으로 수 시간에서 수일로 설정한다.
- 임대기간이 끝난
IP 주소는 다시DHCP 서버로 반납된다. - 그래서 DHCP를 통해 IP 주소를 할당받는 것을
IP 주소를 임대한다라고 표현하기도 한다.
윈도우 운영체제 사용자는 명령 프롬프트(CMD)를 열고 ipconfig /all를 입력해보세요.
DHCP 서버 주소와 임대 기간을 볼 수 있다.
1$ ipconfig /all2... 중략3이더넷 어댑터 이더넷 2:4연결별 DNS 접미사 ..........:5설명 .....................: Realtek USB FE Family Controller #26물리적 주소 ................: A1-B2-C3-D4-E5-F67DHCP 사용 ................: 예8자동 구성 사용 .............: 예9링크-로컬 IPv6 주소 ........: abcd::abcd:abcd:abcd:abcd%1710IPv4 주소 ................: 192.168.0.7(기본 설정)11서브넷 마스크 ..............: 255.255.255.012임대 시작 날짜 .............: 2024년 4월 22일 월요일 오전 12:34:4713임대 만료 날짜 .............: 2024년 4월 25일 월요일 오전 4:47:1314기본 게이트웨이 .............: 192.168.0.115DHCP 서버 ................: 192.168.0.116... 후략
IP 주소를 할당받는 과정에서 클라이언트와 DHCP 서버 간에 주고받는 메시지의 종류는 크게 4가지가 있다.
- DHCP Discover
- DHCP Offer
- DHCP Request
- DHCP Acknowledgment (이하 DHCP ACK)
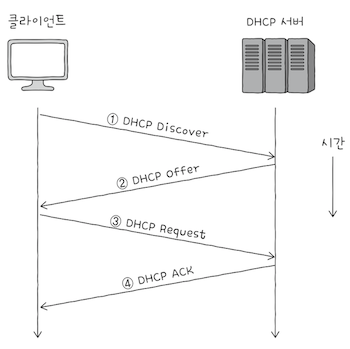
클라이언트는 DHCP 서버, Discover, Offer, Request, ACK 순으로 메시지를 주고받으며, IP 주소를 할당받는다.
- cf. 이 메시지들을 주고받는 것은 DHCP 패킷을 주고받는 것과 같다.
- 그렇다면 DHCP Discover 메시지부터 알아보자.
(1) DHCP Discover (클라이언트 → DHCP 서버)
- Discover는 영어로 ‘발견하다’라는 의미로,
- 이름처럼
클라이언트는 DHCP Discover 메세지를 통해 DHCP 서버를 찾는다.- 이는
브로드캐스트로 전송된다.
- 이는
DHCP Discover 메시지를 전송하는 시점에클라이언트는 아직 IP 주소를 할당받지 못했으므로,송신지 IP 주소는0.0.0.0으로 설정된다.
(2) DHCP Offer (DHCP 서버 → 클라이언트)
DHCP 서버는DHCP Discover 메세지를 받은 뒤, 클라이언트에게DHCP Offer 메시지를 보낸다.Offer는 영어로 ‘제안하다’라는 의미로,- 즉,
이 메시지는 클라이언트에게 할당해줄 IP 주소를 제안하는 메시지다.
- 즉,
클라이언트에게 제안할IP 주소뿐만 아니라,서브넷 마스크,임대 기간등의 정보도 포함되어 있다.
(3) DHCP Request (클라이언트 → DHCP 서버)
DHCP Request는DHCP Offer 메시지에 대한 응답이다.- 이 또한 브로드캐스트로 전송된다.
- 비유하면, “DHCP Offer 메시지를 잘 받았는데, 이 IP 주소를 써도 돼?”라고 묻는 것과 같다.
(4) DHCP ACK ( DHCP 서버 → 클라이언트)
- 마지막으로
DHCP 서버는클라이언트에게DHCP ACK 메시지를 보낸다. - 이 메시지는 마치 최종 승인과도 같은 메시지다.
DHCP ACK 메시지까지 받은클라이언트는 이제할당받은 IP 주소를자신의 IP 주소로 설정한 뒤,- 임대 기간 동안
IP 주소를 사용한다.
- 임대 기간 동안
IP 주소의 사용 기간이 모두 끝나, IP 주소가 DHCP 서버에 반납되면,
- 원칙적으로는 이 과정을 거쳐서
IP 주소를 재할당받아야 한다. - 하지만
IP 주소 임대 기간이 끝나기 전에 임대 기간을 연장할 수도 있다.- 이를
임대 갱신(lease renewal)이라 한다. 임대 갱신은IP 주소의 임대 기간이 끝나기 전에, 기본적으로 2차례 자동으로 수행된다.- 만일 자동으로 수행되는
임대 갱신 과정이 모두 실패하면, 그떄IP 주소는DHCP 서버로 반납된다.
- 이를
- cf.
IP 주소의 동적 할당은 호스트에IP 주소를 자동으로 할당하는 방식으로,- 일반적으로
DHCP라는 프로토콜을 이용한다.
- 일반적으로
2.5.3 예약 주소: 0.0.0.0 vs 127.0.0.1
특수한 목적을 위해 예약된 IP 주소도 있다. 대표적인 예약 주소와 사용목적은 다음과 같다.
| 예약 주소 | IP 범위 | 사용 목적 |
|---|---|---|
0.0.0.0/8 | 0.0.0.0 ~ 0.255.255.255 | 이 네트워크의 이 호스트 |
| 10.0.0.0/8 | 10.0.0.0 ~ 10.255.255.255 | 사설 네트워크 |
127.0.0.0/8 | 127.0.0.0 ~ 127.255.255.255 | 루프백(loopback) 주소 |
| 169.254.0.0/16 | 169.254.0.0 ~ 169.254.255.255 | 링크 로컬(link local) 주소 (호스트가 연결도니 링크로 통신 범위가 제한된 주소) |
| 172.16.0.0/12 | 172.16.0.0 ~ 172.31.255.255 | 사설 네트워크 |
| 192.0.2.0/24 | 192.0.2.0 ~ 192.0.2.255 | 테스트용 |
| 192.168.0.0/16 | 192.168.0.0 ~ 192.168.255.255 | 사설 네트워크 |
| 198.18.0.0/15 | 198.18.0.0 ~ 198.19.255.255 | 테스트용 |
| 224.0.0.0/4 | 224.0.0.0 ~ 239.255.255.255 | 멀티캐스트(D 클래스) |
| 240.0.0.0/4 | 240.0.0.0 ~ 255.255.255.254 | 미래 사용 용도로 예약 (E 클래스) |
예약 주소 중에서 색으로 강조된 부분은 이번 절에서 설명한 사설 네트워크에서 사용되는 IP 주소다.
