1. 전송 계층 개요: IP의 한계와 포트
지난 장에 학습한 네트워크 계층의 IP는 신뢰할 수 없는 통신과 비연결형 통신을 수행한다는 한계가 있다.
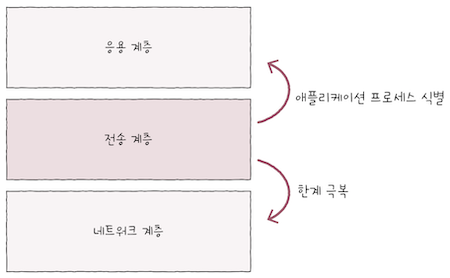
- 네트워크 계층과 응용 계층 사이에 위치한 전송 계층은
신뢰할 수 없는 통신과연결형 통신을 가능하게 하여, - 이런 IP의 한계를 극복하고, 포트 번호를 통해 응용 계층의 애플리케이션 프로세스들을 식별하는 역할을 수행한다.
1.1 신뢰할 수 없는 통신과 비연결형 통신
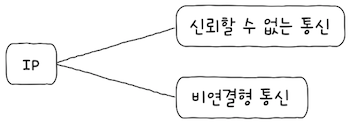
네트워크 계층의 핵심 프로토콜인 IP는 크게 IP 단편화와 IP 주소 지정을 한다고 배웠다.
하지만 이외에도 IP의 한계라고 볼 수 있는 2가지 중요한 특징이 있다.
- IP는 신뢰할 수 없는
(비신뢰성) 프로토콜(unreliable protocol)이다. - IP는
비연결형 프로토콜(connectionless protocol)이다.
달리 표현하면, IP를 통한 패킷의 전달은 신뢰성이 없는 통신이자 연결을 수립하는 과정이 없는 통신이다. 이는 전송 계층이 존재하는 이유와도 직결된다.
💡
프로토콜의 (비)연결형은 (비)연결성, (비)연결지향성, (비)연결지향형 등으로 표현하기도 한다.

(1) 신뢰할 수 없는 통신은 IP 프로토콜이 패킷이 수신지까지 제대로 전송되었다는 보장을 하지않는 특징을 일컫는다.
- 이는 통신 과정에서 패킷의 데이터가 손실되거나 중복된 패킷이 전송되었더라도, 이를 확인하지 않고,
- 재전송도 하지 않으며, 순서대로 패킷이 도착하지 않는다는 의미다.
- 이러한 전송 특성을 다른 말로
최선형 전달(best effort delivery)라고 부른다.
최선형 전달이란 말은 언뜻 들으면 믿음직하게 들릴지도 모르지만,- 본뜻은
최선을 다해 보겠지만, 전송 결과에 대해서는 어떠한 보장도 하지 않겠다를 의미한다.
- 본뜻은
(2) 비연결형 통신은 이름 그대로 송수신 호스트 간에 사전 연결 수립 작업을 거치지 않는 특징을 의미한다.
- 그저 수신지를 향해 패킷을 보내기만 할 뿐이다.
그렇다면 IP는 왜 어떠한 보장도 없이 신뢰할 수 없는, 비연결형 통신을 할까? 주요한 이유는 성능때문이다.
- 모든 패킷이 제대로 전송되었는지 일일이 확인하고,
- 호스트 간에 연결을 수립하는 작업은 일반적으로 패킷의 ‘빠른’ 송수신과는 배치되는 작업이다.
- 더 많은 시간, 대역폭, 부하가 요구되고, 이는 곧 성능상 악영향으로 이어진다.
- 인터넷 상에서 돌아다니는 패킷의 종류와 개수는 매우 다양하다.
- 금융 서비스처럼 반드시 신뢰성있는 전송을 보장해야 하는 경우도 있지만,
- 스트리밍 서비스나 실시간 영상통화처럼 한두 개의 패킷 손실은 감수하더라도 빠른 전송이 우선시되는 경우도 있다.
- 실제로 실시간 동영상 스트리밍 서비스는 패킷이 한두 개 손실되더라도,
- 일시적으로 화질에 다소 악영향이 생길 수 있어도, 일반적으로 시청에 큰 지장을 주지는 않는다.
- 이처럼 신뢰성있는 전송이 모든 경우에 필요한 경우는 아니다.
1.2 IP의 한계를 보완하는 전송 계층
네트워크 계층의 핵심프로토콜인 IP의 한계를 이해했으니, 이제 전송 계층이 이를 어떻게 보완하는지 알아보자.
(1) 전송 계층은 연결형 통신을 가능하게 한다.
연결형 통신을 지원하는 대표적인 전송 프로토콜로 TCP가 있다.
- 1장에서 학습한 회선 교환 네트워크를 배웠었다.
- 전송 계층의 연결형 프로토콜인
TCP는 이와 유사하게두 호스트가 정보를 주고받기 전에, 마차 가상의 회선을 설정하듯 연결을 수립한다.- 송수신하는 동안에는 연결을 유지하고, 송수신이 끝나면 연결을 종료할 수 있다.
- cf.
회선 교환 방식은 호스트 간에 메시지를 주고받기 전에, 호스트 사이에 메시지 전송로(회선)을 설정하고,- 해당 전송로를 이용해서 메시지를 주고받는 방식이다.
(2) 전송 계층은 신뢰성있는 통신을 가능하게 한다.
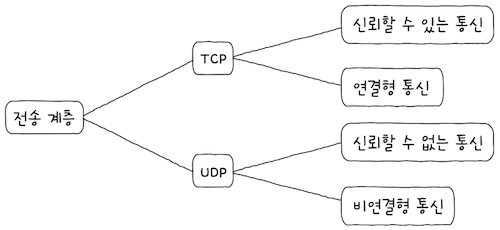
신뢰성있는 통신 또한 TCP를 통해 가능하다.
TCP는 패킷이 수신지까지 올바른 순서대로 확실히 전달되는 것을 보장하기 위해,- 재전송을 통한
오류 제어,흐름 제어,혼잡 제어등 다양한 기능들을 제공한다. - cf. 모두 이번 장에서 학습한다.
- 재전송을 통한
- 앞서 설명한 것처럼
연결형 통신과신뢰성있는 통신이 그렇지 않은 통신에 비해 무조건 좋은 것만은 아니다. - 때로는 비교적 높은 성능을 위해 신뢰할 수 없는 통신, 비연결형 통신을 지원하는 프로토콜이 필요할 떄가 있다.
- 그래서
전송 계층에는UDP라는 프로토콜이 존재한다.UDP는신뢰할 수 없는 통신,비연결형 통신을 가능하게 하는 전송 계층 프로토콜로- TCP보다 비교적 빠른 전송이 가능하다.
1.3 응용 계층과의 연결 다리, 포트
앞서 전송 계층이 네트워크 계층의 한계를 극복한다는 점을 설명했다.
- 이번에는 응용 계층과의 연결 다리 역할로서의 전송 계층을 살펴본다.
- 이를 이해하려면 포트가 무엇인지 이해해야 한다.
1.3.1 포트의 정의
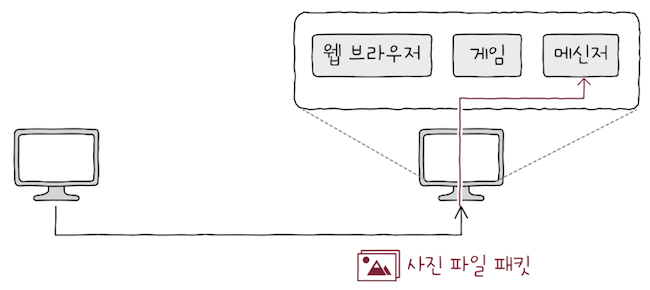
e.g. 네트워크 외부에서 개인이 전송받으려는 사진 파일을 구성하는 패킷들이 라우팅되어 개인 컴퓨터에 도착했다.
- 개인이 컴퓨터로 웹 브라우저, 게임, 메신저 프로그램을 실행하고 있다.
- 그렇다면,
사진 파일 패킷들이 개인 컴퓨터에 도달했으니 수신이 끝난걸까?- 그렇지 않다.
이 패킷들은 웹 브라우저에 전달되고, 게임 혹은 메신저 프로그램에 전달되어야 할 수도 있다. - 즉,
패킷은 실행 중인 특정 애플리케이션 프로세스까지 전달되어야만 한다.
- 그렇지 않다.
패킷을 전송할 떄도 마찬가지다.수신지 호스트의 주소까지 전달했다고 해서 전송이 끝난 것이 아니고,실행 중인 특정 애플리케이션 프로세스까지 전달되어야 한다.- 결국
패킷의 최종 수신 대상은특정 애플리케이션 프로세스다.
💡프로세스란?
프로세스는 실행 중인 프로그램을 의미한다.
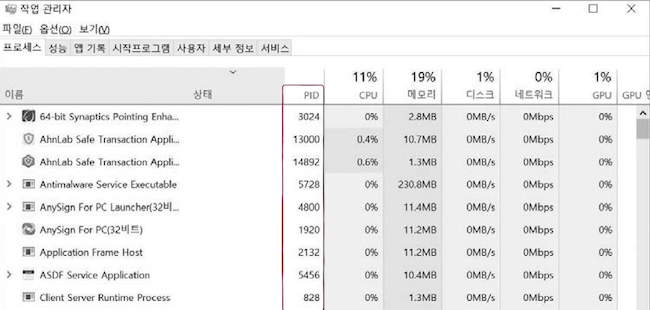
프로그램은 실행되기 전까지는 하드 디스크, USB, SSD 등 보조기억장치에 저장된 데이터 덩어리일 뿐이지만,프로그램이 실행되는 순간프로세스가 되어, 메인 메모리에 적재된다.- 윈도우에서는 [작업 관리자] 창을 통해 실행 중인 프로세스 목록을 볼 수 있다.
