1. 배열(순차 리스트)
- 연관된 데이터를 연속적인 형태로 구성된 구조를 가진다.
- 배열에 포함된 원소는 순서대로 번호(index)가 붙는다.
- e.g. 학교 출석부
1.1 배열의 특징
- 고정된 크기를 가지며 일반적으론 동적으로 크기를 늘릴 수 없다.
- JS처럼 대부분의 스크립트 언어는 동적으로 크기가 증감되도록 만들어져 있다.
- 원하는 원소의 index를 알고 있다면 로 원소를 찾을 수 있다
- 원소를 삭제하면 해당 index에 빈자리가 생긴다.
1.2 배열 선언
1.2.1 배열 생성
1// 📝 빈 Arrays 생성2let arr1 = []3console.log(arr1)45// 📝 미리 초기화된 Array를 생성6let arr2 = [1, 2, 3, 4, 5]7console.log(arr2)89// 📝 많은 값을 같은 값으로 초기화할 경우 fill을 사용10let arr3 = Array(10).fill(0)11console.log(arr3)1213// 📝 특정 로직을 사용하여 초기화할 경우 from을 사용14let arr4 = Array.from({ length: 100 }, (_, i) => i)15console.log(arr4)
1.2.2 배열 요소 추가, 삭제
1const arr = [1, 2, 3]2console.log(arr)34// 📝 4 가 끝에 추가 -> O(1)5arr.push(4) // O(1)67// 📝 여러 개를 한 번에 추가 -> O(1)8arr.push(5, 6) // -> O(1)9console.log(arr)1011// 📝 3번 인덱스에 128을 추가 -> O(n)12arr.splice(3, 0, 128) // -> O(n)13console.log(arr)1415// 📝 3번 인덱스 값을 제거16arr.splice(3, 1) // O(n)17console.log(arr[3])
1.3 2차원 배열
2차원 배열은 1차원 배열을 확장한 것이다.
1// 2차원 배열을 리터럴로 표현2const arr = [3[1, 2, 3, 4],4[5, 6, 7, 8],5[9, 10, 11, 12],6]78// arr[2][3]에 저장된 값을 출력9console.log(arr[2][3]) // 121011// arr[2][3]에 저장된 값을 15로 변경12arr[2][3] = 151314// 변경된 값을 출력15console.log(arr[2][3]) // 15
다음과 같이 선언할 수도 잇다.
1// 크기가 3 * 4인 2차원 배열을 생성2const arr = [...new Array(3)].map((_, i) => new Array(4).fill(i))34console.log(arr) // [ [ 0, 0, 0, 0 ], [ 1, 1, 1, 1 ], [ 2, 2, 2, 2 ] ]
2. 배열의 효율성
배열은 임의 접근이라는 방법으로 배열의 모든 위치에 있는 데이터에 단 한번에 접근할 수 있다.
- 따라서 데이터 접근하기 위한 시간 복잡도는 이다.
- 배열에 데이터를 추가하는 것도 어디에 저장하느냐에 따라 추가 연산에 대한 시간 복잡도가 달리진다.
- cf. 삭제 연산도 추가와 마찬가지의 시간복잡도를 가진다.
2.1 배열 연산의 시간 복잡도
2.1.1 맨 뒤에 삽입할 경우
1;[1, 3, 5]2// 맨 뒤에 2를 추가
- 맨 뒤에 삽입할 때는 arr[3]에 임의 접근을 바로 할 수 있으며, 데이터를 삽입해도 다른 데이터 위치에 영향을 주진 않는다.
- 따라서 시간 복잡도는 이다.
2.1.2 맨 앞에 삽입할 경우
1;[1, 3, 5]2// 맨 앞에 2를 추가
맨 앞에 삽입한다면, 기존 데이터들을 뒤로 한 칸씩 밀어야 한다.
- 즉, 미는 연산이 필요하다.
- 데이터 개수를 N개로 일반화화면 시간 복잡도는 이다.
2.1.3 중간에 삽입할 경우
1;[1, 3, 5, 7]2// 3과 5의 중간에 2를 추가, 삽입 위치에 따라 최악의 경우 N번
5앞에 데이터를 삽입한다면, 5 이후의 데이터를 뒤로 한 칸식 밀어야 한다.
- 다시 말해, 현재 삽입한 데이터 뒤에 있는 데이터 개수만큼 미는 연산을 해야 한다.
- 밀어야 하는 데이터 개수가 N개라면, 시간 복잡도는 이다.
2.2 배열을 선택할 떄 고려할 점
데이터에 자주 접근하거나 읽어야 하는 경우, 배열을 사용하면 좋은 성능을 낼 수 있다. e.g. 그래프를 표현할 떄, 배열을 활용하면 임의 접근을 할 수 있으므로, 간선 여부도 시간복잡도 O(1)로 판단 가능하다. 하지만 배열은 메모리 공간을 충분히 확보해야 하는 단점도 있다.
따라서 코딩 테스트는 다음 사항을 고려해 배열을 선택해야 한다.
- 할당할 수 있는 메모리 크기를 확인해야 한다.
- 배열로 표현하려는 데이터가 너무 많으면, 런타임에서 배열 할당에 실패할 수 있다.
- 운영체제마다 배열을 할당할 수 있는 메모리의 한계치는 다르지만,
- 보통은 1차원 배열은 1000만개, 2차원 배열은 3000 * 3000 크기를 최대로 생각한다.
- 중간에 데이터 삽입이 많은지 확인해야 한다.
- 배열은 선형 자료구조이기 떄문에 중간이나 처음에 데이터를 빈번하게 삽입하면,
- 시간 복잡도가 높아져 실제 시험에서 시간 초과가 발생할 수 있다.
💡 JS의 배열은 크기가 변할 수 있으므로 배열을 리스트처럼 사용할 수 있다. 여기서 배열을 사용할 때는 크기를 고정하여 사용하면 배열로, 가변 크기로 사용할 떄는 리스트라고 부르겠다.
3. 자주 활용되는 배열 기법
3.1 배열에 데이터 추가
3.1.1 push() : 맨 끝에 데이터 추가
1// 배열 맨 끝에 데이터 추가2const arr = [1, 2, 3];3arr.push(4)l // [1, 2, 3, 4];
3.1.2 concat() : 배열에 든 데이터 추가
1let arr = [1, 2, 3]2arr = arr.concat([4, 5]) // [1, 2, 3, 4, 5]
- concatenation의 줄임말로 “연결”을 의미
3.1.3 스프레드 연산자로 데이터 추가
1let arr = [1, 2, 3]2arr = [...arr, ...[4, 5]] // [1, 2, 3, 4, 5]
3.1.4 unshift() : 맨 앞에 데이터 추가
1const arr = [1, 2, 3]2arr.unshift(0) // [0, 1, 2, 3];
- 맨 앞에 데이터를 추가하는 시간 복잡도는 이지만,
- 배열내 데이터가 적으면 JS 엔진이 최적화를 하여 이보다 더 적은 시간 복잡도로 처리한다.
- cf. 실험에 따르면, 대략 15,000개까지는 최적화가 되지만 이후로 급격하게 느려진다.
3.1.5 splice() : 중간에 데이터 추가
1arrat.splice(start[, deleteCount[, item1[, item2[, ...]]]])
- 첫 번쨰 매개변수 start는 배열 내 시작 지점을 의미
- 두 번쟤 매개변수 deleteCount는 삭제할 데이터의 수를 의미하고, 그 이후로는 추가할 데이터를 받는다.
- 이를 이용하여 두 번쨰 매개변수를 0으로 설정하면 다음과 같이 중간에 데이터를 추가할 수 있다.
- cf. 대괄호 감싸지 않은 첫 번쨰 매개변수는 꼭 필요한 값이고, 대괄호 감싼 매개변수는 선택(optional) 매개변수다.