- 이외에도 개발자 입장에서 자주 접하게 될 중요한 예약 IP 주소로, 네모로 강조표시한 루프백 주소와 0.0.0.0이 있다.
루프백 주소는 자기 자신을 가리키는 특별한 주소다.- 가장 일반적으로 사용되는 주소는
127.0.0.1이고,로컬호스트(localhost)라고 부른다. 루프백 주소로 전송된 패킷은 자기 자신에게 되돌아오므로,- 자기 자신을 마치 다른 호스팅인 양 간주하여 패킷을 전송할 수 있다.
- 부메랑 역할을 수행하는 주소라고 볼 수 있다.
루프백 주소는 주로 테스트나 디버깅 용도로 사용된다.
- 가장 일반적으로 사용되는 주소는
0.0.0.0/8은 인터넷 표준 공식 문서(RFC 6890)에 따르면,- ‘이 네트워크의 이 호스트(This host on this network)를 지칭하도록 예약되었다’라고 명시되어 있다.
- 이번 절에 DHCP Discover를 설명할 떄,
- “DHCP Discover 메시지를 전송하는 시점에 클라이언트는 아직 IP 주소를 할당받지 못했으므로,
- 송신지 IP 주소는 0.0.0.0으로 설정된다“고 배웠다.
- 이처럼
0.0.0.0/8은 호스트가 IP 주소를 할당받기 전에 임시로 사용하는 경우가 많다. - 호스트 입장에서 자신을 지칭할 IP 주소가 없기 때문에,
이 네트워크의 이 호스트로 자신을 지칭한다.
- 이와 유사하지만, 다른 의미를 지니는 주소로
0.0.0.0/0도 있다.- 이 또한 자주 사용되는 특수한 주소로
모든 임의의 IP 주소를 의미한다. - 이 주소는 주로 패킷이 이동할 경로를 결정하는 라우팅에서 활용되는데,
- 디폴트 라우트를 나타내기 위해 사용된다.
디폴트 라우트(default route)란 패킷을 어떤 IP 주소로 전달하지 결정하기 어려울 경우,- 기본적으로 패킷을 전달할 경로를 의미한다.
- 즉, 어디로 패킷을 전달해야 할지 명확하지 않을 경우, 이곳으로 패킷을 이동시키라고 표기하는 셈이다.
- 라우팅과 디폴트 라우트는 다음 절에서 배운다.
- 이 또한 자주 사용되는 특수한 주소로
3. 라우팅
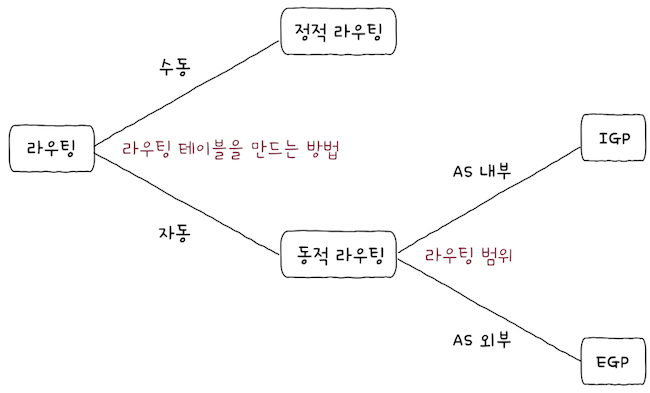
라우터의 핵심 기능은 패킷이 이동할 최적의 경로를 설정한 뒤, 해당 경로로 패킷을 이동시키는 것이다.
- 이를
라우팅이라고 한다.- 라우팅은 여기에 모두 다루기에는 어렵다.
- 그렇기에 여기서는 라우팅의 분류에 주안점을 두고 배운다.
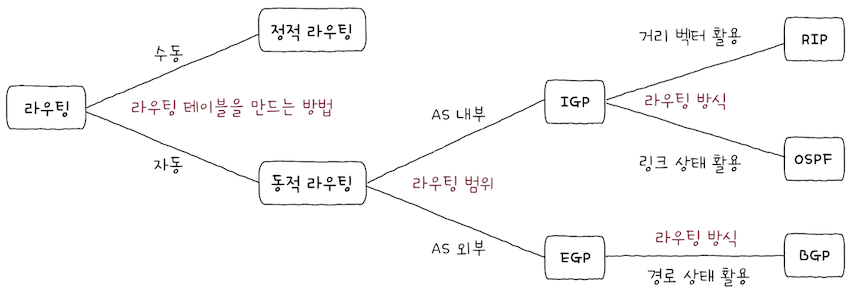
- 라우팅 테이블이 만들어지는 방법과 프로토콜에 따라 라우팅을 분류하면 위 그림과 같이 표현할 수 있다.
3.1 라우터
네트워크 계층의 장비로 라우터만 알아도 큰 무리가 없을 정도로, 라우터는 네트워크 계층의 핵심 기능을 담당하다.
- 사실
L3 스위치(switch)라고 부르는 장치도 네트워크 계층의 대표 장치기도 하지만, - 오늘날
라우터와L3 스위치는 기능상 상당 부분 유사하므로, 얼밀히 구분하지 않는 경우가 많다. - 여기서도 네트워크 계층의 장비로
라우터만 살펴본다.
라우터는 학습한 허브나 스위치보다 높은 계층에 속하는 장치이므로, 기능적으로는 사실상 개인컴퓨터와 매우 유사하다.
💡 일반 가정환경에서는 공유기가 라우터의 역할을 대신한다.
