1. 트라이(Trie)
검색 엔진에서 자동완성을 하려면 어떻게 해야할까요?
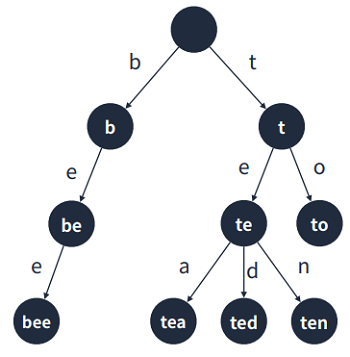
- 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조
- e.g. 검색엔진 연관 검색어
1.1 트라이 특징
- 검색어 자동완성, 사전 찾기 등에 응용될 수 있다.
- 문자열을 탐색할 떄 단순하게 비교하는 것보다 효율적으로 찾을 수 있다.
- L이 문자열의 길이일 떄 탐색, 삽입은 만큼 걸린다.
- 대신 각 정점이 자식에 대한 링크를 전부 가지고 있기에 저장 공간을 더 많이 사용한다.
1.2 Trie 생성하기
1.2.1 트라이 구조
- 루트는 비어있다.
- 각 간선(링크)은 추가될 문자를 키로 가진다.
- 각 정점은 이전 정점의 값 + 간선의 키를 값으로 가진다.
- 해시 테이블과 연결 리스트를 이용하여 구현할 수 있다.
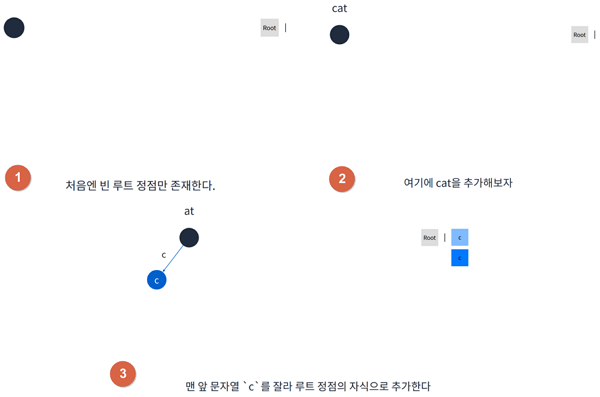


2. 구현
1class Node {2constructor(value = '') {3this.value = value4this.children = new Map()5}6}78class Trie {9// Trie를 생성하면 루트로 빈 노드를 생성10constructor() {11this.root = new Node()12}1314// 문자열을 추가하면 탐색을 위해서 루트부터 시작15insert(string) {16let currentNode = this.root17// 문자열을 앞에서 부터 하나씩 자르면서 순회18for (const char of string) {19// 만약 현재 노드에서 자른 문자열을 간선으로 가지고 있지 않다면 새 노드를 추가20if (!currentNode.children.has(char)) {21currentNode.children.set(char, new Node(currentNode.value + char))22}23// 다음 정점으로 이동24currentNode = currentNode.children.get(char)25}26}2728// 문자열이 존재하는지 체크29has(string) {30let currentNode = this.root3132for (const char of string) {33if (!currentNode.children.has(char)) {34return false35}36currentNode = currentNode.children.get(char)37}38return true39}40}4142const trie = new Trie()43trie.insert('cat')44trie.insert('can')45console.log(trie.has('cat')) // true46console.log(trie.has('can')) // true47console.log(trie.has('cap')) // false
2. 트라이 실습 : 자동완성
2.1 문제
포털 다음에서 검색어 자동완성 기능을 넣고 싶은 라이언은 한 번 입력된 문자열을 학습해서 다음 입력 때 활용하고 싶어 졌다.
예를 들어, go 가 한 번 입력되었다면, 다음 사용자는 g 만 입력해도 go를 추천해주므로 o를 입력할 필요가 없어진다!
단, 학습에 사용된 단어들 중 앞부분이 같은 경우에는 어쩔 수 없이 다른 문자가 나올 때까지 입력을 해야 한다.
효과가 얼마나 좋을지 알고 싶은 라이언은 학습된 단어들을 찾을 때 몇 글자를 입력해야 하는지 궁금해졌다.
예를 들어, 학습된 단어들이 아래와 같을 때
1go2gone3guild
go를 찾을 때go를 모두 입력해야 한다.gone을 찾을 때gon까지 입력해야 한다. (gon이 입력되기 전까지는go인지gone인지 확신할 수 없다.)guild를 찾을 때는gu까지만 입력하면guild가 완성된다.
이 경우 총 입력해야 할 문자의 수는 7이다.
라이언을 도와 위와 같이 문자열이 입력으로 주어지면 학습을 시킨 후, 학습된 단어들을 순서대로 찾을 때 몇 개의 문자를 입력하면 되는지 계산하는 프로그램을 만들어보자.
[입력 형식]
학습과 검색에 사용될 중복 없는 단어 N개가 주어진다.
모든 단어는 알파벳 소문자로 구성되며 단어의 수 N과 단어들의 길이의 총합 L의 범위는 다음과 같다.
2 <= N <= 100,0002 <= L <= 1,000,000
[출력 형식]
단어를 찾을 때 입력해야 할 총 문자수를 리턴한다.