- 같은 프로그램일지라도 여러 번 실행하면, 각기 다른 독립적인 프로세스로 실행될 수 있다.
각 프로세스는
PID(Process ID)라는 번호로 식별된다.
PID는 학교의 학번이나 회사의 사번처럼 프로세스의 고유한 식별 정보다.- cf. 윈도우의 [작업 관리자] 창에서 [프로세스] 탭의 왼쪽에 있는 [세부 정보]를 클릭하면,
- 각 프로세스의
PID를 확인할 수 있다.
만약 어떤 패킷을 수신할 애플리케이션에 대한 정보가 패킷에 포함되어 있지 않다면,
- 해당
패킷을 어떤 애플리케이션에 전달해야 할지 알 수 없다. - 즉,
패킷이 실행 중인 특정 애플리케이션까지 전달되려면,패킷에 특정 애플리케이션을 식별할 수 있는 정보가 포함되어야 한다.
- 이런 정보를
포트(port)라고 한다.
1.3.2 포트의 분류
전송 계층에서 포트 번호를 통해 특정 애플리케이션을 식별한다.
- 정확히는 패킷 내
수신지 포트와송신지 포트를 통해 송수신지 호트의 애플리케이션을 식별한다. - cf.
포트혹은포트 번호는 개발하는 과정에서 자주 접하는 용어니 기억해두자.
전송 계층의 핵심 프로토콜인 TCP와 UDP는 모두 포트 번호 필드인 송신지 포트 번호와 수신지 포트 번호를 포함한다.
- 포트 번호는 16비트로 표현 가능하며, 사용 가능한 포트의 수는 (65536)개이다.
- 할당 가능한 포트번호는 0번부터 65535번까지, 총 65536개가 존재한다.
0번부터 65535번까지의 포트 번호는 번호의 범위에 따라 3종류로 나뉜다.
| 포트 종류 | 포트 번호 범위 |
|---|---|
| 잘 알려진 포트 | 0~1023 |
| 등록된 포트 | 1024~49151 |
| 동적 포트 | 49152~65535 |
(1) 잘 알려진 포트(well known port)
0~1023번까지의 포트는 잘 알려진 포트 번호로,
- 영문 그대로
웰 노운 포트라고 지칭하는 경우가 많으며,시스템 포트(system port)라 부르기도 한다. - 이름 그대로 애플리케이션 프로토콜이 일반적으로 사용하는 ‘널리 알려진, 유명한(well known’ 포트 번호를 의미한다.
| 잘 알려진 포트 번호 | 설명 |
|---|---|
| 20, 21 | FTP |
| 22 | SSH |
| 23 | TELNET |
| 53 | DNS |
| 67, 68 | DHCP |
| 80 | HTTP |
| 443 | HTTPS |
(2) 등록된 포트(registered port)
1024~49151번까지는 등록된 포트 번호로,
- 잘 알려진 포트 번호에 비해서는 덜 벌용적이지만, 흔히 사용되는 애플리케이션 프로토콜에 할당하기 위해 사용된다.
- 등록된 포트의 나열햇으나, 암기할 필요는 없다.
| 등록된 포트 번호 | 설명 |
|---|---|
| 1194 | OpenVPN |
| 1433 | Microsoft SQL Server 데이터베이스 |
| 3306 | MySQL 데이터베이스 |
| 6379 | Redis |
| 8080 | HTTP 대체 |
💡 인터넷 할당 번호 관리 기관, IANA
잘 알려진 포트와등록된 포트는 인터넷 할당 번호 관리 기관(IANA; Internet Assigned Numbers Authority)라는 국제 단체에 의해 할당되어 있다.
잘 알려진 포트와등록된 포트의 전체 예시를 보고 싶다면, 다음 링크를 참고하자.- cf. IANA의 포트 번호들
참고로 앞서 포트 번호 예시는 권고일 뿐이며, 강제사항은 아니다.
- e.g. 잘 알려진 포트 번호 80번 포트는 HTTP의 포트로 알려져 있지만,
- 이 번호를 얼마든지 다른 애플리케이션에 할당할 수 있으며, 다른 포트 번호에 HTTP를 할당할 수도 있다.
(3) 동적 포트(dynamic port)
49152~65535번까지는 동적 포트, 사설 포트(private port), 임시 포트(ephemeral port)라고 부른다.
- 인터넷 할당 번호 관리 기관에 의해 할당된 애플리케이션 프로토콜이 없고,
- 특별히 관리되지 않은 포트 번호인 만큼 자유롭게 사용할 수 있다.
서버로서 동작하는 프로그램은 일반적으로 잘 알려진 포트와 등록된 포트로 동작하는 경우가 많다.
- 즉,
서버로서 동작하는 프로그램의 포트 번호는 사전에 암묵적으로 정해진 경우가 많다.
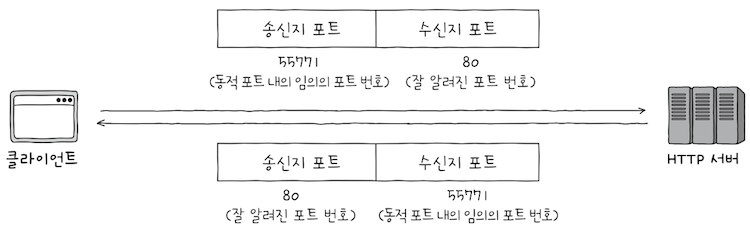
반면에, 클라이언트로서 동작하는 프로그램은 동적 포트 번호 중에서 임의의 번호가 할당되는 경우가 많다.
- 대표적인 예시가
웹 브라우저로, - e.g. 웹 브라우저를 통해 특정 웹 사이트에 접속하는 상황을 가정해보면,
웹 브라우저 프로그램과서버 프로그램이 서로 패킷을 주고받는 것과 같다.- 이떄 웹 브라우저 프로그램에는
동적 포트 내의 임의의 포트 번호가 자동으로 할당된다.
포트 번호를 통해 실행 중인 특정 애플리케이션을 식별할 수 있다고 했다.
- 그렇다면
IP 주소와포트 번호에 대한 정보가 함께 주어지면,특정 호스트에서 실행 중인 특정 애플리케이션 프로세스를 식별할 수 있다.
- 그래서 포트 번호는 일반적으로 다음과 같이
IP주소:포트 번호형식으로 IP 주소와 함께 표기하는 경우가 많다.
1192.168.0.15:80002# 192.168.0.15 ===> IP 주소:호스트 식별3# 8000 ===> 포트번호:애플리케이션 프로세스 식별
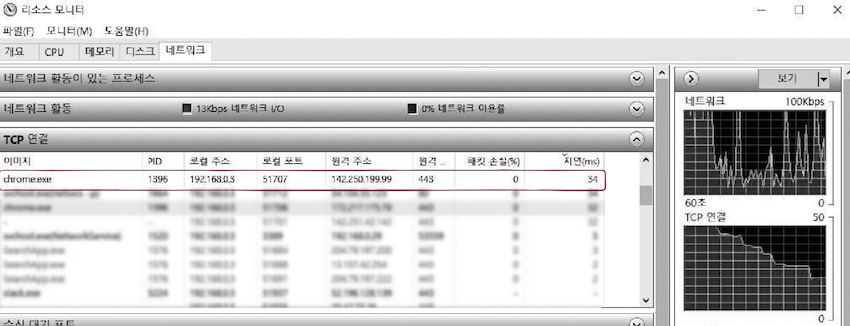
개인 컴퓨터에서 프로세스들의 포트 번호를 직접 확인해보면,
- 윈도우를 사용한다면, [리소스 모니터] 창의 [네트워크] 탭에서 확인할 수 있다.
- [리소스 모니터] 창을 실행해보면, 위 그림과 같은 프로그램이 실행된다.
위 그림을 간략하게 해석해보면, chrome.exe는 크롬 브라우저다.
51707번포트에서 실행되고 있다.- 앞서 클라이언트로서 동작하는 프로그램은 동적 포트 번호 중에서 임의의 번호가 할당되는 경우가 많다.
51707번은 동적 포트에 해당한다고 했다.- 그리고 이 프로그램은
142.250.199.99(구글 서버)의 443번 포트와 통신하고 있다.
443번은 잘 알려진 포트 번호로, HTTPS를 나타낸다.
- 위 화면 속 크롬 브라우저는
142.250.199.99호스트의 HTTPS라는 앱 프로세스와 통신하고 있음을 의미한다. - cf. 맥 OS, 리눅스 운영체제는
netstat명령어를 통해 포트 번호를 확인할 수 있다.
정리해보면, 전송 계층은 신뢰할 수 있는 연결형 통신이 가능한 프로토콜(TCP)을 제공하기에,
네트워크 계층의 한계를 보완할 수 있고,포트를 통해 응용 계층의 애플리케이션을 식별함으로써,응용 계층과의 연결 다리 역할을 수행한다.
1.4 포트 기반 NAT
포트를 학습했다면, 3장에서 학습한 NAT를 자세히 이해할 수 있다.
NAT란 IP 주소를 변환하는 기술이며,- 주로 네트워크 내부에서 사용되는
사설 IP 주소와 - 네트워크 외부에서 사용되는
공인 IP 주소를 변환하는데 사용된다.
- 주로 네트워크 내부에서 사용되는
- 이러한 변환을 위해 주로 사용되는 것이
NAT 변환 테이블이다.