- 이런 점에서
공유기를홈 라우터(home router)라고 부른다.- 사실
공유기는라우터 기능뿐만 아니라NAT 기능, DHCP 서버 기능, 보안을 위한 방화벽 기능등 다양한 장치의 기능이 함축된 네트워크 장비라고 볼 수 있다.
멀리 떨어져 있는 호스트 간의 통신 과정에서 패킷은 서로에게 도달하기까지,
- 여러
라우터를 거쳐 다양한 경로를 이동할 수 있다. - e.g. 지구 반대편의 친구에게 이메일을 보낸다고 가정해보면,
- 그 이메일은 여러 대의 라우터를 거쳐, 지구 반대편 친구에게 다다른다.
- 우리가 보낸 패킷은 여러 대의 라우터를 깡충깡충 거치듯이 수신지까지 이동하는 셈이다.

이처럼 라우팅 도중 패킷이 호스트와 라우터 간에,
- 혹은 라우터와 라우터 간에 이동하는 하나의 과정을
홉(hop)이라 부른다. - 즉, 패킷은
여러 홉을 거쳐라우팅될 수 있다.
우리가 웹 브라우저에 www.google.com을 입력해,
- 구글 웹페이지를 확인하는 것도 웹 브라우저가 구글의 컴퓨터가 패킷을 주고받는 과정이다.
- 물론 구글의 컴퓨터는 우리의 LAN이 아닌 멀리 떨어져 있는 곳에 존재한다.
- 개인 컴퓨터와 구글의 컴퓨터가 주고받는
패킷은 여러 네트워크 장비를 거치는 수 많은홉과경로를 통해 이동한다.
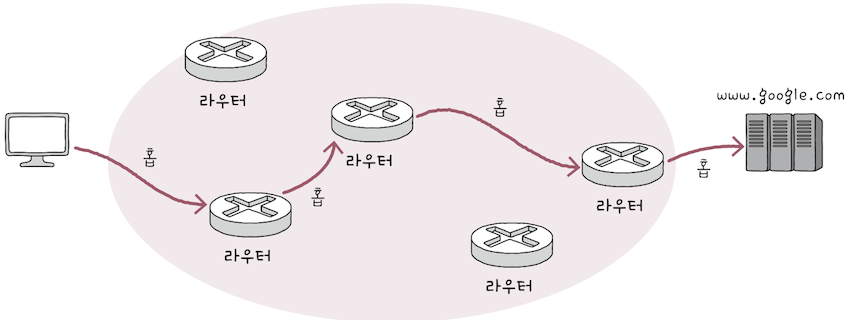
이를 직접 확인해보면,
- 윈도우 운영체제에서 명령프롬프트(CMD)에
tracert www.google.com을, - 맥OS, 리눅스 운영체제에서 터미널에
traceroute www.google.com이라고 입력하면, - 다음과 같이
개인 컴퓨터로부터 구글 웹페이지를 보내주는 호스트를 보내주는호스트에 이르기까지의 경로가 출력된다. - cf. 패킷은 여러 홉을 거쳐 다른 네트워크 내의 호스트로 이동할 수 있다.
1$ traceroute www.google.com2traceroute to www.google.com (142.250.66.110), 64 hops max, 52 byte packets31 192.168.219.1 (192.168.219.1) 7.140 ms 3.289 ms 4.244 ms42 123.456.789.123 (123.456.789.123) 5.781 ms 6.884 ms *53 321.654.987.321 (321.654.987.321) 17.071 ms 6.871 ms 6.636 ms6... (중략)7209.85.142.27 (209.85.142.27) 64.538 ms8216.239.63.217 (216.239.63.217) 64.482 ms915 hkg12s28-in-f14.1e100.net (142.250.66.110) 42.446 ms 61.722 ms10108.170.241.65 (108.170.241.65) 41.313 ms
각 IP 주소 앞에 붙은 번호가 바로 패킷이 이동한 홉이다. 여기서 15번의 홉을 거친다는 점을 알 수 있다.
- 그렇다면
라우터는 이런 라우팅을 어떻게 수행하는 것일까? 라우터는 패킷을 전달할 다음 홉이 어디인지 어떻게 알까?
3.2 라우팅 테이블
라우팅의 핵심은 라우터가 저장하고 관리하는 라우팅 테이블(routing table)이다.
라우팅 테이블은 특정 수신지까지 도달하기 위한 정보를 명시한 일종의 표와 같은 정보다.라우터는라우팅 테이블을 참고하여, 수신지까지의 도달 경로를 판단한다.
라우터 테이블에 포함된 정보는 라우팅 방식에 따라, 호스트의 환경에 따라 달라질 수 있다.
-
수신지 IP 주소와서브넷 마스크: 최종적으로 패킷을 전달할 대상을 의미한다. -
다음 홉(next hop): 최종 수신지까지 가기 위해 다음으로 거쳐야 할 호스트의 IP 주소나 인터페이스를 의미한다.게이트웨이라고 명시되기도 한다.
-
네트워크 인터페이스: 패킷을 내보낼 통로이다.- 인터페이스(NIC) 이름이 직접적으로 명시되거나, 인터페이스에 대응하는 IP 주소가 명시되기도 한다.
-
메트릭(metric): 해당 경로로 이동하는 데에 드는 비용을 의미한다.- 흔히 매장에서 같은 류의 물건을 살 때면 더 저렴한 물건을 선택한다.
- 일상에서 가성비가 좋은 물품이 선호하듯,
라우터가 라우팅 테이블에 있는 경로 중 패킷을 내보낼 경로를 선택할 떄도 메트릭이 낮은 경로를 선호한다.
e.g. 다음 표와 같은 라우팅 테이블이 있다고 가정해보면,
- 이는 수신지가
192.168.2.0/24(호스트 IP 주소 범위192.168.2.1 ~ 192.168.2.254)인 패킷은 eth0(인터페이스)를 통해192.168.2.1(게이트웨이)로 전송하라는 것을 의미한다.
| 수신지 IP 주소 | 서브넷 마스크 | 게이트웨이 | 인터페이스 | 메트릭 |
|---|---|---|---|---|
| … | … | … | … | … |
| 192.168.2.0 | 255.255.255.0 | 192.168.2.1 | eth0 | 30 |
| … | … | … | … | … |
패킷 내의 수신지가 IP 주소가 라우팅 테이블에 있는 수신지 IP 주소, 서브넷 마스크 항목과 완벽하게 합치되는 경우가 있지만, 그렇지 않은 경우도 있다.