- 공식 문서에서 메서드를 설명할 떄, 자주 사용하는 표현법이다.
1const arr = [1, 2, 3, 4, 5]2arr.splice(2, 0, 9999) // [1, 2, 9999, 3, 4, 5];3// 2번 인덱스에, 0개의 데이터를 삭제하고, 9999를 추가
3.2 배열에서 데이터 삭제
3.2.1 pop() : 마지막 데이터 삭제
1const arr = [1, 2, 3, 4, 5]2const poppedElement = arr.pop() // 53console.log(arr) // [1, 2, 3, 4]
3.2.2 shift() : 맨 앞 데이터 삭제
1const arr = [1, 2, 3, 4, 5]2const shiftedElement = arr.shift() // 13console.log(arr) // [2, 3, 4, 5]
- cf. 배열 특성상 맨 앞 데이터를 삭제하면, 시간 복잡도가 O(n)이 되지만,
- unshift() 메서드와 마찬가지로 배열 내 데이터가 적으면 JS 엔진이 최적화를 해준다.
- cf. 성능 차이를 직접 보고 싶다면 http://www.lonniebest.com/BadShiftPerformance/에 접속해 확인 가능하다.
3.2.3 splice() : 중간 데이터 삭제
1const arr = [1, 2, 3, 4, 5]2const removedElements = arr.splice(2, 2) // [3, 4]3console.log(arr) // [1, 2, 5]
- 첫 번째 매개변수로 시작 지점을 정하고, 두 번쨰 매개변수로 삭제할 데이터 수를 정한다.
- 데이터를 삭제할 떄는 세 번쨰 이후 매개변수는 생략한다.
3.3 고차 함수를 이용해 데이터에 특정 연산 적용
JS는 배열에 map(), filter(), reduce()와 같은 유용한 고차 함수를 기본으로 제공한다.
- 이를 이용하여 기존 배열에 기반하여 새로운 배열을 만드는 것이 가능하다.
- 고차 함수를 이용하면 기존 반복문, 조건문을 이용한 복잡한 로직을 대체할 수 있다.
3.3.1 map : 배열에 제곱 연산
1const numbers = [1, 2, 3, 4, 5]2const squares = numbers.map((num) => num * num) // [1, 4, 9, 16, 25]3console.log(numbers) // [1, 2, 3, 4, 5]
- 주목할 점은 numbers 배열의 값 변화 유무이다.
- numbers 값 자체는 그대로이다. map()를 적용했더라도 원래 값은 바뀌지 않는다.
- 이처럼 배열의 고차함수는 연산을 마친 배열을 반환할 뿐, 연산 대상을 직접 바꾸지 않는다.
3.3.2 filter : 짝수 필터링
1const numbers = [1, 2, 3, 4, 5]2const evens = numbers.filter((num) => num % 2 === 0) // [2, 4]
- filter()는 반환값이 참이면 남기고, 거짓이라면 거른다.
- 현재 조건은 num % 2 === 0이므로 작수만 남긴 배열을 반환한다.
- cf. map()처럼 filter()도 기존 배열을 바꾸는 것이 아닌 새 배열을 반환한다.
3.3.3 reduce : 전체 합
1const numbers = [1, 2, 3, 4, 5]2const sum = numbers.reduce((a, b) => a + b) // 15
reduce()는 map(), filter()와 조금 다르다.
map(), filter()의 익명함수는 사용해야 하는 인수가 1개였지만,reduce()는 익명 함수가 받아야 하는 인수가 2개다.
- 첫 번쨰 인자는 이전까지 함쳐진 상태를 의미하고,
- 두 번쨰 인자는 현재 순회하며 바라보고 있는 데이터를 의미한다.
순회 과정은 다음과 같다.
- a = 0, b = 1 (합쳐진 상태는 없으므로 0, 현재 순회하며 바라보는 데이터 1)
- a = 1, b = 2 (합쳐진 상태 1, 현재 순회하며 바라보는 데이터 2)
- a = 3, b = 3 (합쳐진 상태 3, 현재 순회하며 바라보는 데이터 3)
- a = 6, b = 4 (합쳐진 상태 6, 현재 순회하며 바라보는 데이터 4)
- a = 10, b = 5 (합쳐진 상태 10, 현재 순회하며 바라보는 데이터 5)
- a = 15 (종료)
4. 몸풀기 문제
4.1 배열 정렬하기
정수 배열을 정렬해서 반환하는 solution() 함수를 완성하세요.
✅ 제약 조건
- 정수 배열의 길이는 2 이상 이하이다.
- 정수 배열의 각 데이터 값은 -100,000 이상 100,000 이하이다.
✅ 입출력의 예
| 입력 | 출력 |
|---|---|
| [1, -5, 2, 4, 3] | [-5, 1, 2, 3, 4] |
| [2, 1, 1, 3, 2, 5, 4] | [1, 1, 2, 2, 3, 4, 5] |
| [6, 1, 7] | [1, 6, 7] |
✅ 분석
제약조건을 주의 깊게 보면, 데이터 개수는 최대 이다.
- 즉, 제한 시간이 3초라면 알고리즘은 사용할 수 없다.
- 만약 정수 배열의 최대 길이가 10이라면, 알고리즘을 사용해도 된다.
- 이 문제를 제시한 이유는 제약 조건에 따른 알고리즘의 선택을 보여주기 위함이다.
- 이렇게 제약 조건에 따라 같은 문제도 난이도가 달라질 수 있다.
- 단순히 정렬 알고리즘으로 정렬하면 이 문제는 통과할 수 없다.
1function solution(arr) {2arr.sort((a, b) => a - b)3return arr4}
sort()는 배열을 정해진 규칙에 맞춰 정렬한다. 이떄 정해진 규칙이란 sort()에 인수로 전달한 익명함수다.
- 이 익명 함수를 이해하기 전에 sort()의 기본 동작부터 알아야 한다.
JS의 sort()는 아무 조건을 전달하지 않고 실행하면 데이터가 문자열이라고 가정하고 정렬한다.
1;[1, 10, 5, 3, 100].sort() // [1, 10, 100, 3, 5]2;[-1, 10, -5, 3].sort() // [-1, -5, 10, 3]
sort()를 보면, 100 다음에 3이 나온다.
- 이상한 결과가 나온 이유는 숫자가 아닌 문자열로 바라보고 오름차순 정렬했기 떄문이다.
- 100과 3을 문자열로 비교하면, 문자 1과 3 중 3이 더 크므로 100을 3 앞에 둔다.
- 숫자에 대해 정렬을 하려면
sort()에 익명 함수로 조건을 전달해야 한다.
1function solution(arr) {2arr.sort((a, b) => a - b)3return arr4}56console.log(solution([1, -5, 2, 4, 3])) // [-5, 1, 2, 3, 4]7console.log(solution([2, 1, 1, 3, 2, 5, 4])) // [1, 1, 2, 2, 3, 4, 5]8console.log(solution([1, 6, 7])) // [1, 6, 7]
코드를 보면 익명 함수가 인수로 a, b를 받아 a에서 b를 뺀 결과를 반환하고 있다.
이렇게 하면 sort()가 오름차순 배열을 반환할 수 있다.
하나씩 단계별로 살펴보면, 정렬은 첫번쟤 인수인 a를 기준으로 다음 규칙으로 진행한다.
- 첫 번쨰 인자 a가 두 번쨰 인자 b보다 앞에 나와야 한다면 음수를 반환한다.
- 첫 번쨰 인자 a가 두 번쨰 인자 b보다 뒤에 나와야 한다면 양수를 반환한다.
- 위치 변경을 하지 않는다면 0을 반환한다.
위와 같은 규칙을 기억하고 오름차순 정렬을 어떻게 만들지 생각해보자.