1.4.1 NAT 변환 테이블
| 네트워크 외부 | 네트워크 내부 |
|---|---|
| 1.2.3.4 | 192.168.0.5 |
| 1.2.3.5 | 192.168.0.6 |
| … | … |
NAT 변환 테이블(이하 NAT 테이블)에는 위 표처럼 변환의 대상이 되는 IP 주소 쌍이 명시된다.
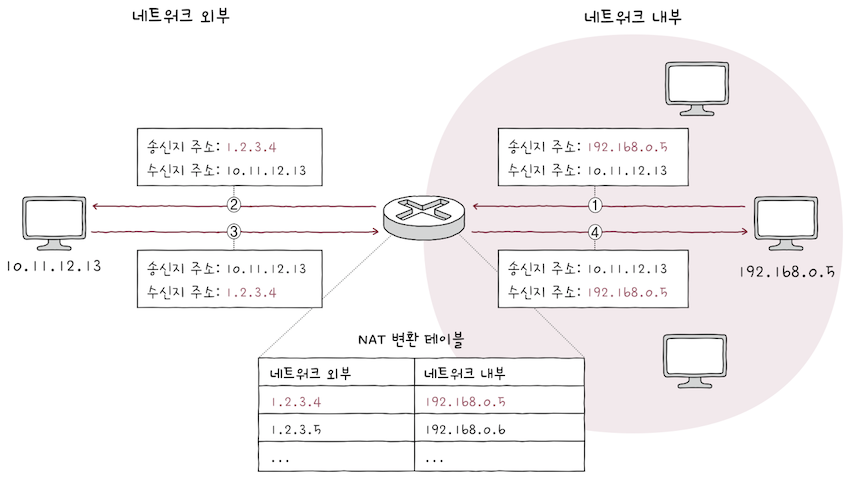
e.g. 위 NAT 테이블을 토대로 보면
- 네트워크 내부에
192.168.0.5라는사설 IP 주소를 가진 호스트가 있고,- 수신지 주소가
10.11.12.13인네트워크 외부의 호스트에게 패킷을 전송한다고 가정해보자.
- 수신지 주소가
패킷이NAT 기능을 갖춘 라우터를 거쳐네트워크 외부로 나가게 되면,- 송신지 주소는
네트워크 외부에서 사용되는 공인 IP 주소인1.2.3.4가 된다.
- 송신지 주소는
반대의 경우도 마찬가지다.
- 수신지 주소가
1.2.3.4인 패킷이 네트워크 외부에서 네트워크 내부로 전송되는 상황일 떄, - 이 패킷의 수신지 주소는
NAT 라우터를 거쳐192.168.0.5가 된다.
그림의 NAT 테이블을 자세히 살펴보면, 변환의 대상이 되는 IP 주소가 일대일로 대응되어 있다.
사설 IP 주소하나당공인 IP 주소하나가 대응된 셈이다.- 이처럼
NAT 테이블의 항목을 일대일로 대응해 NAT를 활용하는 것이 가능하기는 하지만,- 이 방식만으로 많은
사설 IP 주소를 변환하기에는 무리가 있다.
- 이 방식만으로 많은
사설 IP 주소와공인 IP 주소가 일대일로 대응된다면,- 네트워크 내부에서 사용되는
사설 IP 주소의 수만큼공인 IP 주소가 필요하기 때문이다.
- 네트워크 내부에서 사용되는
이러한 이유로 오늘날 대중적으로 활용되는 NAT는 변환하고자 하는 IP 주소를 일대일로 대응하지 않는 경우가 많다.
- “NAT를 통해 사설 IP 주소를 사용하는 여러 호스트는 적은 수의 공인 IP 주소를 공유할 수 있다“라고 배웠다.
- 오늘날
NAT기술은 대부분다수의 사설 IP 주소를 그보다적은 수의 공인 IP 주소로 변환한다.
1.4.2 NAPT
포트 기반의 NAT를 NAPT(Network Address Port Translation)이라 한다.
APT(Address Port Translation)라고 부르기도 한다.NAPT는 포트를 활용해하나의 공인 IP 주소를여러 사설 IP 주소가 공유하도록 하는 NAT의 일종이다.NAPT는 다음 표처럼NAT 테이블에 변환할IP 주소 쌍과 더불어포트 번호도 함께 기록하고, 변환한다.
| 네트워크 외부 | 네트워크 내부 |
|---|---|
| 1.2.3.4:6200 | 192.168.0.5:1025 |
| 1.2.3.4:6201 | 192.168.0.6:1026 |
| … | … |
같은 1, 2, 3, 4라는 공인 IP 주소로 변환되더라도 포트 번호 6200번으로 변화되느냐,
6201번으로 변환되느냐에 따라내부 IP 주소를 구분지을 수 있다.
이처럼 네트워크 외부에서 사용할 IP 주소가 같더라도,
포트 번호가 다르면,네트워크 내부의 호스트를 특정할 수 있기 때문에,다수의 사설 IP 주소를 그보다적은 수의 공인 IP 주소로 변환할 수 있게 된다.
- 즉, NAPT를 이용하면,
- 네트워크
내부에서 사용할 IP 주소와 네트워크외부에서 사용할 IP 주소를N:1로 관리할 수 있다. - 이런 점에서
NAPT는공인 IP 주소수 부족 문제를 개선한 기술로도 간주된다.
- 네트워크
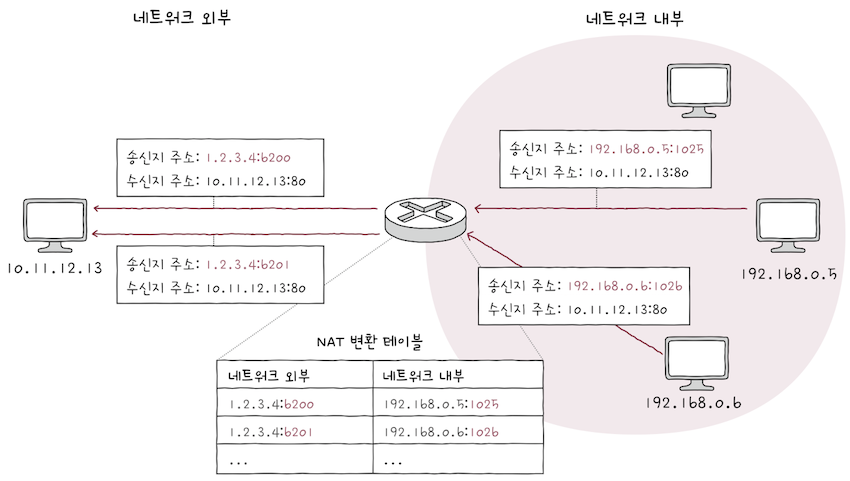
위 그림은 네트워크 내부의 호스트 192.168.0.5, 192.168.0.6이 공인 IP 주소 1.2.3.4를 공유하며,
- 네트워크 외부 호스트
10.11.12.13에게 데이터를 송신하는 예시다. - e.g.
NAPT는NAT 테이블에 변환될IP 주소쌍과 더불어포트 번호도 함께 기록된다.
1.4.3 포트 포워딩
포트 포워딩(port forwarding)이란 네트워크 내 특정 호스트에 IP 주소와 포트 번호를 미리 할당하고,
해당 IP주소:포트번호로써 해당 호스트에게 패킷을 전달하는 기능이다.
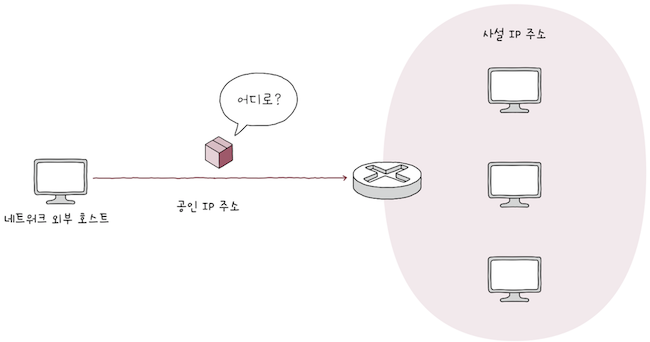
e.g. 네트워크 내부의 여러 호스트가 공인 IP 주소를 공유하는 상황에서, 네트워크 외부에서 내부로 (원격 접속을 시도하는 등) 통신을 시작하는 상황을 가정해보면,
네트워크 외부의 호스트가네트워크 내부의 특정 호스트에게패킷을 전달하고 싶어도,- 네트워크 내에서는
사설 IP 주소들을 사용하고 있고, 여러 호스트가하나의 공인 IP 주소를 공유하고 있다.
- 네트워크 내에서는
- 이런 경우 처음 패킷을 보내는
네트워크 외부 호스트입장에서는어떤 IP 주소(및 포트)를 수신지 주소로 삼을지 결정하기 어려울 수 있다. - 이때 주로 사용되는 것이
포트포워딩이다. 특정 IP 주소와포트 번호쌍을 특정 호스트에게 할당한 뒤,- 외부에서 통신을 시작할 호스트에게 해당
접속 정보(IP주소:포트번호 쌍)을 알려주면 된다.
- 외부에서 통신을 시작할 호스트에게 해당
- 그럼
네트워크 외부 호스트는 그IP 주소:포트 번호로 통신을 시작할 수 있다. - 이처럼
포트포워딩은 주로네트워크 외부에서네트워크 내부로 통신을 시작할 떄,네트워크 내부의 서버를외부에서 접속할 수 있도록, 접속 정보를 공개하기 위해 자주 사용된다.