- 다시 말해,
라우팅 테이블에 없는 경로로 패킷을 전송해야 할 떄가 있다. - 이 경우 기본적으로 패킷을 내보낼 경로를 설정하여, 해당 경로로 패킷을 내보낼 수 있다.
- 이 기본 경로를
디폴트 라우트(default route)라 한다.
디폴트 라우트는 모든 IP 주소를 의미하는 0.0.0.0/0로 명시한다.
- e.g.)
수신지 IP 주소가1.2.3.4인 패킷의 경우,- 다음
라우팅 테이블에서 다른 어떤 항목과도 합치되지 않으므로, 색칠된 디폴트 라우트, eth2를 통해192.168.0.1로 전송된다.
- 다음
| 수신지 IP 주소 | 서브넷 마스크 | 게이트웨이 | 인터페이스 | 메트릭 |
|---|---|---|---|---|
| 192.168.2.16 | 255.255.255.240 | 192.168.2.1 | eth0 | 30 |
| 192.168.0.0 | 255.255.0.0 | 192.168.2.2 | eth1 | 30 |
| 0.0.0.0 | 0.0.0.0 | 192.168.0.1 | eth2 | 30 |
앞선 절에서 기본 게이트웨이를 학습했다.
기본 게이트웨이는 호스트가 속한 네트워크 외부로 나아가기 위한 첫 번쨰 경로고,- 일반적으로
라우터 주소를 의미하는 경우가 많다. - 여기서 기본 게이트웨이로 나아가기 위한 경로가
디폴트 라우트인 셈이다.
- 일반적으로
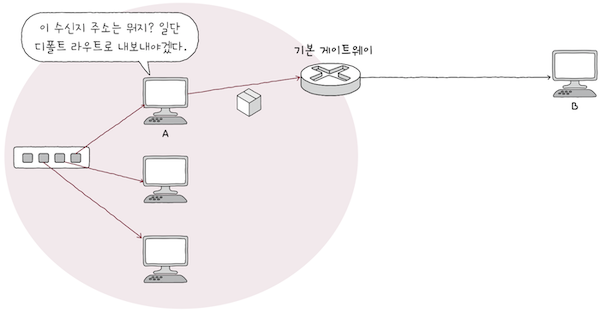
e.g. 네트워크 내부 호스트 A가 네트워크 외부 호스트 B에게 패킷을 전달해야 한다고 가정해보면,
A의 라우팅 테이블에B에 이르는 경로가 따로 없을 경우,A는 우선 패킷을라우터(기본 게이트웨이)에 전달해야 한다.- 이를 위해
A는 라우터 주소인 기본 게이트웨이를디폴트 라우트로 삼는다. - 그럼
A는라우팅 테이블에 따로 수신지 경로가 등록되지 않은 패킷들은 기본적으로라우터에게 전달한다.
그럼 실제로 라우팅이 어떻게 생겼는지 확인해보면,
- 윈도우 사용자는 명령 프롬프트(CMD)를 열고
route print라고 입력해보자. 수신지 IP 주소(네트워크 대상),서브넷 마스크(네트워크 마스크),게이트웨이,인터페이스(에 할당된 IP 주소),메트릭이 출력된다.
1$ route print2IPv4 경로 테이블3==============================================4활성 경로:5네트워크 대상 네트워크 마스크 게이트웨이 인터페이스 메트릭60.0.0.0 0.0.0.0 192.168.0.1 192.168.0.19 4070.0.0.0 0.0.0.0 192.168.0.1 192.168.0.7 358127.0.0.0 255.0.0.0 연결됨 127.0.0.1 3319127.0.0.1 255.255.255.255 연결됨 127.0.0.1 33110127.255.255.255 255.255.255.255 연결됨 127.0.0.1 33111192.168.0.0 255.255.255.0 연결됨 192.168.0.19 296
💡 위 실행 결과에서 [게이트웨이] 항목에
연결됨(혹은 on-link)이라고 표기되는 부분은직접 연결(directly connected)된 경로를 의미한다.- 이는 이름 그대로 직접 접속되어, 곧장 접근할 수 있는 대상을 의미한다.
라우팅 테이블을 구성하는 정보는 라우팅 방식에 따라, 호스트 상황에 따라 달라질 수 있다.
- 맥 OS나 리눅스 운영체제 사용자는 터미널을 열고
netstat -rn을 입력해보자. - 윈도우의 라우팅 테이블과는 조금 다르게 생겼으나,
- 이 또한
수신지 IP 주소와서브넷 마스크,게이트웨이,네트워크 인터페이스(Netif)가 포함되어 있다.
- 이 또한
1$ netstat -rn2Routing tables34Internet:5Destination Gateway Flags Netif Expire6default 192.168.0.1 UCScg en07127 127.0.0.1 UCS lo08127.0.0.1 127.0.0.1 UH lo09169.254 link#13 UCS en0 !10192.168.0 link#13 UCS en0 !11192.168.0.1/32 link#13 UCS en0 !12192.168.0.2/32 link#13 UCS en0 !13255.255.255.255/32 link#13 UCS en0 !14... 생략
다음은 라우터 내부에 저장된 라우팅 테이블의 예시다.
- 차후 배울 라우팅 프로토콜과 더불어 수신지 IP 주소, 메트릭, 게이트웨이, 인터페이스에 대한 정보가 포함되어 있다.
- 처음 라우팅 테이블을 학습하면, 모든 항목을 이해할 필요는 없다.
- 중요한 점은 라우팅을 해주는 네트워크 장비인
라우터는라우팅 테이블을 통해 패킷을 수신지까지 전달할 수 있다는 점이고,라우팅 테이블안에는 네트워크상의 특정 수신지까지 도달하기 위한 정보들이 담겨 있다.