- 먼저 기준은 첫 번쨰 인수라는 점을 이용할 수 있다.
- 따라서 첫 번쨰 인자를 a, 두 번째 인자를 b라고 부를 때, a에서 b를 빼는 식을 사용한다면,
- a가 b보다 큰 경우 자연스럽게 양수가 반환되고, 작은 경우엔 음수가 반환된다.
- 만약 반대로 내림차순으로 정렬한다면 두 번쨰 인자에서 첫 번쨰 인자를 빼도록 만들면 된다.
cf. sort() 메서드를 사용하면 기존 배열이 변경된다.
- 원본 배열을 그대로 두고 싶다면
toSorted()를 사용할 수도 있지만, - 비교적 최근에 추가된 기능이므로
sort()사용을 추천한다.
toSorted()는 ECMAScript 2023에 추가된 기능이다. 2023년 6월 경 릴리스됐다.
💡 sort()를 사용하지 않고 정렬 알고리즘을 사용하면?
sort()를 사용하지 않고 정렬 알고리즘으로 배열 원소를 정렬하면 연산 시간 차이를 얼마나 날까?
1// 버블 정렬을 활용한 방법2function bubbleSort(arr) {3const n = arr.length4for (let i = 0; i < n; i++) {5for (let j = 0; j < n - i - 1; j++) {6if (arr[j + 1] > arr[j]) {7const tmp = arr[j + 1]8arr[j + 1] = arr[j]9arr[j] = tmp10}11}12}13return arr14}1516// sort() 함수를 활용한 방법17function doSort(arr) {18arr.sort((a, b) => a - b)19return arr20}2122function measureTime(callback, arr) {23const start = Date.now()24const result = callback(arr)25const end = Date.now()26return [end - start, result]27}2829let arr = Array.from({ length: 10000 }, (_, k) => 10000 - k)3031// 첫 번쨰 코드 시간 측정32// 첫 번쨰 코드 실행 시간 : 2081ms33const [bubbleTime, bubbleResult] = measureTime(bubbleSort, arr)34console.log(`첫 번쨰 코드 실행 시간 : ${bubbleTime}ms`)3536// 두 번째 코드 시간 측정37// 두 번쨰 코드 실행 시간 : 1ms38arr = Array.from({ length: 10000 }, (_, k) => 10000 - k)39const [doSortTime, doSortResult] = measureTime(doSort, arr)40console.log(`두 번쨰 코드 실행 시간 : ${doSortTime}ms`)첫 번쨰 방법은 정렬 알고리즘인 버블 정렬을 활용한 방법이고, 두 번쨰 방법은 시간 복잡도의 sort() 함수를 활용한 방법이다.
- 결과를 보면 시간 차가 상당하다.
- 데이터 10,000개를 역순으로 정렬하는데 버블 정렬은 2초가 걸리지만,
- sort()를 활용한 두 번쨰 방법은 1밀리초 밖에 걸리지 않는다.
- 실행 환경마다 시간의 차이는 조금 생길 수 있지만, 압도적으로 sort() 함수가 성능이 좋다는 것을 알 수 있다.
- 이것으로 알고리즘의 시간 복잡도가 얼마나 중요한지 알아두기 바란다.
✅ 시간 복잡도 분석
N은 arr의 길이이므로 시간 복잡도는 이다.
4.2 배열 제어하기
정수 배열을 하나 받는다. 배열의 중복값을 제거하고 배열 데이터를 내림차순으로 정렬해서 반환하는 solution()를 구현하세요.
✅ 제약 조건
- 배열의 길이는 2 이상 1,000 이하이다.
- 각 배열의 각 데이터 값은 -100,000 이상 100,000 이하이다.
✅ 입출력의 예
| 입력 | 출력 |
|---|---|
| [4, 2, 2, 1, 3, 4] | [4, 3, 2, 1] |
| [2, 1, 1, 3, 2, 5, 4] | [5, 4, 3, 2, 1] |
✅ 분석
직접 코드로 구현하고 싶은 마음이 들 수도 있지만, JS에는 직접 구현하지 않고도 문제를 해결할 방법은 많다. 이 문제가 딱 이런 유형입니다.
1function solution(arr) {2const uniqueArr = [...new Set(arr)] // (1) 중복값 제거3uniqueArr.sort((a, b) => b - a) // (2) 내림차순 정렬4return uniqueArr5}67// console.log(solution([4, 2, 2, 1, 3, 4])); // 반환값 : [4, 3, 2, 1]8// console.log(solution([2, 1, 1, 3, 2, 5, 4])); // 반환값 : [5, 4, 3, 2, 1]
(1)에서 Set 객체를 사용해 배열의 중복값을 제거했다. Set은 집합을 생성하는 JS 내장 객체다.
- 집합은 중복값을 허용하지 않으므로 문제에서 요구하는 문제를 한 번에 해결할 수 있다.
- 그 후 스프레드 연산자를 통해 집합을 다시 배열로 반환해준다.
- 반복문을 통해 일일이 데이터를 확인해서 중복값을 확인해 제거하는 알고리즘은
- 시간 복잡도가 으로 성능이 안좋다.
- JS에는 코딩 테스트에 유용한 기능이 많다. 굳이 직접 작성하지 않는 법이 많다.
- 심지어
Set 객체는 해시 알고리즘으로 데이터를 저장하므로 시간 복잡도 을 보장한다. - cf. 해시 알고리즘 자체는 시간복잡도가 이지만,
- 배열의 원소 개수가 N인 경우 중복값을 제거하기 위해,
- 배열을 한번 순회하고 삽입해야 하므로 시간 복잡도는 이다.
(2)의 sort() 메서드 활용 부분에서 매개변수로 전달한 익명 함수를 확인해보면 b - a로 넣은 것을 볼 수 있다.
- 앞서 설명한 sort() 메서드 규칙을 생각하면 내림차순으로 정렬된다.
✅ 시간 복잡도 분석
N은 arr의 길이이므로 arr의 중복 원소를 제거하는 데 걸리는 시간 복잡도는 이고, 이를 다시 정렬하는데 걸리는 시간 복잡도는 이므로 최종 시간 복잡도는 이다.
5. 모의 테스트
5.1 두 개 뽑아서 더하기⭐️
정수 배열 numbers가 주어진다. numbers에서 서로 다른 인덱스에 있는 2개의 수를 뽑아 더해 만들 수 있는 모든 수를 배열에 오름차순으로 담아 반환하는 solution()함수를 완성하세요.
✅ 제약 조건
- numbers의 길이는 2 이상 1,000 이하이다.
- numbers의 모든 수는 0 이상 100 이하다.
✅ 입출력의 예
| numbers | result |
|---|---|
| [2, 1, 3, 4, 1] | [2, 3, 4, 5, 6, 7] |
| [5, 0, 2, 7] | [2, 5, 7, 9, 12] |
✅ 분석
문제 자체에 요구사항이 그대로 드러나 있는 난이도가 낮은 문제다.
- 숫자 배열에서 서로 다른 두 수를 선택해서 더한 결과를 모두 구하고 오름차순으로 정렬해서 반환하면 된다.
- 하나 놓치기 쉬운 점은 중복값은 허용하지 않는다는 겁니다.
- 테스트 케이스를 입력값 [5, 0, 2, 7]에 대해 반환값이 2+5, 0+7으로 7이 둘이 아니라 하나다.
- 이런 입출력 값에 대해서는 일부러라도 분석하는 시간을 반드시 가져보길 바란다.
numbers의 최대 데이터 개수는 100이므로 시간 복잡도는 고려하지 않아도 된다. 그렇다면 이 문제는 다음과 같은 과정으로 풀 수 있다.
- 배열에서 두 수를 선택하는 모든 경우의 수를 구한다.
- 과정 1에서 구한 수를 새로운 배열에 저장하고 중복값을 제거한다.