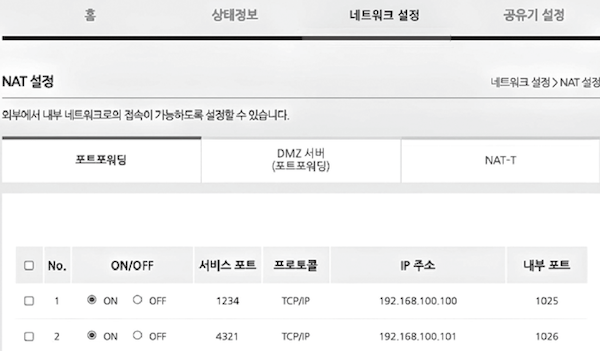
위 화면은 실제 공유기의 포트 포워딩 설정 화면이다.
- 어떤
공인IP 주소:외부 접속 포트(서비스 포트)에 접근했을 떄,- 어떤
사설IP 주소:내부 전달 포트로 전달할지를 설정할 수있다.
- 어떤
- 예컨대. 이 공유기의
공인 IP 주소:1234로 전송한 패킷은192.168.100.100:1025로 전달되는 셈이고,- 공유기의
공인 IP 주소:4321로 전송한 패킷은192.168.100.101:1026으로 전달되는 셈이다.
- 공유기의
1.4.4 ICMP
IP의 신뢰할 수 없는 전송 특성과 비연결형 전송 특성을 보완하기 위한 네트워크 계층의 프로토콜로 ICMP가 있다.
ICMP(Internet Control Message Protocol)는 IP 패킷의 전송 과정에 대한피드백 메시지(이하 ICMP 메시지)를 얻기 위해 사용하는 프로토콜이다.- ICMP 메시지의 종류로는 크게
(1) 전송 과정에서 발생한 문제 상황에 대한 오류 보고와(2) 네트워크에 대한 진단 정보(네트워크 상의 정보 제공)가 있다.
ICMP 메시지는 타입과 코드로 정의된다.
타입과코드는 ICMP 패킷 헤더에 포함되어 있는 정보이다.- ICMP 패킷 헤더의
타입(type) 필드에는 ICMP 메시지의 유형이 번호로 명시되고, 코드(code) 필드에는 구체적인 메시지 내용이 번호로 명시된다.
cf. ICMP는 IPv4에 사용되는 ICMPv4와 IPv6에 사용되는 ICMPv6가 있다. 다음 내용은 ICMPv4에 대한 정보다.
오류 보고를 위한 대표적인 ICMP 메시지 타입으로는 수신지 도달 불가와 시간 초과가 있다.
다음 표는 두 타입에 대한 일부 코드이다.
| 타입 이름(타입 번호) | 코드 번호 | 코드 설명 |
|---|---|---|
| 수신지 도달 불가(3) : 특정 패킷이 수신지까지 도달할 수 없음을 나타냄 | 0 | 네트워크 도달 불가 |
| 1 | 호스트 도달 불가 | |
| 2 | 프로토콜 도달 불가 : 수신지에서 특정 프로토콜을 사용할 수 없음 | |
| 3 | 포트 도달 불가 | |
| 4 | 단편화가 필요하지만 DF가 1로 설정되어 단편화할 수 없음 | |
| 시간 초과(11) | 0 | TTL 만료 |
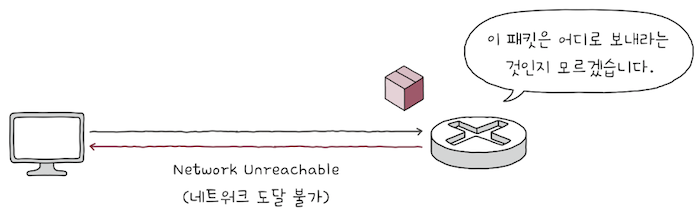
e.g. 라우터에게 전달된 패킷의 TTL 필드가 0이 되면,
- 해당
라우터는송신지 호스트에게 [시간 초과 타입 - TTL 만료 코드]ICMP 패킷을 전송하게 된다. - 또한
패킷을 전달받은 라우터가 수신지 네트워크로 향하는 경로를 찾을 수 없을 떄는- [수신지 도달 불가 타입 - 네트워크 도달 불가 코드]
ICMP 패킷을 전송한다.
- [수신지 도달 불가 타입 - 네트워크 도달 불가 코드]
다음 표는 네트워크 상의 정보 제공을 위한 대표적인 ICMP 메시지다.
| 타입 이름(타입 번호) | 코드 번호 | 코드 설명 |
|---|---|---|
| 에코 요청(8) | 0 | 에코 요청 |
| 에코 응답(0) | 0 | 에코 요청에 대한 응답 |
| 라우터 광고(9) | 0 | 라우터 광고: 라우터가 호스트에게 자신을 알림 |
이런 메시지들은 네트워크 상의 간단한 문제 진단 및 테스트를 위해 사용되기도 한다.
- 경로를 확인해 보고자 사용했던
traceroute또는tracert명령어를 배웠다. - 이 명령어는 사실
ICMP 메시지를 기반으로 동작하는 명령어다.
또한 ping이라는 명령어가 있는데,
ping은 네트워크의 상태를 진단하는 가장 기본적인 명령어로, 이 또한 대표적인ICMP 기반의 명령어다.- 정확히는 ICMP의
에코 요청(echo request),에코 응답(echo reply)메시지를 기반으로 구현된다.
주의할 점이 한 가지 있는데, 바로 ICMP가 IP의 신뢰성을 보장하는 것은 아니다라는 점이다.
ICMP는 어디까지나 IP의 신뢰할 수 없는 특성을 보완하기 위한 ‘도우미’ 역할만을 할 뿐,- 여전히
IP 패킷은 수신지까지 도달하지 못하거나, ICMP 메시지를 담은 패킷자체가 송신지까지 되돌아오지 못할 수 있다.
- 여전히
- 신뢰성을 완전히 보장하기 위해서는 앞서 배운 전송 계층의 프로토콜이 필요하다.
- 다음의 공식 문서(RFC 792)에게도 이를 명확하게 명시하고 있다.
💡 RFC 792
The Internet Protocol is not designed to be absolutely reliable. The purpose of these control messages is to provide feedback about problems in the communication environment, not to make IP reliable.
- ICMP 메시지는 IP의 신뢰성을 보장하기 위한 것이 아니다.
- cf. https://datatracker.ietf.org/doc/html/rfc792
2. TCP와 UDP
네트워크 계층에서 가장 중요한 프로토콜이 IP라면, 전송 계층에서 가장 중요한 프로토콜은 TCP와 UDP이다.
TCP(Transmission Control Protocol): 신뢰할 수 있는 통신을 위한 연결형 프로토콜UDP(User Datagram Protocol): TCP보다 신뢰성은 떨어지지만, 비교적 빠른 통신이 가능한 비연결형 프로토콜
이번 절에 배울 TCP와 UDP는 모두 중요하지만, 실제 학습할 내용은 TCP가 더 많다.
- 통신을 시작하고 끝맺는 과정(연결 수립과 종료 과정)이 있고,
- 오류 제어를 위한 재전송, 흐름 제어, 혼잡 제어 등의 관련 기능들이 많기 때문이다.
2.1 TCP 통신 단계와 세그먼트 구조
TCP 통신을 크게 3단계로 나뉘면, 다음 그림과 같이 나눌 수 있다.

TCP는 통신(데이터 송수신)하기 전에 연결을 수립하고, 통신이 끝나면 연결을 종료한다.
- 그리고 데이터 송수신 과정에서 재전송을 통한 오류 제어, 흐름 제어, 혼잡 제어 등의 기능을 제공한다.
- 이번 절에서는 연결형 프로토콜이란 TCP의 특징을 이해하도록 (1) 연결 수립, (3) 연결 종료를 살펴본다.
- (2) 데이터 송수신은 4장-3절에서 배운다.
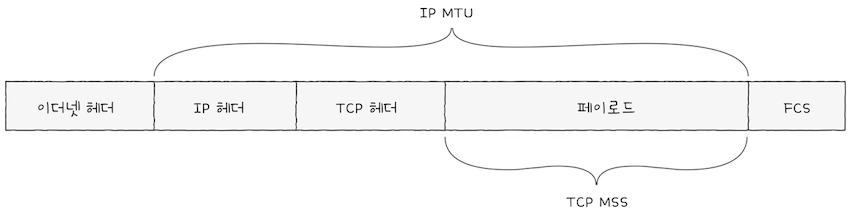
TCP의 연결 수립과 종료를 이해하려면, 가장 먼저 MSS라는 단위와 TCP의 세그먼트 구조를 이해해야 한다.
MSS(Maximum Segment Size)는 TCP로 전송할 수 있는 최대 페이로드 크기를 의미한다.MSS의 크기를 고려할 떄,TCP 헤더 크기는 제외한다.헤더의 크기까지 포함했던 단위인MTU와는 대조적이다.
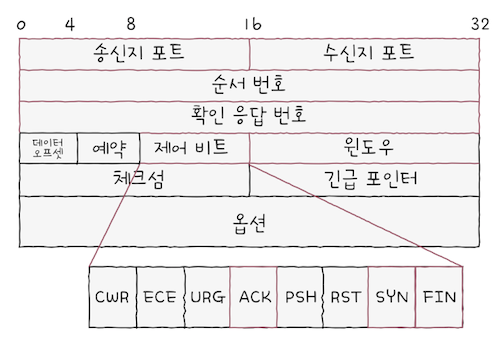
TCP 세그먼트 구조를 보면 복잡하다 느낄 수도 있지만, 모든 필드를 보기 보다는 TCP의 기본 동작을 이해하기 위한 기본적인 필드들을 기준으로 살펴본다. 우선 붉은 테두리로 강조표시된 필드와 각 의미를 쭉 읽어보자.