1Route# show ip route2...생략30 E2 1.2.3.4 [160/5] via 100.101.254.6, 0:01:10, Ethernet24# 0 E2 : 라우팅 프로토콜5# 1.2.3.4 : 수신지 IP 주소6# 5 : 메트릭7# 100.101.254.6 : 게이트웨이(다음 라우터)8# Ethernet2 : 인터페이스9...생략
3.3 정적 라우팅과 동적 라우팅
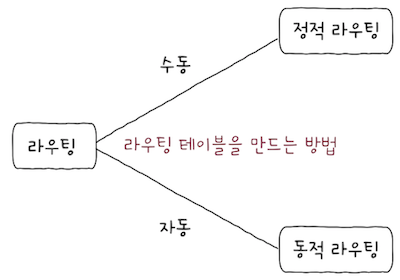
라우팅 테이블은 어떻게 만들어질까? 크게 2가지 방법이 있다.
- 03-2에서 IP 주소를 할당하는 방법에는 크게
정적 할당과동적 할당이 있다고 배웠다. 정적 할당: IP 주소를 수동으로 직접 할당하는 방식동적 할당: DHCP를 이용해, IP 주소가 자동으로 할당되는 방식정적 라우팅과동적 라우팅도 이와 유사하다.
3.3.1 정적 라우팅
정적 라우팅(static routing)은 사용자가 수동으로 직접 채워 넣은 라우팅 테이블의 항목을 토대로 라우팅되는 방식이다.
- e.g. 다음과 같이 라우팅 테이블 항목을 다루는 명령어가 있다.
- 이처럼 수동으로 구성된 라우팅 테이블 항목을 통해 수행되는 라우팅을 정적 라우팅이라 표현한다.
- e.g. 다음 예시는 모두
10.0.0.0/24로 향하는 패킷을192.168.1.1게이트웨이로 라우팅하는 명령어다.
1# 윈도우 운영체제2$ route add 10.0.0.0 mask 255.255.255.0 192.168.1.134# 맥OS 운영체제5$ sudo route add -net 10.0.0.0/24 192.168.1.167# 리눅스 운영체제8$ sudo route add -net 10.0.0.0 netmask 255.255.255.0 gw 192.168.1.1910# 시스코 라우터11$ ip route 10.0.0.0 255.255.255.0 192.168.1.1
3.3.2 동적 라우팅
네트워크의 규모가 커지고, 관리해야 할 라우터가 늘어나면, 정적 라우팅만으로는 관리가 버겁다.
- 수동으로
라우팅 테이블항목을 입력해야 하는정적 라우팅의 특성상 입력 실수가 발생할 수도 있다. - 또한 설령 실수없이 입력했다 할지라도, 라우팅되는 경로상에 예상치 못한 문제가 생길 수 있다.
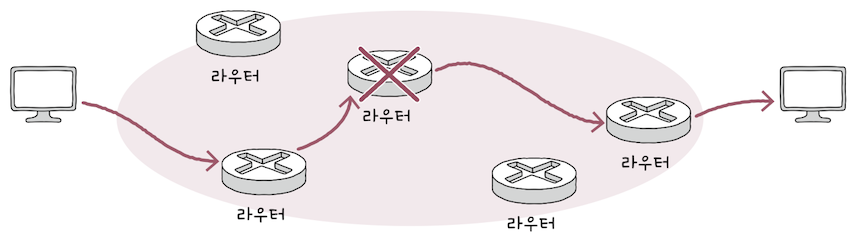
위 그림처럼 패킷이 붉은 선으로 표기된 경로로 정적 라우팅되도록 설정했다고 가정하면,
패킷이 라우팅되는 경로상에 문제가 발생한 데다, 또 다른 경로로 우회하여 전송할 수 있음에도 불구하고,라우터는 문제가 발생한 경로로패킷을 전송할 수 밖에 없다.
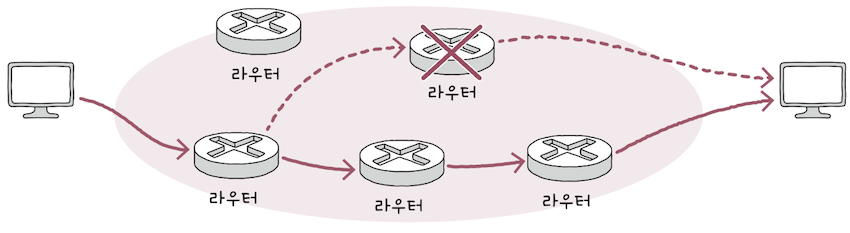
이떄 사용할 수 있는 방식이 동적 라우팅(dynamic routing)이다.
동적 라우팅은 자동으로라우팅 테이블항목을 만들고, 이를 이용하는 라우팅하는 방식을 의미한다.- 이러한 이유로
동적 라우팅을 하면,라우팅 테이블항목이 수시로 변할 수 있다. - 라우팅 테이블의 항목을 수동으로 입력할 필요가 없다면, 대규모 네트워크를 관리하는데 편리합니다.
- 그뿐만 아니라 네트워크 경로상에 문제가 발생했을 떄, 이를 우회할 수 있는 경로가 자동 갱신됩니다.
그렇다면 동적 라우팅은 어떻게 자동으로 라우팅 테이블 항목을 만들까?
모든 라우터는 특정 수신지까지 도달하기 위한 최적의 경로를 찾아,라우팅 테이블에 추가하려고 노력한다.- 이를 위해
라우터끼리 서로 자신의 정보를 교환하게 되는데,- 이 과정에서 사용되는 프로토콜이
(동적) 라우팅 프로토콜이다.
- 이 과정에서 사용되는 프로토콜이
- cf.
동적 라우팅은라우팅 프로토콜을 통해 자동으로 채워진라우팅 테이블항목을 토대로 라우팅되는 방식이다.
💡라우터들의 집단 네트워크, AS
본격적으로 라우팅 프로토콜을 학습하기 전에 알아야할 배경지식이 있다.
- 바로 동일한 라우팅 정책으로 운용되는 라우터들의 집단 네트워크인
AS(Autonomous System)이다.
- cf. Autonomous System : 자율 시스템, (어-토-너-미스)
- 한 회사나 단체에서 관리하는 라우터 집단을 AS라고 생각하면 된다.