[입출력 예제]
| words | result |
|---|---|
| [“go”,“gone”,“guild”] | 7 |
| [“abc”,“def”,“ghi”,“jklm”] | 4 |
| [“word”,“war”,“warrior”,“world”] | 15 |
[입출력 설명]
- 첫 번째 예제는 본문 설명과 같다.
- 두 번째 예제에서는 모든 단어들이 공통된 부분이 없으므로, 가장 앞글자만 입력하면 된다.
- 세 번째 예제는 총 15 자를 입력해야 하고 설명은 아래와 같다.
word는word모두 입력해야 한다.war는war까지 모두 입력해야 한다.warrior는warr까지만 입력하면 된다.world는worl까지 입력해야 한다. (word와 구분되어야 함을 명심하자)
2.2 풀이
2.2.1 문제 유형
사실 문제 이름부터 자동완성이기 때문에 바로 Trie를 떠올릴 수 있습니다. 거기에 문제 내용까지 살펴보면 자동완성 기능이 되어야 최소 입력 글자를 알 수 있기에 이 문제에선 Trie가 가장 효율적인 자료구조라는 것을 알 수 있습니다.
2.2.2 풀이
Trie 구조를 만들면서 하위에 어떤 문자들이 있는지 미리 알아야 셀 수 있습니다. 예를 들어, guild를 찾을 때 gu만 입력해도 된다는 것을 알기 위해 Trie 구조에 해당 정보들을 넣어놔야 합니다.
다음과 같이 Trie 구조를 구성할 수 있습니다.
- “go”를 넣는다.
- 루트의 자식 노드로 “g”를 추가한다. 이때 “g” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. (“g”, 1)과 같은 형태로 상태를 저장한다.
- “g”의 자식 노드로 “o”를 추가한다. 이때 “o” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “o” 노드는 카운팅이 1이 된다.
- “gone”을 넣는다.
- 루트의 자식 노드로 “g”를 추가한다. 이때 “g” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “g” 노드는 카운팅이 2가 된다.
- “g”의 자식 노드로 “o”를 추가한다. 이때 “o” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “o” 노드는 카운팅이 2가 된다.
- “o”의 자식 노드로 “n”을 추가한다. 이때 “n” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “n” 노드는 카운팅이 1이 된다.
- “n”의 자식 노드로 “e”을 추가한다. 이때 “e” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “e” 노드는 카운팅이 1이 된다.
- “guild”를 넣는다.
- 루트의 자식 노드로 “g”를 추가한다. 이때 “g” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “g” 노드는 카운팅이 3가 된다.
- “g”의 자식 노드로 “u”를 추가한다. 이때 “u” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “u” 노드는 카운팅이 1이 된다.
- “u”의 자식 노드로 “i”를 추가한다. 이때 “i” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “i” 노드는 카운팅이 1이 된다.
- “i”의 자식 노드로 “l”를 추가한다. 이때 “l” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “l” 노드는 카운팅이 1이 된다.
- “l”의 자식 노드로 “d”를 추가한다. 이때 “d” 노드에 단어가 추가되었음을 알리기 위해 카운팅을 해준다. “d” 노드는 카운팅이 1이 된다.
그럼 Trie 구조가 다음과 같이 구성됩니다.
1[3, "g"]2/ \3[1, "u"] [2, "o"]4| |5[1, "i"] [1, "n"]6| |7[1, "l"] [1, "e"]8|9[1, "d"]
Trie 구조가 완성되었다면 이후 각 단어들을 찾으며 카운팅이 1이라면 이후 글자를 입력하지 않아도 된다는 것을 알 수 있기 때문에 그 지점에서 카운팅을 멈추면 됩니다.
2.2.3 전체 코드
위 알고리즘을 구현하면 다음과 같습니다.
1function makeTrie(words) {2const root = {} // 먼저 루트 노드를 설정할 변수를 만든다.3for (const word of words) {4// Trie를 구성하기 위한 루프를 돌린다.5let current = root // 루프부터 시작6for (const letter of word) {7// 단어의 글자를 하나씩 춫출한 후8// 값을 넣는다. 리스트의 첫 번째 값은 학습된 단어가 몇 개인지를 카운팅하고9// 두 번째 값은 트리 구조로 이용할 노드 값으로 사용한다.10if (!current[letter]) current[letter] = [0, {}]11current[letter][0] = 1 + (current[letter][0] || 0) // 카운팅을 위해 1 더해준다.12current = current[letter][1] // current는 letter에 해당되는 노드로 이동한다.13}14}1516return root // 반환17}1819function solution(words) {20let answer = 021const trie = makeTrie(words) // Trie 자료구조를 만들어준다.2223for (const word of words) {24// 입력받은 수 만큼 루프25let count = 0 // 카운팅을 위한 변수26let current = trie // 루트부터 시작27for (const [index, letter] of [...word].entries()) {28count += 129if (current[letter][0] <= 1) {30// 단어가 하나 이하로 남을 경우 종료31break32}33current = current[letter][1] // 다음 노드로 이동34}35answer += count // 카운팅을 더해준다36}37return answer // 반환38}