송수신지 포트(source port)와수신지 포트(destination port):- 필드 이름 그대로 송신지 또는 수신지 애플리케이션을 식별하는 포트 번호가 명시되는 필드
순서 번호(sequence number): 순서 번호가 명시되는 필드순서 번호란 송수신되는 세그먼트의 올바른 순서를 보장하기 위해, 세그먼트 데이터의 첫 바이트에 부여되는 번호
확인 응답 번호(acknowledgment number): 상대 호스트가 보낸 세그먼트에 대한 응답으로,- 다음으로 수신하기를 기대하는 순서 번호가 명시된다.
제어 비트(control bits): 현재 세그먼트에 대한 부가 정보를 나타낸다.- cf.
플래그 비트(flag bit)라고도 부른다.
- cf.
윈도우(window): 수신 윈도우의 크기가 명시된다.수신 윈도우란 한 번에 수신하고자 하는 데이터의 양을 나타낸다.
이 필드 중에서 송신지 포트와 수신지 포트 필드는 앞선 절에 학습한 적이 있기에 이해가 어렵지 않을 것이다.
- 그리고
윈도우 필드는 다음 절에서 다음 절에 다룬다. - 이번 절에 기억해야 할 필드는
순서 번호필드와확인 응답 번호필드, 그리고관련 제어 비트(ACK, SYN , FIN)다.
2.1.1 제어 비트
순서 번호 필드와 확인 응답 번호 필드를 학습하려면, 먼저 제어 비트 필드에 대한 이해가 필요하다.
- 제어 비트 필드는 기본적으로 8비트로 구성된다.
- 각 자리의 비트는 각기 다른 의미를 가지는데,
- TCP의 기본 동작을 논할 떄, 가장 자주 언급되는 3개의 제어 비트는 다음과 같다.
ACK: 세그먼트의 승인을 나타내기 위한 비트SYN: 연결을 수립하기 위한 비트FIN: 연결을 종료하기 위한 비트
- cf.
ACK 비트가 1로 설정된 비트,SYN 비트가 1로 설정된 세그먼트,FIN 비트가 1로 설정된 세그먼트는- 각각
ACK 세그먼트,SYN 세그먼트,FIN 세그먼트라 줄여서 부르는 경우가 많다. - 그래서 여기서도 줄여서 표기한다.
- 각각
2.1.2 순서 번호와 확인 응답 번호
순서 번호 필드와 확인 응답 번호 필드는 TCP의 신뢰성을 보장하기 위해 사용되는 중요한 필드로, 한 쌍으로 묶어서 기억하는 것이 좋다.
- 이 두 필드에는 각각
순서 번호와확인 응답 번호가 명시된다. - cf.
순서 번호는 영문 표기 그대로시퀀스 넘버(sequence number),- 확인 응답 번호는 영문을 줄인
ACK 넘버(acknowledgment number)라고 표현하는 경우도 많다.
- 확인 응답 번호는 영문을 줄인
순서 번호 필드에 명시되는 순서 번호는 세그먼트의 올바른 송수신 순서를 보장하기 위한 번호로,
세그먼트 데이터의 첫 바이트에 부여되는 번호다.
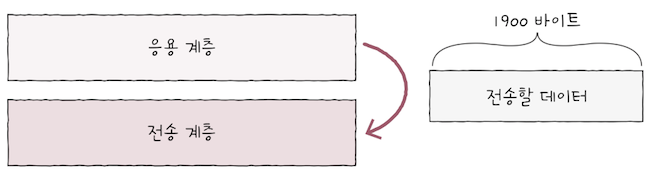
e.g. 위 그림처럼 전송 계층이 응용 계층으로부터 전송해야 할 1900바이트 크기의 데이터를 전달받는다 가정하면,
- 이는
MSS단위로 전송될 수 있다.
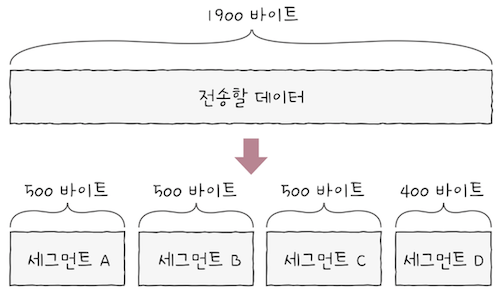
편의상 MSS가 500바이트라 가정하면,
1900바이트짜리 데이터 덩어리를MSS단위로 쪼개면,4개의 세그먼트로 쪼갤 수 있다.- 위 그림처럼 세그먼트 A, B, C, D순으로 전송된다고 가정해보자.
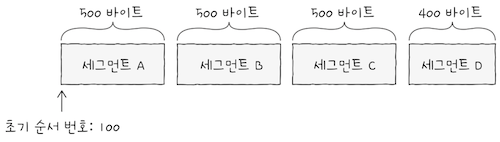
처음 통신을 위해 연결을 수립한 경우, 즉 제어 비트에서 연결을 수립하기 위한 SYN 플래그가 1로 설정된 세그먼트인 경우
순서 번호는 무작위 값이 된다.- 이를
초기 순서 번호(ISN; Initial Sequence Number)라고 한다. 초기 순서 번호가100이라면, 가장 먼저 보내게 될세그먼트 A의 순서 번호가초기 순서 번호인 100이 된다.
연결 수립 이후 데이터를 송신하는 동안, 순서 번호는 송신한 바이트를 더해가는 형태로 누적값을 가진다.
- 즉,
순서 번호는초기 순서 번호 + 송신한 바이트 수가 된다. - 쉽게 말해,
초기 순서 번호 + 떨어진 바이트 수라고 생각하면 된다. - cf.
순서 번호는 세그먼트 상에서 32비트(4바이트)로 표현된다.- 만약
순서 번호가 이 비트 수로 표현 가능한 수를 넘어서면, 0부터 다시 증가한다.
- 만약
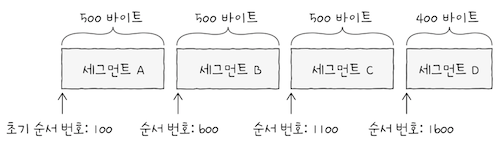
그렇다면 세그먼트 B의 순서 번호는 초기 순서 번호인 100에서 500바이트로 떨어진 600이 된다.
- 마찬가지로,
세그먼트 C의 순서 번호는 초기 순서 번호로부터 1000바이트 떨어진1100이 되고, 세그먼트 D의 순서 번호는 초기 순서 번호로부터 1500바이트 떨어진1600이 된다.- cf.
순서 번호는 TCP 세그먼트의 순서를 나타내기 위한 정보다.
확인 응답 번호 필드에 명시되는 확인 응답 번호는 순서 번호에 대한 응답이다.
- ‘다음에는 이걸 보내주세요’, ‘다음으로 제가 받을 순서번호는 이것이다’를 나타내는 값이다.
- 즉,
확인 응답 번호는 수신자가 다음으로 받기를 기대하는 순서 번호다. - 일반적으로
수신한 번호 + 1로 설정한다.
확인 응답 번호 값을 보내기 위해서는 제어 비트에서 승인을 나타내는 비트인 ACK 플래그를 1로 설정해야 한다.
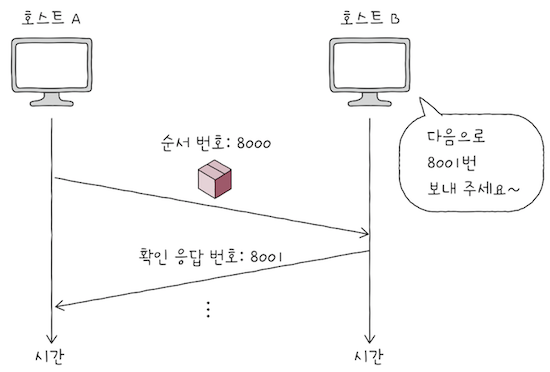
- e.g. 위 그림처럼
순서 번호가8000인 세그먼트를 잘 수신한 뒤,- 다음으로
8001번 세그먼트를 받기를 원한다고 가정하면, 해당 호스트는ACK 플래그를 1로 설정하고확인 응답 번호로 8001을 명시한 세그먼트를 전송한다.
- 다음으로
여기까지 배웠으면 이제 TCP의 (1)연결 수립, (3) 연결 종료에 배운다. (2) 데이터 송수신은 앞에 애기한대로 4장 3절에서 배운다.
2.2 TCP 연결 수립과 종료
TCP는 통신 이전에는 연결을 수립하고, 통신 이후에는 연결을 종료한다. TCP의 연결 수립 과정에 대해 알아보자.
2.2.1 연결 수립: 3-way 핸드셰이크
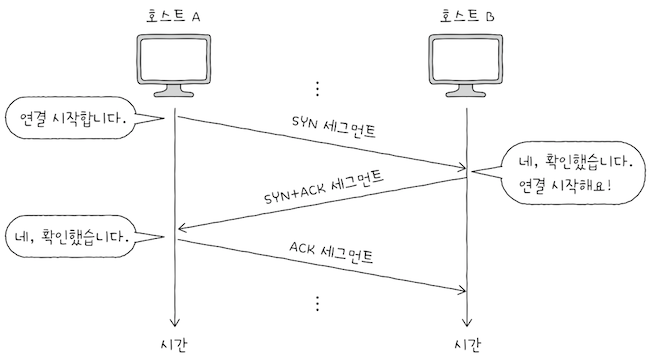
TCP의 연결 수립은 쓰리 웨이 핸드셰이크를 통해 이루어진다.