- AS마다 인터넷 상에서 고유한
AS 번호(ASN; Autonomous System Number)가 할당된다.AS번호는사설 IP주소처럼사설 AS 번호도 있지만,
- 일반적으로 AS 번호를 칭할 떄는 고유한 번호를 일컫는 경우가 많다.
- 다음은 현재 한국에서 할당된 AS 번호의 일부이다.
- cf. 한국인터넷정보센터, AS 번호 사용자 현황
한 AS 내에는 다수의 라우터가 있다. 라우터들은 AS 내부에서만 통신할 수도 있고, AS 외부와 통신할 수도 있다.
- AS 외부와 통신할 경우, AS 경계에서 AS 내외로 통신을 주고받는
AS 경계 라우터(ASBR; Autonomous System Boundary Router)라는 특별한 라우터를 사용한다.
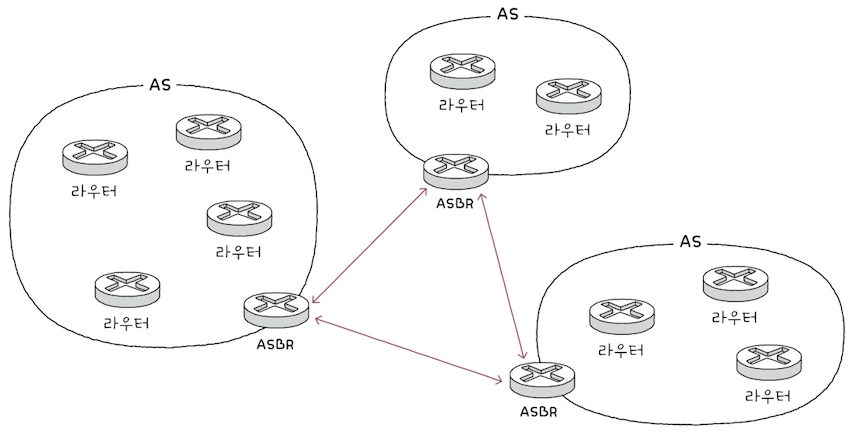
3.4 라우팅 프로토콜
라우팅 프로토콜(routing protocol)은 라우터들끼리 자신들의 정보를 교환해, 패킷이 이동할 최적의 경로를 찾기 위한 프로토콜이다.
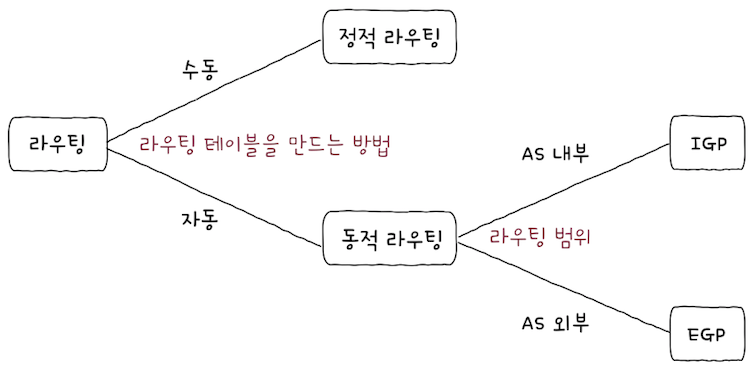
라우팅 프로토콜은 크게 AS 내부에서 수행되냐, AS 외부에서 수행되냐에 따라 종류가 나뉜다.
IGP(Interior Gateway Protocol): AS 내부에서 수행되는 프로토콜EGP(Exterior Gateway Protocol): AS 외부에서 수행되는 프로토콜
3.4.1 IGP: RIP와 OSPF
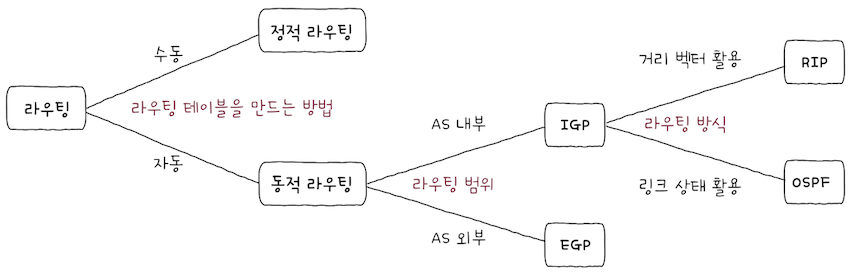
대표적인 IGP는 RIP, OSPF가 있다.
RIP(Routing Information Protocol): 최적의 경로를 선정하는 과정에서 거리 벡터를 사용- cf. 거리 벡터 : 영문그대로
distance vector(디스턴스 벡터)라고 부르기도 함
- cf. 거리 벡터 : 영문그대로
OSPF(Open Shortest Path First): 최적의 경로를 선정하는 과정에서 링크 상태를 사용- cf. 링크 상태 : 영문그대로
link state(링크 스테이트)라고 부르기도 함
- cf. 링크 상태 : 영문그대로
(1) RIP
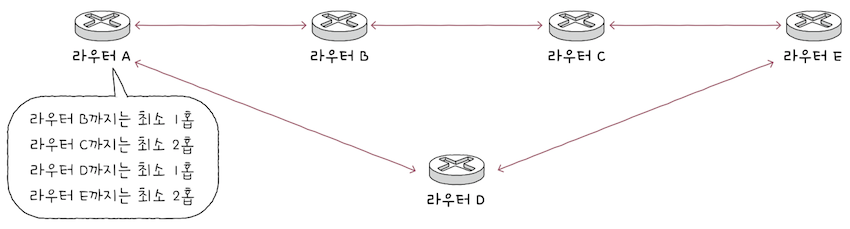
RIP은 거리 벡터 기반의 라우팅 프로토콜이다.거리벡터(distance vector): 이름 그대로 거리를 기반으로 최적의 경로를 찾는 라우팅 프로토콜을 의미한다.거리는 패킷이 경유한 라우터의 수, 즉홉의 수를 의미한다.