- 배열을 오름차순으로 정렬하고 반환한다.
1;[5, 0, 2, 7][(5, 0, 2, 7)][(5, 0, 2, 7)] // {5, 0}, {5, 2}, {5, 7} // {0, 2}, {0, 7} // {2, 7}
배열에서 두 수를 선택하는 방법은 각 수에서 자신보다 뒤에 있는 수를 선택하면 된다. 빠짐없이 모든 두 수를 선택할 수 있다.
1// https://school.programmers.co.kr/learn/courses/30/lessons/686442function solution(numbers) {3const ret = [] // (1) 빈 배열 생성4// (2) 두 수를 선택하는 모든 경우의 수를 반복문으로 구함5for (let i = 0; i < numbers.length; i++) {6for (let j = 0; j < i; j++) {7// (3) 두 수를 더한 결과를 새로운 배열에 추가8ret.push(numbers[i] + numbers[j])9}10}11// (4) 중복된 값을 제거하고, 오름차순으로 정렬 후 반환12return [...new Set(ret)].sort((a, b) => a - b)13}1415// console.log(solution([2, 1, 3, 4, 1])); // 반환값 : [2, 3, 4, 5, 6, 7]16// console.log(solution([5, 0, 2, 7])); // 반환값 : [2, 5, 7, 9, 12]
(1) ret 배열은 값을 추가하기 위한 배열이다. 초기 상태이므로 아무 데이터도 없다.
(2) numbers의 데이터에서 두 수를 선택하는 동작을 구현한 코드다.
표를 보면 반복문의 의미를 쉽게 이해할 수 있다. i=0, j=2인 경우 {5, 2} => 7이라고 표시했다.
| i/j | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0 | 0 => 5 | 2 => 7 | 7 => 12 | |
| 1 | 2 => 2 | 7 => 7 | ||
| 2 | 7 => 9 | |||
| 3 |
(3) 표와 같이 구한 합은 push() 메서드로 ret 배열에 추가한다. 중복값을 제거하기 전이므로 지금은 [5, 7, 12, 2, 7, 9]이다.
(4) 이후 Set 객체로 중복값을 제거한 후 sort() 메서드를 통해 오름차순으로 정렬해 반호나하면 문제 풀이는 끝이다.
✅ 시간 복잡도 분석
N은 numbers의 길이로, 모든 조합을 확인하는 과정에서 중복을 체크하는데 이 걸린다.
- 그리고 이를 정렬하는 데 이 걸리므로 최종 시간 복잡도는 이다.
- 다만 N=100이므로 시간 복잡도를 이렇게 해도 문제를 푸는 데는 크게 영향이 없다.
5.2 모의고사⭐️
수포자 삼인방은 모의고사에 수학 문제를 전부 찍으려 한다. 수포자는 1번 문제부터 마지막 문제까지 다음과 같이 찍는다.
- 1번 수포자가 찍는 방식 : 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, …
- 2번 수포자가 찍는 방식 : 2, 1, 2, 3, 2, 4, 2, 5, 2, 1, 2, 3, 2, 4, 2, 5, …
- 3번 수포자가 찍는 방식 : 3, 3, 1, 1, 2, 2, 4, 4, 5, 5, 3, 3, 1, 1, 2, 2, 4, 4, 5, 5, …
1번 문제부터 마지막 문제까지의 정답이 순서대로 저장된 배열 answers가 주어졌을 떄, 가장 많은 문제를 맞힌 사람이 누구인지 배열에 담아 반환하도록 solution() 함수를 작성하세요.
✅ 제약 조건
- 시험은 최대 10,000 문제로 구성되어 있다.
- 문제의 정답은 1, 2, 3, 4, 5 중 하나이다.
- 가장 높은 점수를 받은 사람이 여럿이라면 반환하는 값을 오름차순으로 정렬하세요.
✅ 입출력의 예
| answers | return |
|---|---|
| [1, 2, 3, 4, 5] | [1] |
| [1, 3, 2, 4, 2] | [1, 2, 3] |
✅ 분석
가장 먼저 해야 할 일은 수포자들의 문제를 찍는 패턴을 분석하는 겁니다. 각 수포자가 문제를 찍는 패턴은 다음과 같다.
1// 수포자1 : 반복되는 패턴 - 1, 2, 3, 4, 52[1, 2, 3, 4, 5, 1, 2, 3, 4, 5, ...]34// 수포자2 : 반복되는 패턴 - 2, 1, 2, 3, 2, 4, 2, 55[2, 1, 2, 3, 2, 4, 2, 5, 2, 1, 2, 3, 2, 4, 2, 5, ...]67// 수포자3 : 반복되는 패턴 - 3, 3, 1, 1, 2, 2, 4, 4, 5, 58[3, 3, 1, 1, 2, 2, 4, 4, 5, 5, 3, 3, 1, 1, 2, 2, 4, 4, 5, 5, ...]
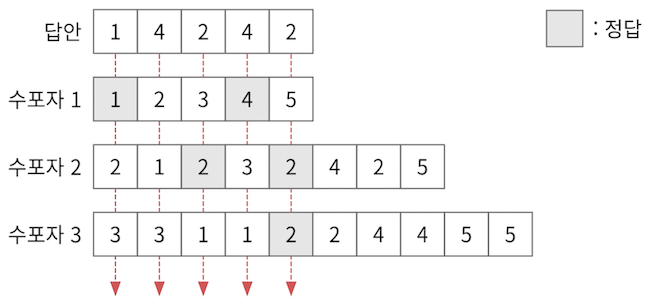
패턴을 찾았으므로 각 패턴으로 문제를 풀 경우 몇 개를 맞출 수 있는지 체크한다.
- 문제 번호에 대해 수포자의 답과 실제 답이 일치할 때마다 점수를 획득하는데, 이 점수가 가장 큰 수포자를 찾는다.
- e.g. 답이 [1, 4, 2, 4, 2]인 경우 수포자 1, 수포자 2는 2문제를 맞췄고, 수포자 3은 1문제를 맞춘다.
- 이 경우 최대 점수를 얻은 수포자는 수포자 1과 수포자 2이다.
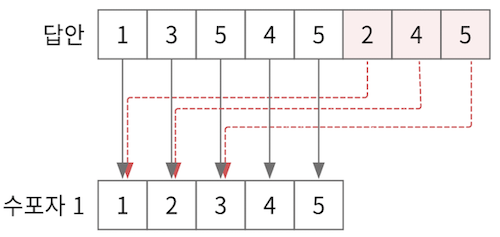
만약 답이 [1, 3, 5, 4, 5, 2, 4, 5]이면 답의 길이가 8이고,
- 수포자 1의 패턴 길이는 5이므로, 답의 길이가 수포자 1의 패턴 길이보다 길다.
- 그런 경우 위 그림과 같이 코드를 설계해야 한다.
- 그림을 보면 [1, 3, 5, 4, 5]까지는 기존 방식으로 답안을 매치하면 되고,
- 수포자 1과 같이 패턴 길이를 넘어서는 [2, 4, 5]는 수포자1의 답 패턴 첫 번쨰부터 매치하면 된다.
이렇게 하면 모든 수포자의 점수를 구할 수 있다.
- 가장 높은 점수를 획득한 수포자의 번호를 반환할 떄 주의할 점은 동점 조건이다.
- 수포자들이 얻은 점수의 최대값을 먼저 구하고,
- 이 점수와 일치하는 수포자의 번호를 오름차순으로 반환하면, 동점 조건을 해결할 수 있다.