쓰레 웨이 핸드셰이크(three-way handshake)는 이름처럼3단계로 이루어진 TCP의 연결 수립 과정을 의미한다.- e.g. 호스트 A와 B가 3-way 핸드셰이크를 한다고 가정하면,
- 위 그림처럼 3단계를 거친 뒤, 본격적인 송수신이 시작된다.
| 송수신 방향 | 세그먼트 | 세그먼트에 포함된 주요 정보 | 비유 |
|---|---|---|---|
| A → B | SYN | - 호스트 A의 초기 순서 번호 - 1로 설정된 SYN 비트 | 연결 시작 |
| B → A | SYN + ACK | - 호스트 B의 초기 순서 번호 - 호스트 A가 전송한 세그먼트에 대한 확인 응답 번호 - 1로 설정된 SYN 비트 - 1로 설정된 ACK 비트 | 확인, 연결하셈 |
| A → B | ACK | - 호스트 A의 다음 순서 번호 - 호스트 B가 전송한 세그먼트에 대한 확인 응답 번호 - 1로 설정된 ACK 비트 | 확인 |
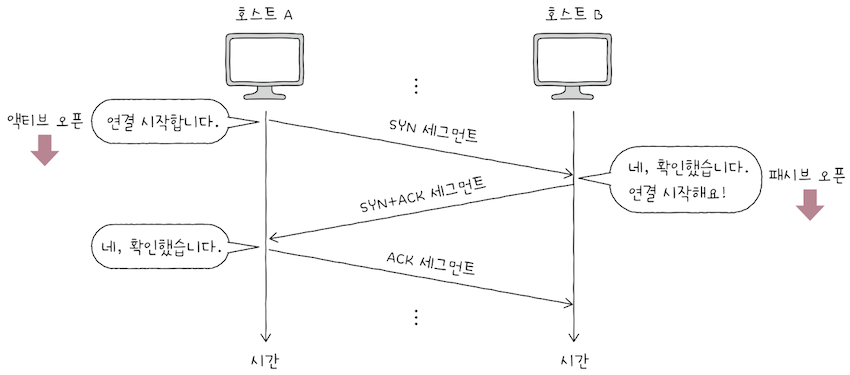
이떄 처음 연결을 시작하는 호스트의 연결 수립 과정을 액티브 오픈(active open)이라 한다.
- cf. 연결을 처음 요청하는 측의 동작을
액티프 오픈이라 생각해도 된다. 액티브 오픈은 주로서버-클라이언트관계에서 클라이언트에 수행된다.- 위 예시에서
호스트 A의 동작이액티브 오픈이라 할 수 있다.
반대로, 연결 요청을 받고 나서 요청에 따라 연결을 수립해주는 호스트도 있다.
- 이 호스트의 연결 수립 과정을
패시브 오픈(passive open)이라 한다. - 주로 서버에 의해 수행되며, 위의 예시에는
호스트 B의 동작이패시브 오픈이다.
2.2.2 연결 종료 : 4-way 핸드셰이크
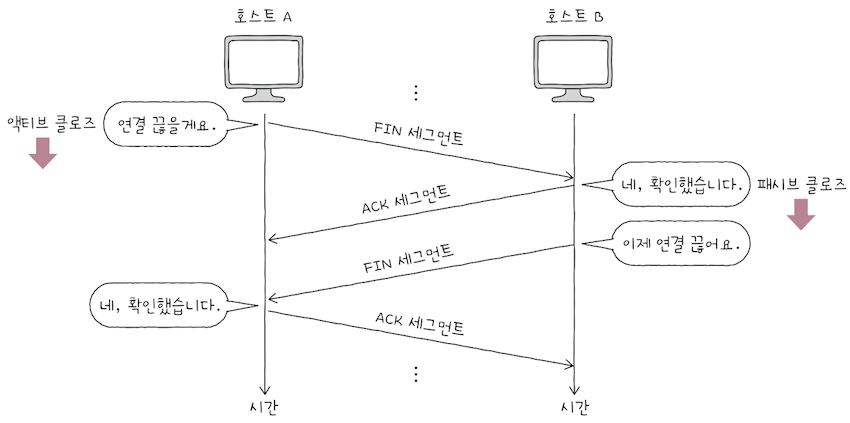
3-way 핸드셰이크를 통해 연결을 수립한 뒤 데이터 송수신이 끝났다면, 이제 연결을 종료해야 한다.
TCP가 연결을 종료하는 과정은 송수신 호스트가 각자 한 번씩FIN과ACK를 주고받으며 이루어진다.호스트 A와 B가 연결을 종료하는 각 단계를 설명하면 위 그림과 같다.
| 송수신 방향 | 세그먼트 | 세그먼트에 포함된 주요 정보 | 비유 |
|---|---|---|---|
| A → B | FIN | 1로 설정된 SYN 비트 | 연결 끊을거임 |
| B → A | ACK | - 호스트 A가 전송한 세그먼트에 대한 확인 응답 번호 - 1로 설정된 ACK 비트 | 네, 확인함 |
| B → A | FIN | 1로 설정된 FIN 비트 | 이제 연결끊는다 |
| A → B | ACK | - 호스트 B가 전송한 세그먼트에 대한 확인 응답 번호 - 1로 설정된 ACK 비트 | 네, 확인 |
💡 4단계로 연결을 종료한다는 점에서
포 웨이 핸드셰이크(four-way handshake)라고 부른다.
연결을 수립할 떄 액티브 오픈, 패시브 오픈이 있는 것처럼,
연결을 종료하는 과정에도 액티브 클로즈, 패시브 클로즈가 있다.
액티브 클로즈(active close): 먼저 연결을 종료하는 호스트에 의해 수행된다.- 위 예시에는
FIN 세그먼트를 먼저 보낸호스트 A가 액티브 클로즈를 수행한다.
- 위 예시에는
패시브 클로즈(passive close): 연결 종료 요청을 받아들이는 호스트에 의해 수행된다.- 위 예시에는
호스트 B의 동작이 패시브 클로즈다.
- 위 예시에는
2.3 TCP 상태
TCP는 연결형 통신과 신뢰할 수 있는 통신을 유지하기 위해 다양한 상태를 유지한다.
상태(state)는 현재 어떤 통신 과정에 있는지를 나타내는 정보다.TCP는 상태를 유지하고 활용한다는 점에서스테이트풀(stateful) 프로토콜이라 부른다.
다음은 TCP의 상태가 있는 표다.
| 상태 분류 | 주요 상태 |
|---|---|
| 연결이 수립되지 않은 상태 | CLOSED, LISTEN |
| 연결 수립 과정에서 주로 볼 수 있는 상태 | SYN-SENT, SYN-RECEIVED, ESTABLISHED |
| 연결 종료 과정에서 주로 볼 수 있는 상태 | FIN-WAIT-1, CLOSE-WAIT, FIN-WAIT-2, LAST-ACK, TIME-WAIT, CLOSING |
2.3.1 연결이 수립되지 않은 상태
아직 연결 수립이 이루어지기 전의 호스트는 주로 CLOSED나 LISTEN 상태를 유지한다.
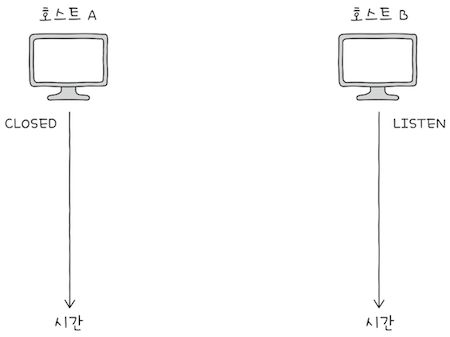
CLOSED: 아무런 연결이 없는 상태다.LISTEN: 일종의 연결 대기 상태다.- 일반적으로 서버로서 동작하는
패시브 오픈 호스트는LISTEN 상태를 유지한다. 쓰리 웨이 핸드셰이크의 첫 단계는액티브 오픈 호스트의 연결 요청인SYN 세그먼트다.LISTEN 상태는 그SYN 세그먼트를 기다리는 상태다.- 즉,
액티브 오픈 호스트(일반적으로 클라이언트)가LISTEN 상태인 호스트(일반적으로 서버)에게SYN 세그먼트를 보내면,쓰리 웨이 핸드셰이크가 시작된다.
- 일반적으로 서버로서 동작하는
2.3.2 연결 수립 상태
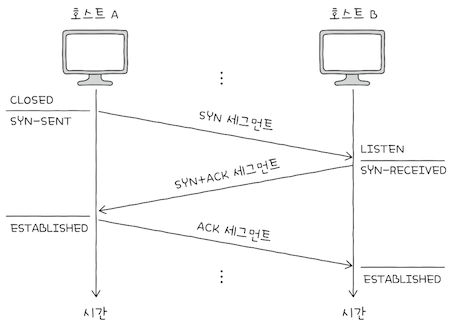
TCP 연결 수립 과정에서는 주로 SYN-SENT, SYN-RECEIVED, ESTABLISHED 상태를 볼 수 있다. 쓰리 웨이 핸드셰이크가 진행되는 과정에서 어떤 상태를 거치는지 위 그림과 같이 보자.
SYN-SENT:액티브 오픈 호스트가SYN 세그먼트를 보낸 뒤, 그에 대한 응답인SYN + ACK 세그먼트를 기다리는 상태다.- 연결 요청을 보낸 뒤 대기하는 상태라 봐도 좋다.