RIP은 인접한 라우터끼리 경로 정보를 주기적으로 교환하며,라우팅 테이블을 갱신한다.- 이를 통해
라우터는 특정 수신지에 도달하기까지의홉의 수를 알 수 있다. - 그리고 특정 수신지까지 도달하기 위해
홉 수가 가장 적은 경로를 최적의 경로라고 판단한다. - 그렇기에
홉 수가 적을 수록라우팅 테이블 상의 메트릭 값도 작아진다.
- 이를 통해
(2) OSPF
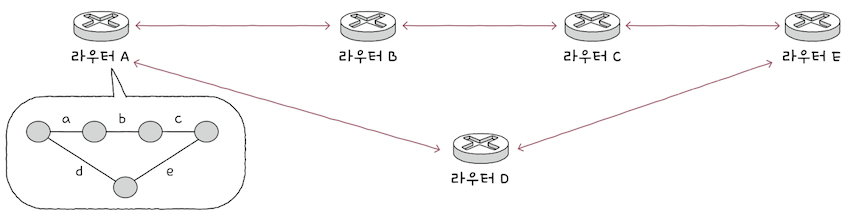
OSPF는 링크 상태 프로토콜이다.- 1장에서 ‘네트워크는 그래프의 형태를 띠며, 노드와 간선(링크)로 이루어져 있다’고 배웠다.
OSPF는 이런 링크 정보를 비롯한 현재 네트워크의 상태를 그래프의 형태로링크 상태 데이터베이스(LSDB; Link State DataBase)에 저장한다.링크 상태 데이터베이스는 라우터들의 연결 관계, 연결 비용 등 현재 네트워크의 상태를 그래프로 표현하기 위한 데이터가 저장되어 있다.라우터는링크 상태 데이터베이스를 기반으로 현재 네트워크 구성을 마치 지도처럼 그린 뒤에 최적의 경로를 선택한다.
OSPF는 최적의 경로를 결정하기 위해 대역폭을 기반으로 메트릭을 계산한다.- 대역폭이 높은 링크일수록,
메트릭이 낮은 경로로 인식한다. - 또한
라우터간에 경로 정보를 주기적으로 교환하며,라우팅 테이블을 갱신하는RIP과 달리, OSPF는 네트워크의 구성이 변경되었을 떄,라우팅 테이블이 갱신된다.
- 대역폭이 높은 링크일수록,
- 그런데 네트워크 구성이 변경될 떄마다
라우팅 테이블이 갱신된다면,- 네트워크의 규모가 매우 커졌을 떄는
링크 상태 데이터베이스에 모든 정보를 저장하기 어렵다. - 최적의 경로를 갱신하는 연산 부담도 커질 수 있다.
- 네트워크의 규모가 매우 커졌을 떄는
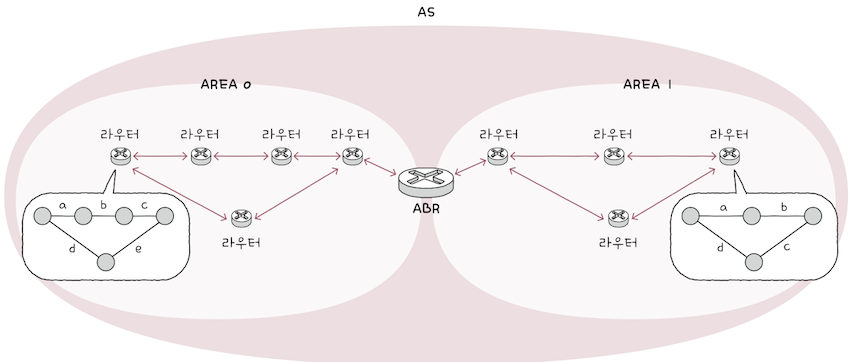
이에 OSPF에서는 AS를 에어리어(area)라는 단위로 나누고, 구분된 에어리어 내에서만 링크 상태를 공유한다.
에어리어는 위 그림처럼 번호가 부여되어 있으며,에어리어경계에 있는ABR(Area Border Router)라는 라우터가 에어리어 간의 연결을 담당한다.
💡 여담으로
고급 거리 벡터 프로토콜과링크 상태 프로토콜의 성격을 모두 띠는 라우팅 프로토콜이 있다.
- 이런 라우팅 프로토콜을
고급 거리 라우팅 프로토콜혹은하이브리드 라우팅 프로토콜이라고도 부른다.- 대표적은
EIGRP(Enhanced Interior Gateway Routing Protocol)이 있다.
3.4.2 EGP: BGP
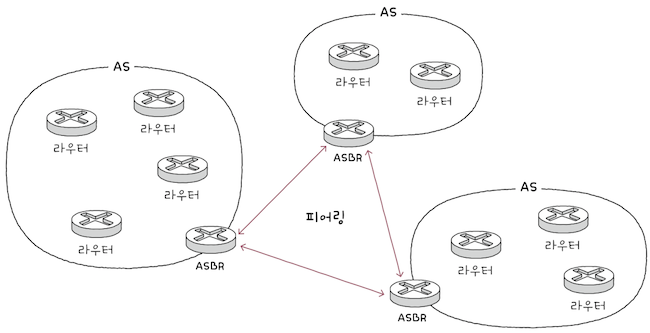
대표적인 EGP는 BGP(Border Gateway Protocol)가 있다.
- AS 간의 통신에서 사용되는 대표적인 프로토콜로, 엄밀하게는 AS 간의 통신이 ‘가능한’ 프로토콜이다.
- 따라서
BGP로 AS 내 라우터 간 통신도 가능하다.- AS 간의 통신을 위한 BGP는
eBGP(external BGP), - AS 내의 통신을 위한 BGP는
iBGP(Internal BGP)라고 한다.
- AS 간의 통신을 위한 BGP는
- AS 간에 정보를 주고받기 위해서는
AS 내에서 eBGP를 사용하는 라우터(이하 BGP 라우터)가 하나 이상 있어야 하고,또 다른 AS의 BGP 라우터와 연결되어야 한다.- 이 연결은
BGP 라우터간에BGP 메시지를 주고받음으로써 이루어지는데, BGP 메시지를 주고받을 수 있도록 연결된BGP 라우터를피어(peer)라고 정의한다.