1// https://school.programmers.co.kr/learn/courses/30/lessons/428402function solution(answers) {3// (1) 수포자들의 패턴4const patterns = [5[1, 2, 3, 4, 5], // 1번 수포자의 찍기 패턴6[2, 1, 2, 3, 2, 4, 2, 5], // 2번 수포자의 찍기 패턴7[3, 3, 1, 1, 2, 2, 4, 4, 5, 5], // 3번 수포자의 찍기 패턴8]910// (2) 수포자들의 점수를 저장할 배열11const scores = [0, 0, 0]1213// (3) 각 수포자의 패턴과 정답이 얼마나 일치하는지 확인14for (const [i, answer] of answers.entries()) {15for (const [j, pattern] of patterns.entries()) {16if (answer === pattern[i % pattern.length]) {17scores[j] += 118}19}20}2122// (4) 가장 높은 점수 저장23const maxScore = Math.max(...scores)2425// (5) 가장 높은 점수를 받은 수포자들의 번호를 찾아서 배열에 담음26const highestScores = []27for (let i = 0; i < scores.length; i++) {28if (scores[i] === maxScore) {29highestScores.push(i + 1)30}31}3233return highestScores34}
(1) 수포자들의 패턴을 미리 배열에 저장한다. 이렇게 특정 패턴이 있으면 배열에 미리 담아도 좋다.
(2) 수포자들의 패턴과 답안을 비교해서 일치하는 개수를 저장하는 배열을 선언한다. 이떄 [0] * 3과 같은 기법은 [0, 0, 0]을 선언하는 것보다 간단해 자주 사용한다.
(3) 정답과 수포자들의 패턴을 비교해서 각 수포자들의 점수를 구하는 부분이다.
반복문에서 of 연산자를 활용하는 형태가 생소할 수 있는데,
- 배열의
entries()는 배열 내 데이터를 인덱스와 값으로 묶어서 순회할 수 있는Iterator 객체를 반환한다. Iterator는next()를 이용하여 연속된 데이터를 순회할 수 있게 만드는 객체다.of 연산자를 이용하면 처음부터 끝까지 순회하는 것이 가능하다.
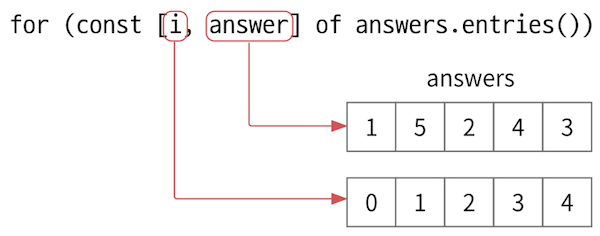
- 그림을 보면, 바깥쪽 반복문을 보면
i와answer가 있다.i는 answer의 인덱스이고,answer는 해당 인덱스의 실제값이다.
- 이떄 i는 0부터 증가한다.
- 쉽게 말해, answers 배열의 데이터를 0번부터 끝까지 반복하는 반복문이다.
- 이렇게 배열 전체를 반복해야 하는 경우 of 연산자를 활용하면 편리하게 반복문을 작성할 수 있다.
바깥 반복문은 answers, 안쪽 반복문은 patterns의 데이터를 하나씩 가리킨다.
- answer의 각 답안과 수포자들의 정답을 하나씩 비교하면서 정답이 일치하는 수포자의 경우 score를 1만큼 더한다.
- 정답 패턴의 길이가 수포자의 답안 길이보다 긴 경우,
- 정답 패턴의 처음 데이터와 다시 비교할 수 있도록 나머지 연산자를 사용했다.
1answer === pattern[i % pattern.length]
(4) 반복문에서 구한 각 수포자들의 점수 중 가장 큰 점수를 찾는다.
- 동일 점수가 있을 수도 있으므로 일단 가장 큰 점수를 구하고 이 점수와 같은 수포자들을 찾는 방식을 구현한다.
(5) 가장 큰 점수를 갖는 수포자들을 찾아 배열에 담아 반환한다.
✅ 시간 복잡도 분석
N은 answers의 길이이다. 각 수포자들의 패턴과 정답을 비교하는 부분은 이다. 이후 scores를 순회하면서 가장 높은 점수를 받은 수포자를 추가하는 연사은 이다. 따라서 최종 시간복잡도는 이다.
5.3 행렬의 곱셈⭐️
2차원 행렬 arr1과 arr2를 입력받아 arr1에 arr2를 곱한 결과를 반환하는 solution()를 완성하세오
✅ 제약 조건
- 행렬 arr1, arr2의 행과 열의 길이는 2 이상 100 이하다.
- 행렬 arr1, arr2의 데이터는 -10 이상 20이하인 자연수다.
- 곱할 수 있는 배열만 주어진다.
✅ 입출력의 예
| arr1 | arr2 | Return |
|---|---|---|
| [[1, 4], [3, 2], [4, 1]] | [[3, 3], [3, 3]] | [[15, 15], [15, 15], [15, 15]] |
| [[2, 3, 2], [4, 2, 4], [3, 1, 4]] | [[5, 4, 3], [2, 4, 1], [3, 1, 1]] | [[22, 22, 11], [36, 28, 18], [29, 20, 14]] |
✅ 분석
수학의 행렬 곱셈을 그대로 구현하면 된다. 두 배열의 최대 데이터 개수가 100개이므로 시간 복잡도는 신경쓰지 않아도 된다. 또한 곱할 수 있는 배열만 주어지므로 예외 처리도 없다.
1// https://school.programmers.co.kr/learn/courses/30/lessons/1294923function solution(arr1, arr2) {4// (1) 행렬 arr1과 arr2의 행과 열의 수5const r1 = arr1.length6const c1 = arr1[0].length78const r2 = arr2.length9const c2 = arr2[0].length1011// (2) 결과를 저장할 2차원 배열 초기화12const ret = []13for (let i = 0; i < r1; i++) {14ret.push(new Array(c2).fill(0))15}1617// (3) 첫 번째 행렬 arr1의 각 행과 두 번째 행렬 arr2의 각 열에 대해18for (let i = 0; i < r1; i++) {19for (let j = 0; j < c2; j++) {20// (4) 두 행렬의 데이터를 곱해 결과 배열에 더해줌21for (let k = 0; k < c1; k++) {22ret[i][j] += arr1[i][k] * arr2[k][j]23}24}25}2627return ret28}
여기서 문제를 나누는 연습을 해보면 좋다.
- 행렬 곱셈에서 가장 먼저 행렬 곱셈의 결과값을 어떻게 저장할지 고려해야 한다.
- 결과값을 저장하려면 두 행렬을 곱했을 떄, 결과 행렬의 크기를 알아야 한다.
- 이건 행렬의 정의를 안다면 쉽게 해결가능하다.
(1) 인수로 받은 arr1과 arr2의 행과 열 정보를 변수에 기록한다. 이후 행렬 정의를 활용해서 결과 행렬을 저장할 수 있는 크기의 새 행렬을 만들고 모든 데이터를 0으로 초기화한다.
(2) 결과 행렬의 크기는 (r1 * c2)이므로 해당 크기의 배열을 미리 만들어 0으로 초기화한다.
즉, ret에는 행렬 곱 결과가 저장된다.
(3) arr1과 arr2의 행렬을 곱하기 위한 반복문이다. 행렬을 곱할 떄 첫 번쨰 행렬의 각 행과 두 번쨰 행렬의 각 열들을 매치해 연산한다. 이를 위해 반복문에서 첫 번쨰 행렬의 행의 크기인 r1과 두 번쨰 행렬의 열의 크기인 c2를 사용했다.
(4)에서는 첫 번쨰 행렬의 i번쨰 행과 두 번쨰 행렬의 j번쨰 열을 곱한다. 마지막으로 반복문에서 곱 연산을 수행하며 ret 배열에 데이터를 저장하면 행렬 곱이 완성된다.
✅ 시간 복잡도 분석
N은 행 혹은 열의 길이이다. 행과 열의 길이는 같다.