SYN-RECEIVED:패시브 오픈 호스트가SYN + ACK 세그먼트를 보낸 뒤,- 그에 대한
ACK 세그먼트를 기다리는 상태다.
ESTABLISHED:- 연결이 확립되었음을 나타내는 상태다.
- 데이터를 송수신할 수 있는 상태를 의미한다.
- 3-way 핸드셰이크 과정에서 두 호스트가
마지막 ACK 세그먼트를 주고받으면,ESTABLISHED 상태로 접어든다.
2.3.2 연결 종료 상태
TCP 연결을 종료하는 과정에는 주로 FIN-WAIT-1, CLOSE-WAIT, FIN-WAIT-2, LAST-ACK, TIME-WAIT, CLOSED 상태를 볼 수 있다.
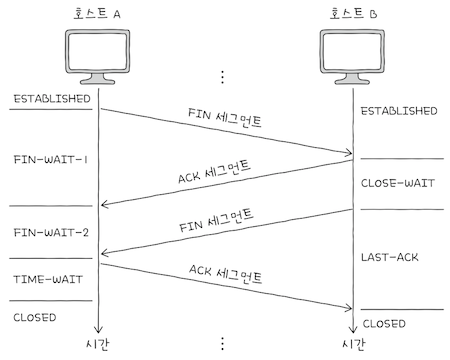
FIN-WAIT-1: 일반적인 TCP 연결 종료 과정에 있어FIN-WAIT-1은 연결 종료의 첫 단계가 된다.FIN 세그먼트로서 연결 종료 요청을 보낸액티브 클로즈 호스트는FIN-WAIT-1상태로 접어들게 된다.
CLOSED-WAIT: 종료 요청인FIN 세그먼트를 받은패시브 클로즈 호스트가- 그에 대한 응답으로
ACK 세그먼트를 보낸 후 대기하는 상태다.
- 그에 대한 응답으로
FIN-WAIT-2: FIN-WAIT-1 상태에서ACK 세그먼트를 받게되면,FIN-WAIT-2상태가 된다.상대 호스트의FIN 세그먼트를 기다리는 상태다.
LAST-ACK: CLOSE-WAIT 상태에서FIN 세그먼트를 전송한 뒤,- 이에 대한
ACK 세그먼트를 기다리는 상태다.
- 이에 대한
TIME-WAIT: 액티브 클로즈 호스트가FIN 세그먼트를 수신한 뒤,- 이에 대한
ACK 세그먼트를 전송한 뒤 접어드는 상태다. 패시브 클로즈 호스트가마지막 ACK 세그먼트를 수신하면CLOSED 상태로 전이하는 반면,TIME-WAIT상태에 접어든액티브 클로즈 호스트는 일정 시간을 기다린 뒤CLOSED 상태로 전이한다.
- 이에 대한
💡TIME-WAIT 상태가 필요한 이유는 무엇인가?
TIME-WAIT 상태에 접어든 액티브 클로즈 호스트는 일정 시간을 기다린 뒤,
CLOSED상태로 전이한다.
- 그런데 TIME-WAIT 상태는 왜 필요할까?
- 왜 굳이 일정 시간을 기다렸다 연결을 종료할까?
가장 주요한 이유는 상대 호스트가 받았어야 할
마지막 ACK 세그먼트가 올바르게 전송되지 않을 수 있기 떄문이다.
- 다음 절에서 학습할 예정이지만, TCP 송수신 과정에는 세그먼트가 올바르게 전송되지 않았다면,
- 해당 세그먼트를 재전송해야 한다.
- 만약
TIME-WAIT상태로 일정 시간 대기하지 않고,
- 곧바로 연결을 종료해버리면,
상대 호스트입장에서는마지막 ACK 세그먼트를 재전송받을 수 없다.- 또 다른 이유로, 한 연결을 종료하고 다른 연결을 수립하는 과정 사이에 대기 시간이 없다면,
서로 다른 연결의 패킷들이 혼란을 야기할 수 있다.
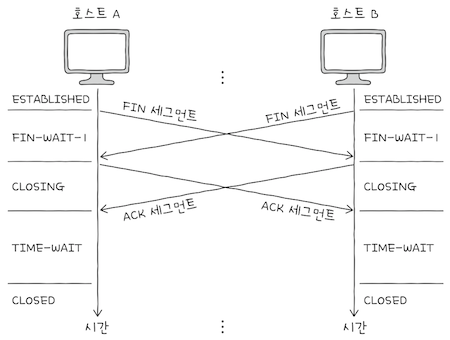
참고로, CLOSING 상태는 보통 동시에 연결을 종료하려 할 떄 전이되는 상태다.
- 서로가
FIN 세그먼트를 보내고 받은 뒤, 각자 그에 대한ACK 세그먼트를 보냈지만,- 아직
자신의 FIN 세그먼트에 대한ACK 세그먼트를 받지 못했을 떄 접어드는 상태다.
- 아직
- 양쪽 모두가 연결 종료를 요청하고, 서로의 종료 응답을 기다리는 경우
CLOSING상태로 접어드는 셈이다. - 이 경우
ACK 세그먼트를 수신한다면, 각자TIME-WAIT 상태로 접어든 뒤 종료한다.
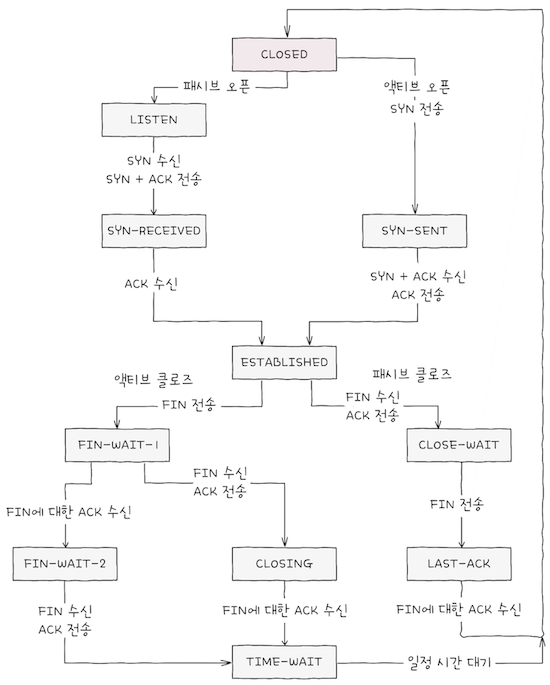
지금까지 설명한 TCP 상태를 종합하면 위 그림과 같다.
TCP는 이런 상태를 전이하며, 연결을 수립하고, 송수신하며, 연결을 종료한다.
TCP의 다양한 상태는 간단한 명령어로 확인할 수 있다. 대표적인 명령어로 netstat가 있다.
맥OS나 리눅스 운영체제 사용자는 터미널을 열고 netstat을 입력해보세요.
1$ netstat2Active Internet connections (inclouding servers)3Proto Recv-Q Send-Q Local Address Foreign Address (state)4tcp4 0 0 10.11.12.13.53625 123.123.123.123.https ESTABLISHED5tcp4 0 0 10.11.12.13.53624 123.123.123.124.https ESTABLISHED6tcp4 0 0 10.11.12.13.100.53623 123.123.123.125.https ESTABLISHED7tcp4 0 0 10.11.12.13.53622 123.123.123.126.https ESTABLISHED8tcp4 0 0 10.11.12.13.50102 123.123.123.127.https TIME_WAIT9tcp4 0 0 10.11.12.13.50104 123.123.123.128.https TIME_WAIT10tcp4 0 0 10.11.12.13.50105 123.123.123.129.https TIME_WAIT11tcp4 0 0 10.11.12.13.57974 123.123.123.130.443 ESTABLISHED12tcp4 0 0 localhost.16107 *.* LISTEN13...
2.4 UDP 데이터그램 구조
UDP는 TCP와 달리 비연결형 통신을 수행하는 신뢰할 수 없는 프로토콜이다.
- 그래서 연결 수립 및 해제, 재전송을 통한 오류 제어, 혼잡 제어, 흐름 제어 등을 수행하지 않는다.
TCP처럼 상태를 유지하지도 않는다.- 상태를 유지하지도, 활용하지도 않는다는 점에서
UDP를스테이트리스(stateless)프로토콜의 일종이다.
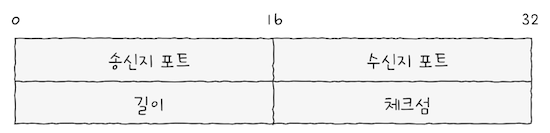
UDP 데이터그램의 구조를 보면, TCP에 비해 제공하는 기능이 적은 만큼 필드도 단순하다.
UDP 데이터그램 헤더는 위 그림과 같이 송신지 포트와 수신지 포트, 길이, 체크섬 필드의 4개의 필드로 구성된다.
송신지 포트와수신지 포트: 송수신지의 포트 번호가 담겨있다.길이: 헤더를 포함한 UDP 데이터그램의 바이트가 담겨있다.체크섬: 데이터그램 전송 과정에서 오류 발생했는지 검사하기 위한 필드다.- 수신지는 이 필드의 값을 토대로 데이터그램의 정보가 훼손되었는지를 판단하고,
- 문제가 있다고 판단한 데이터그램은 폐기한다.
- cf. 데이터그램이 훼손되었는지를 나타내는 정보라는 점에서
- 이 필드는 ‘수신지까지 잘 도달했는지’를 나타내는
신뢰성/비신뢰성과는 관련없다.