- 즉,
다른 AS와의 BGP연결을 유지하기 위해서는BGP 라우터끼리 연결되어피어가 되어야 한다.- 이렇게 피어 관계가 되도록 연결하는 과정을
피어링(peering)이라 한다.
- 이렇게 피어 관계가 되도록 연결하는 과정을
- cf. 동일한 AS 내의 피어를
내부 피어, 다른 AS 내의 피어를외부 피어라고 한다. BGP는RIP와OSPF에 비해 최적의 경로를 결정하는 과정이 복잡하고, 일정하지 않은 경우가 많다.- 경로 결정 과정에서 수신지 주소와 더불어 다양한 ‘속성’과 ‘정책’이 고려되기 때문이다.
BGP의 속성(attribute)이란 경로에 대한 일종의 부가 정보다.- 종류는 다양하지만, 대표적인 속성으로는
AS-PATH와NEXT-HOP그리고LOCAL-PREF가 있다. - 다음 내용은 외우기보다 가볍게 개념을 훑어본다는 마음으로 보자.
- 종류는 다양하지만, 대표적인 속성으로는
(1) AS-PATH 속성
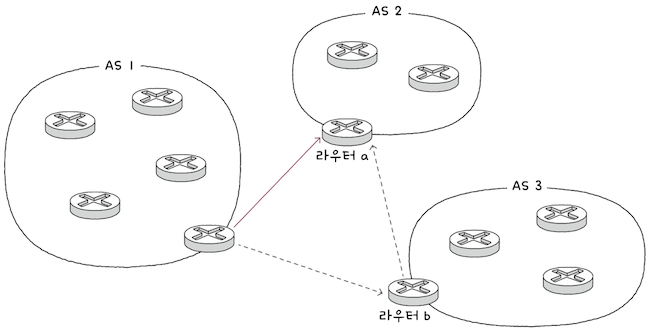
AS-PATH 속성은 메시지가 수신지에 이르는 과정에서 통과하는 AS들의 목록을 의미한다.
- 메시지가 AS를 거칠 떄마다, AS-PATH에는 거쳐 간 AS가 추가된다.
- e.g.
AS1에서AS2내의 특정 네트워크에 도달하는 경로는 크게 2개의 경로가 있다.AS1에서 곧장AS2로 가는 경로AS1에서AS3를 거쳐AS2에 도달하는 경로
- (1)번의 경우 AS-PATH는
AS2, (2)번의 경우 AS-PATH는AS3, AS2가 된다.
이 속성을 통해 엿볼 수 있는 BGP(eBGP)의 특징이 크게 2가지가 있다.
(1-1) BGP는 AS 간 라우팅을 할 떄, 거치데 될 ‘라우터’의 수가 아닌 ‘AS’의 수를 고려한다.
그렇기에 AS-PATH 길이가 더 짧은 경로라 할지라도 거치게 될 라우터의 홉 수가 더 많을 수 있다.
(1-2) BGP는 RIP처럼 단순히 수신지에 이르는 ‘거리’가 아닌, 메시지가 어디를 거쳐 어디로 이동하는지를 나타내는 ‘경로’를 고려한다.
이런 점에서 BGP는 경로 벡터(path vector) 라우팅 프로토콜의 일종이라 부르기도 한다.
💡 BGP는 거리가 아닌 경로를 고려하는 이유는
- 메시지가 같은 경로를 무한히 반복하여 이동하는 순환(loop)을 방지하기 위함이다.
BGP 라우터는 자신의 AS가AS-PATH에 포함되어 있을 경우, 순환으로 간주해 해당 메시지를 버린다.
(2) NEXT-HOP 속성
NEXT-HOP 속성은 이름 그대로 다음 홉, 다음으로 거칠 라우터의 IP 주소를 나타낸다.
- 앞의 예시에서 AS1에서 곧장 AS2로 가능 경로의
NEXT-HOP은 AS1과 연결된 라우터 a의 IP주소이며, - AS1에서 AS3를 거쳐 AS2에 도달하는 경로의
NEXT-HOP은 AS1과 연결된 라우터 b의 IP주소이다.
(3) LOCAL-PREF 속성
LOCAL-PREF는 지역 선호도, LOCAL PREFerence의 약자다.
이는 AS 외부 경로에 있어 AS 내부에서(local) 어떤 경로를 선호할지(preference)에 대한 척도를 나타내는 속성이다.
- 경로를 선택하는 과정에서
LOCAL-PREF값은 일반적으로AS-PATH나NEXT-HOP속성보다 우선시되며,LOCAL-PREF값이 클수록 우선으로 선택된다.
LOCAL-PREF값은 AS 관리 주체가 설정하는 정책의 영향을 받는다.- 기본으로 설정되는
LOCAL-PREF값이 있기는 하지만,LOCAL-PREF값을 설정하여AS 내의 라우터끼리 특정 경로에 대한 선호도를 합의한다는 것은- ‘정책적인 이유로 이 경로를 우선시하겠다’,
- ‘설령 이 경로가 다른 경로에 비해, 비교적 비효율적일지라도 이 경로를 우선시하겠다’라는 말과도 같다.
💡 BGP의 정책
BGP의 정책(policy)은AS 간 라우팅에 있어 경로를 선택하는 중요한 판단 기준 중 하나이다.
AS 관리 주체에 따라 각기 다른 상업적-정치적 목적으로 상이한 정책을 사용할 수 있기에,
- 최적의 경로를 선택하는 기준은 AS마다 다를 수 있다.
- e.g. 특정 AS에서 오는 메시지만 처리하도록 특정 AS를 우대하는 정책을 설정하거나,
- 반대로 특정 AS에서 오는 메시지는 차단할 수도 있다.
- 보안과 안전성을 우선시하는 정책은 속도는 느릴지라도,
- 더 안전하고 안정적인 AS를 경로로 선택하도록 할 수 있고,
- 성능을 우선시하는 정책은 송수신 지연 시간이 적고, 대역폭이 높은 AS를 경로로 선택하도록 할 수 있다.
- 이처럼
BGP는 다양한 속성과 정책을 기반으로AS 간의 라우팅을 수행할 수 있다.