- arr1의 행과 열 수를 r1, c1라고 하고, arr2의 행과 열의 수를 r2, c2라고 했을 떄,
r1*c1*c2만큼 연산한다. - r1, c1, r2, c2 모두 N으로 볼 수 있으므로, 최종 시간 복잡도는 이다.
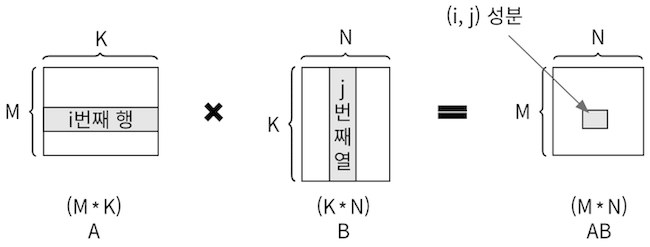
💡 행렬 곱 리마인드
A 행렬의 크기가
(M * K), B행렬의 크기가(K * N)일 떄, 두 행렬의 곱 연산은 행렬 A의 행 길이(K)와 행렬 B의 열 길이(K)가 같아야 하며, 행렬 곱 결과는(M*N)이다.
5.4 실패율⭐️⭐️
슈퍼 게임 개발자 오렐리는 큰 고민에 빠졌다. 그녀가 만든 프랜즈 오천성이 대성공을 거뒀지만, 요즘 신규 사용자의 수가 급감한 것이다. 원인은 신규 사용자와 기존 사용자 사이에 스테이지 차이가 너무 큰 것이 문제였다.
이 문제를 어떻게 할까 고민 한 그녀는 동적으로 게임 시간을 늘려서 난이도를 조절하기로 했다. 역시 슈퍼 개발자라 대부분의 로직은 쉽게 구현했지만, 실패율을 구하는 부분에서 위기에 빠지고 말았다. 오렐리를 위해 실패율을 구하는 코드를 완성하라.
- 실패율은 다음과 같이 정의한다.
- 스테이지에 도달했으나 아직 클리어하지 못한 플레이어의 수 / 스테이지에 도달한 플레이어 수
전체 스테이지의 개수 N, 게임을 이용하는 사용자가 현재 멈춰있는 스테이지의 번호가 담긴 배열 stages가 매개변수로 주어질 때, 실패율이 높은 스테이지부터 내림차순으로 스테이지의 번호가 담겨있는 배열을 return 하도록 solution 함수를 완성하라.
✅ 제약 조건
- 스테이지의 개수 N은
1이상500이하의 자연수이다. - stages의 길이는
1이상200,000이하이다. - stages에는
1이상N + 1이하의 자연수가 담겨있다.- 각 자연수는 사용자가 현재 도전 중인 스테이지의 번호를 나타낸다.
- 단,
N + 1은 마지막 스테이지(N 번째 스테이지) 까지 클리어 한 사용자를 나타낸다.
- 만약 실패율이 같은 스테이지가 있다면 작은 번호의 스테이지가 먼저 오도록 하면 된다.
- 스테이지에 도달한 유저가 없는 경우 해당 스테이지의 실패율은
0으로 정의한다.
✅ 입출력의 예
| N | stages | result |
|---|---|---|
| 5 | [2, 1, 2, 6, 2, 4, 3, 3] | [3,4,2,1,5] |
| 4 | [4,4,4,4,4] | [4,1,2,3] |
첫 번째 입출력 예를 보면, 1번 스테이지에는 총 8명의 사용자가 도전했으며, 이 중 1명의 사용자가 아직 클리어하지 못했다. 따라서 1번 스테이지의 실패율은 다음과 같다.
- 1 번 스테이지 실패율 : 1/8
2번 스테이지에는 총 7명의 사용자가 도전했으며, 이 중 3명의 사용자가 아직 클리어하지 못했다. 따라서 2번 스테이지의 실패율은 다음과 같다.
- 2 번 스테이지 실패율 : 3/7
마찬가지로 나머지 스테이지의 실패율은 다음과 같다.
- 3 번 스테이지 실패율 : 2/4
- 4번 스테이지 실패율 : 1/2
- 5번 스테이지 실패율 : 0/1
각 스테이지의 번호를 실패율의 내림차순으로 정렬하면 다음과 같다.
- [3,4,2,1,5]
두 번쨰 입출력 예를 보면, 모든 사용자가 마지막 스테이지에 있으므로 4번 스테이지의 실패율은 1이며 나머지 스테이지의 실패율은 0이다.
- [4,1,2,3]
✅ 분석
구현 난이도 자체가 높지는 않지만 문제를 풀 떄 어떤 식으로 접근해야 하는지 연습하기 좋은 문제다.
- 문제에서 새 용어를 정의하는 부분이 나오면 반드시 이해하고 넘어가야 한다.
- 바로 그 부분이 문제의 핵심인 경우가 많기 때문이다.
- 이 문제에서는 실패율이라는 용어가 나온다.
- 실패율이란 해당 스테이지에 도달한 적이 있는 사용자 중 아직 클리어하지 못한 사용자의 비율을 말한다.
- 실패율을 그림으로 생각해보면 다음과 같다.
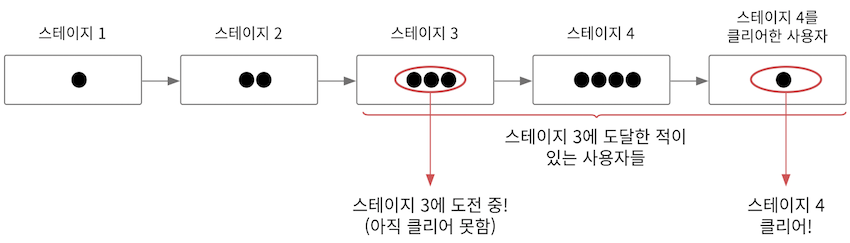
그림은 스테이지가 4까지 있는 경우, 즉 N이 4이다.
- 그림에 스테이지 4 이후 1칸을 더 그린 이유는 스테이지 4까지 클리어한 사람을 표시하기 위함이다.
- 그리고 스테이지 3의 실패율은
3 / (3+4+1)이므로3/8이다. - 이렇게 각 스테이지의 실패율을 구하고 실패율을 기준으로 내림차순으로 사용자 번호를 정렬해서 반환하면 된다.
- stages가 20만까지 입력될 수 있으므로 시간 초과를 방지하려면,
- 정렬 알고리즘의 시간 복잡도는 이어야 한다.
- 만약 시간 복잡도가 인 알고리즘을 사용한다면 시간 초과를 발생할 수 있다.
- cf. 정렬 문제는 정렬 구현을 시간들여 고민하는 대신 JS 제공 함수를 바로 사용해보는 것도 좋은 전략이다.
1// https://school.programmers.co.kr/learn/courses/30/lessons/4288923function solution(N, stages) {4// (1) 스테이지별 도전자 수를 구함5const challenger = new Array(N + 2).fill(0)6for (const stage of stages) {7challenger[stage] += 18}910// (2) 스테이지별 실패한 사용자 수 계산11const fails = {}12let total = stages.length1314// (3) 각 스테이지를 순회하며, 실패율 계산15for (let i = 1; i <= N; i++) {16if (challenger[i] === 0) {17// (4) 도전한 사람이 없는 경우, 실패율은 018fails[i] = 019continue20}2122// (5) 실패율 계산23fails[i] = challenger[i] / total2425// (6) 다음 스테이지 실패율을 구하기 위해 현재 스테이지의 인원을 뺌26total -= challenger[i]27}2829// (7) 실패율이 높은 스테이지부터 내림차순으로 정렬30const result = Object.entries(fails).sort((a, b) => b[1] - a[1])3132// (8) 스테이지 번호만 반환33return result.map((v) => Number(v[0]))34}
(1) challenger는 각 스테이지에 도전하는 사용자 수를 저장하는데 사용하는 배열이다.
- 배열의 크기를 N+2로 정한 이유도 나름의 문제를 풀기 위한 전략이다.
- 왜냐면, N번쟤 스테이지를 클리어한 사용자는 stage가 N+1이다.
- 그러면 challenger 배열에서 N+1 위치에 데이터를 저장해야 하는데, 배열의 인덱스는 0부터 시작하므로,
- N+1 인덱스에 데이터를 저장하려면 N+2 크기의 배열이 필요하기 때문이다.
- 물론 이렇게 하면 0번쨰 인덱스는 사용하지 않아서 낭비라고 생각할 수 있지만,
- 이렇게 하면 실보다 득이 크다.
- 반복문을 보면 각 stages 데이터의 값을 challenger의 인덱스로 사용할 수 있게 된다.
- 이렇게 하면 값 자체를 인덱스로 활용할 수 있어 매우 편리하다.
- 메모리 공간 1칸만 비우고 편리함을 취했다고 할 수 있다.
- cf. 이와 유사한 정렬 알고리즘은 계수 정렬이다. 계수 정렬은 뒤에서 설명한다.
(2) fails는 실패율을 저장하는 용도이고, total의 값은 총 사용자의 수이다. 해당 변수들이 어떻게 사용되는지는 아래에 자세히 설명한다.
(3) 이 문제의 핵심으로 즉, 실패율을 구하는 로직이다. 위에서 구한 challengers값을 활용해서 실패율을 구한다.
(4) 해당 스테이지에 있는 사용자가 0이라면, 문제 정의에 의해 실패율은 0이 되므로 계산은 간단하다.
(5) 해당 스테이지에 사용자가 있다면, 실패율 공식을 적용해서 실패율을 구한다.
- fails는 배열이 아니고 객체라는 것을 기억해야 한다.
- 다시 말해
fails[i] = challenger[i] / total에서 키는i, 값은challenger[i] / total이며 이 값들이 쌍을 이뤄 fails 객체 변수에 저장된다고 보면 된다. - tatal의 값은 현재 스테이지에 도달한 사용자 값이다.
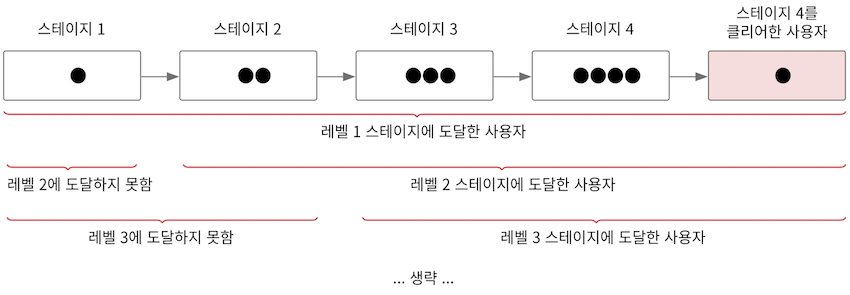
(6) N번쨰 스테이지에 도달한 사용자의 수를 구하려면 N-1번쨰 스테이지에 있는 사용자의 수를 빼면 된다.
- e.g. 3번쨰 스테이지에 도달한 사용자 수를 구하려면 2번째 스테이지에 있는 사용자 수를 제외하면 된다.
- 따라서 총 사용자 수에서 각 스테이지의 인원 수를 뺴면 이 값이 다음 스테이지에 도달한 사용자 수가 된다.
- 이러한 이유로 total 값은 초기에는 전체 사용자 수에서 시작해서 각 stage의 실패율을 구할 떄마다 현재 stage의 인원을 빼며 코드가 실행된다.
- 설명이 복잡하지만 위 그림을 보자.
(7) fails는 객체이다. 키는 각 스테이지를 가리키는 숫자, 값은 실패율은 의미한다.
- 객체를 정렬하기 위해선 먼저 배열로 변환해야 한다.
- 이떄 Object.entries 메서드를 사용하면 키와 값을 쌍으로 묶어서 배열로 만드는 것이 가능하다.
- cf. 배열을 이용해서 묶어준다.
- 0번쨰 인덱스가 키, 1번쨰 인덱스가 값이다.
(8) 정렬을 했다면 스테이지 번호만 반환해야 하므로 map을 이용하여 스테이지 번호만 추출한다.
- 이떄 키는 문자열이기 때문에 Number를 통해 숫자를 반환해준다.
✅ 시간 복잡도 분석
N은 스테이지의 개수이고, M은 stages의 길이이다.
- challenger 배열을 초기화하고, 각 스테이지 도전자 수를 계산할 떄 시간 복잡도는 이다.
- 이후 스테이지 별로 실패율을 계산하는데 필요한 시간 복잡도는 이고,
- 실패율을 기준으로 스테이지를 정렬할 떄의 시간 복잡도는 O(NlogN)이다.
- 이 연산들을 모두 고려하면 시간 복잡도는 이므로,
- 최종 시간 복잡도는 이다.
5.5 방문 길이⭐️⭐️
게임 캐릭터를 4가지 명령어를 통해 움직이려 합니다. 명령어는 다음과 같습니다.
- U: 위쪽으로 한 칸 가기
- D: 아래쪽으로 한 칸 가기
- R: 오른쪽으로 한 칸 가기
- L: 왼쪽으로 한 칸 가기
캐릭터는 좌표평면의 (0, 0) 위치에서 시작합니다.
좌표평면의 경계는 왼쪽 위(-5, 5), 왼쪽 아래(-5, -5), 오른쪽 위(5, 5), 오른쪽 아래(5, -5)로 이루어져 있습니다.
예를 들어, “ULURRDLLU”로 명령했다면 1번 명령어부터 7번 명령어까지 다음과 같이 움직입니다.
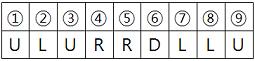
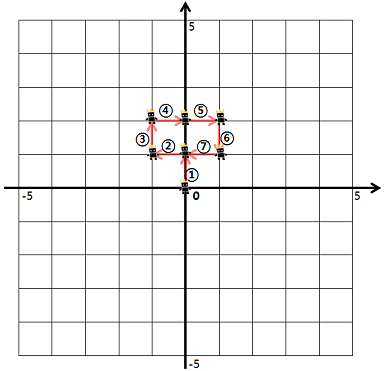
8번 명령어부터 9번 명령어까지 다음과 같이 움직입니다.
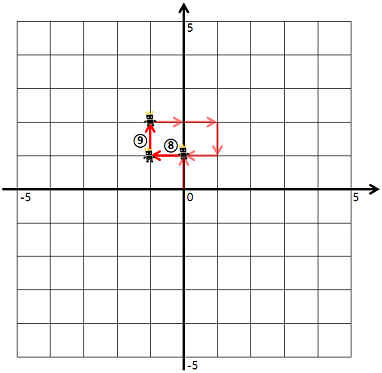
이때, 우리는 게임 캐릭터가 지나간 길 중 캐릭터가 처음 걸어본 길의 길이를 구하려고 합니다. e.g. 위의 예시에서 게임 캐릭터가 움직인 길이는 9이지만, 캐릭터가 처음 걸어본 길의 길이는 7이 됩니다. (다시 말해, 8, 9번 명령어에서 움직인 길은 2, 3번 명령어에서 이미 거쳐 간 길입니다)
단, 좌표평면의 경계를 넘어가는 명령어는 무시합니다.
e.g. “LULLLLLLU”로 명령했다면
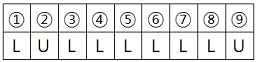
- 1번 명령어부터 6번 명령어대로 움직인 후, 7, 8번 명령어는 무시합니다. 다시 9번 명령어대로 움직입니다.
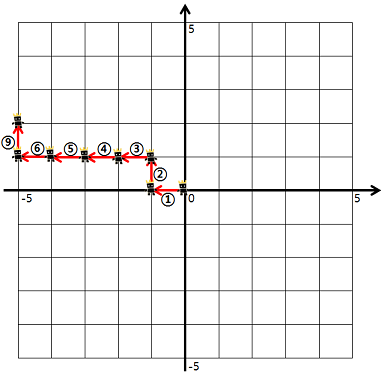
이때 캐릭터가 처음 걸어본 길의 길이는 7이 됩니다. 명령어가 매개변수 dirs로 주어질 때, 게임 캐릭터가 처음 걸어본 길의 길이를 구하여,return 하는 solution 함수를 완성하세요.
✅ 제약 조건
- dirs는 string형으로 주어지며, ‘U’, ‘D’, ‘R’, ‘L’ 이외에 문자는 주어지지 않습니다.
- dirs의 길이는 500 이하의 자연수입니다.
✅ 입출력의 예
| dirs | answer |
|---|---|
| ”ULURRDLLU” | 7 |
| ”LULLLLLLU” | 7 |
✅ 분석
이 문제는 명령어대로 로봇이 이동할 떄 중복 경로의 길이를 제외한 움직인 경로의 길이를 반환해야 한다. 이 문제의 경우 문제 자체가 복잡하지 않지만 구현 시 실수하기 쉽다. 어디에서 실수하기 쉬울까?
첫 번쨰, 중복 경로는 최종 길이에 포함하지 않는다는 조건이다. 이 부분을 어떻게 처리할지 충분히 고민해야 한다.
- 중복을 포함하지 않는다는 문장이 나오면 set을 생각해보면 좋다.
- 언급했던 것처럼 중복 처리를 직접하는 것보다 괜찮다.
두 번쨰, 음수 좌표를 포함한다는 점이다. 문제를 보면 좌표 범위는 -5 <= x, y <= 5이다.
- 2차원 배열에서 음수 인덱스를 사용할 수는 없으므로 다른 방법을 생각해야 한다.
- 문제의 핵심은 원점에서 출발해 최종 경로의 길이를 구하는 건데, 좌표는 방향에 의해서만 제어된다는 점이다.
- 따라서 원점을 (0, 0)에서 (5, 5)로 바꿔 음수 좌표 문제를 해결해도 된다.
- 이 문제는 구현 문제이므로 별다른 알고리즘 설명은 필요하지 않다.
- 다른 알고리즘 문제도 마찬가지지만,
- 구현 문제는 답안 코드의 길이가 긴 경우가 많으므로 기능별로 함수를 구현하는 게 좋다.
- 처음부터 기능별 구현이 잘 될 수는 없다.
- 그럴 때는 일단 하나의 함수로 전체 동작을 구현해보고 이후 함수로 나누는 연습을 해보기 바란다.
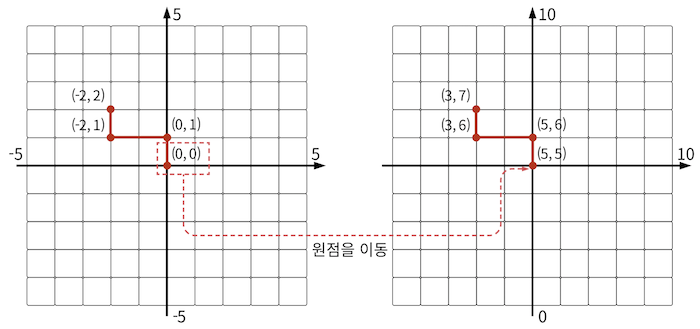
위 2개를 해결했다면, 이제 명령어에 따라 좌표의 경로를 추가한 뒤 중복 경로를 제거한 최종 이동 길이를 반환하면 된다.
1// https://school.programmers.co.kr/learn/courses/30/lessons/4999423function isValidMove(nx, ny) {4// (1) 좌표평면을 벗어나는지 체크하는 함수5return nx >= -5 && nx <= 5 && ny >= -5 && ny <= 56}78function updateLocation(x, y, dir) {9// (2) 명령어를 통해 다음 좌표 결정10switch (dir) {11case 'U':12return [x, y + 1]13case 'D':14return [x, y - 1]15case 'R':16return [x + 1, y]17case 'L':18return [x - 1, y]19}20}2122function solution(dirs) {23let x = 024let y = 02526const visited = new Set() // (3) 겹치는 좌표는 1개로 처리하기 위함27for (const dir of dirs) {28// (4) 주어진 명령어로 움직이면서 좌표 저장29const [nx, ny] = updateLocation(x, y, dir)3031if (!isValidMove(nx, ny)) {32// (5) 벗어난 좌표는 인정하지 않음33continue34}3536// (6) A에서 B로 간 경우 B에서 A도 추가해야 함(총 경로의 개수는 방향성이 없음)37visited.add(`${x}${y}${nx}${ny}`)38visited.add(`${nx}${ny}${x}${y}`)39;[x, y] = [nx, ny] // (7) 좌표를 이동했으므로 업데이트40}4142return visited.size / 243}
(1) 좌표가 주어진 범위를 초과했는지 체크하는 함수다. 해당 함수는 좌표 문제에 단골로 등장한다. 핵심 알고리즘이랑 분리해 가독성을 높였다.
(2) 현재 좌표와 방향을 받아 그다음 좌표를 반환하는 함수다.
(3) 중복 좌표를 처리하기 위해 visited는 Set으로 정의한다.
(4) 주어진 명령어 순서대로 순회하는 코드다.
(5) 주어진 명령어를 기준으로 다음 좌표를 구하고 해당 좌표가 유효한지 체크한다. 유효하지 않으면 visited에 좌표를 추가하지 않는다.
(6) add('${x}${y}${nx}${ny}')는 (x, y)에서 (nx, ny)까지의 경로를 방문했다.라고 기록하는 것을 의미한다.
- 여기서 넣는 값을 문자열로 한 이유는 객체를 넣게 될 경우 중복 체크가 제대로 안되기 때문이다.
- cf. JS의 객체는 참조 타입이므로 원시 타입과 다르게 비교할 때, 값이 아닌 메모리 주소를 따진다.
- 이때 (x, y)에서 (nx, ny)만 저장하는 것이 아니라 그 반대인 (nx, ny)에서 (x, y) 역시 추가하는데,
- 이 부분을 이해해야 코드를 제대로 이해한 것이라 할 수 있다.
(7) 현재 좌표를 업데이트한다.
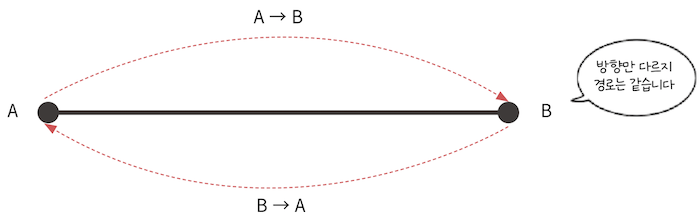
위 그림을 보면, A → B와 B → A는 이 문제에서는 같은 경로로 취급한다. 따라서 A → B인 경우, A → B와 B → A를 둘 다 추가하고 나중에 최종 이동 길이를 2로 나눈다.
✅ 시간 복잡도 분석
N은 dirs의 길이이다. dirs의 길이만큼 순회하므로 시간 복잡도는 O(N)이다.
6. 추천 문제
- 배열의 평균값 : https://school.programmers.co.kr/learn/courses/30/lessons/120817
- 배열 뒤집기 : https://school.programmers.co.kr/learn/courses/30/lessons/120821
- 배열 자르기 : https://school.programmers.co.kr/learn/courses/30/lessons/87390
- 나누어 떨어지는 숫자 배열 : https://school.programmers.co.kr/learn/courses/30/lessons/12910