- 이 필드는 ‘수신지까지 잘 도달했는지’를 나타내는
- 수신지는 이 필드의 값을 토대로 데이터그램의 정보가 훼손되었는지를 판단하고,
UDP는 TCP에 비해 적은 오버헤드로 패킷을 빠르게 처리할 수 있다.
- 그래서 주로
실시간 스트리밍 서비스,인터넷 전화처럼 실시간성이 강조되는 상황에서TCP보다 더 많이 쓰인다.
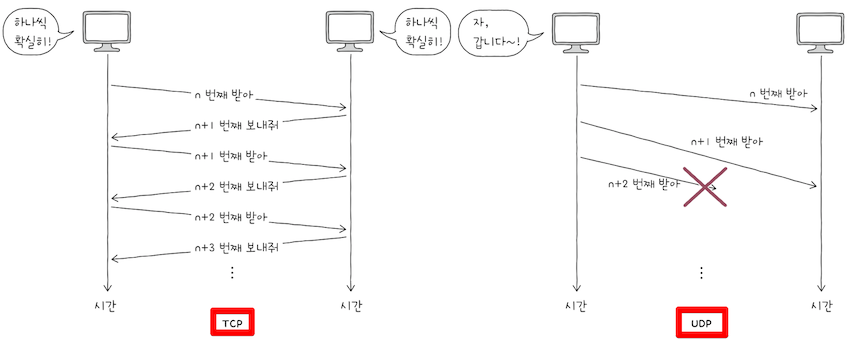
위 그림은 TCP와 UDP의 차이를 보여주는 그림이다.
TCP의 전송 방식이 수신지에 ‘하나씩 확실하게 전달하는’ 것과 같다면,UDP의 전송 방식은 수신지에 패킷들을 ‘빠르게 마구 던지는’ 것과 같다.- 그 과정에서 패킷이 손실되거나 패킷의 순서가 바뀔 수 있다는 점에 주의하자.
3. TCP의 오류·흐름·혼잡 제어

앞의 절에서 TCP의 연결 수립과 종료과정을 배웠고, 이번에는 그 중간 과정인, 데이터 송수신 과정에서의 오류 제어, 흐름 제어, 혼잡 제어 기법을 배운다.
- 오류 제어, 흐름 제어, 혼잡 제어는 모두 TCP의 신뢰성을 보장하기 위한 기능이다.
TCP는 재전송을 기반으로 다양한오류를 제어하고,흐름 제어를 통해 처리할 수 있을 만큼의 데이터만을 주고받으며,혼잡 제어를 통해 네트워크가 혼잡한 정도에 따라 전송량을 조절한다.
3.1 오류 제어: 재전송 기법
신뢰성을 보장하기 위해 오류를 제어할 수 있어야 한다.
- 이를 위해
TCP는 잘못된 세그먼트를 재전송하는 방법을 사용한다. TCP의재전송 기반 오류 제어가 어떻게 이루어지는지 알아보자.
3.1.1 오류 검출과 재전송
TCP 세그먼트에 오류 검출을 위한 체크섬 필드가 있다고는 하지만, 이것만으로 신뢰성을 보장하기는 부족하다.
체크섬은세그먼트의 훼손 여부만 나타낼 뿐이고,체크섬값이 잘못되었다면,호스트는 해당 패킷을 읽지 않고 폐기하기 때문이다.
- 결국
체크섬을 이용한다고 해도,송신 호스트가세그먼트전송 과정에 문제가 있다는 것을 인지할 수는 없다.
TCP가 신뢰성을 제대로 보장하려면 다음 두 조건을 만족해야 한다.
송신 호스트가세그먼트에 문제가 발생했음을 인지할 수 있어야 한다.- 오류를 감지하면(세그먼트가 잘못 전송되었음을 알게되면), 해당
세그먼트를 재전송할 수 있어야 한다.
그렇다면 가장 먼저 파악해야 할 점은 ‘TCP가 어떤 상황에서 송신한 세그먼트에 문제가 있음을 감지하느냐’이다.
TCP가 오류를 검출하고 세그먼트를 재전송하는 상황에 크게 2가지가 있다.
- 중복된 ACK 세그먼트를 수신했을 떄
- 타임아웃이 발생했을 떄
(1) 중복된 ACK 세그먼트를 수신했을 떄
TCP는 중복된 ACK 세그먼트를 수신했을 떄 오류가 생겼음을 감지한다. 중복된 ACK 세그먼트를 수신했을 떄는 어떤 상황일까?
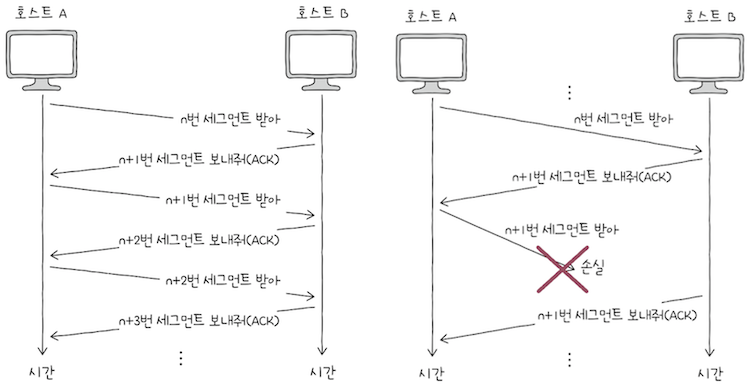
e.g. 호스트 A와 B가 올바르게 세그먼트를 주고받는다면,
A는 첫 순서 번호를 담은 세그먼트를 보내고,- 그에 대한
ACK 세그먼트를 받은 뒤, 다음 순서 번호를 담은세그먼트를 보내고, - 그에 대한
ACK 세그먼트를 받는 것을 반복한다.
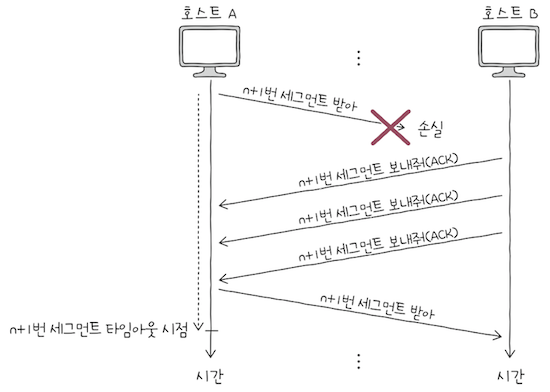
만약 위 상황에서 수신 호스트 측이 받은 세그먼트의 순서 번호 중에서 일부가 누락되면, 중복된 ACK 세그먼트를 전송한다.
- 위 그림의 오른쪽을 살펴보면,
호스트 A의n+1번 세그먼트가 잘못 전송되었고, - 그에 따라
호스트 B가n+1번 ACK 세그먼트를 반복해서 전송한 것을 볼 수 있다.
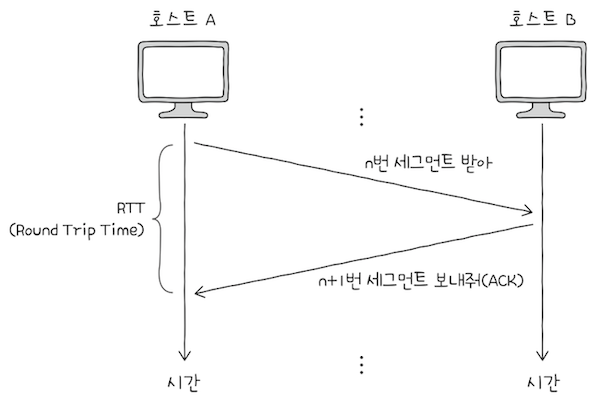
💡RTT
메시지를 전송한 뒤, 그에 대한 답변을 받는 데까지 걸리는 시간을
RTT(Round Trip Time)이라 한다.RTT는 ping 명령어로 쉽게 조회할 수 있다.
- e.g. 리눅스/맥OS 운영체제에서
www.google.com으로 5개의 패킷을 전송하는 ping 명령인데,- 가장 마지막 줄에 최소/평균/최대/표준편차(standard deviation)가 출력된다.
1$ ping -c 5 www.google.com2PING www.google.com (172.217.161.228): 56 data bytes364 bytes from 172.217.161.228: icmp_seq=0 ttl=55 time=37.031 ms464 bytes from 172.217.161.228: icmp_seq=1 ttl=55 time=41.520 ms564 bytes from 172.217.161.228: icmp_seq=2 ttl=55 time=36.058 ms664 bytes from 172.217.161.228: icmp_seq=3 ttl=55 time=43.583 ms764 bytes from 172.217.161.228: icmp_seq=4 ttl=55 time=42.298 ms89--- www.google.com ping statistics ---105 packets transmitted, 5 received, 0% packet loss, time 4007ms11rtt min/avg/max/mdex = 58.777/59.187/59.435/0.243 ms
(2) 타임아웃이 발생했을 떄
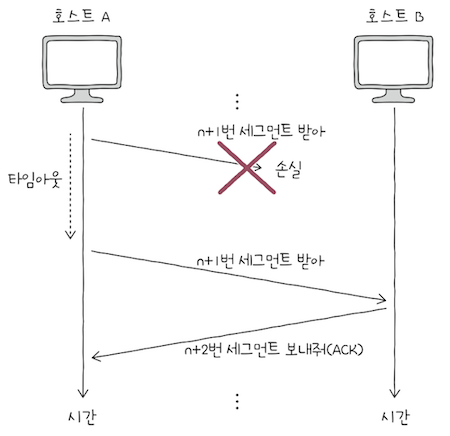
TCP는 타임아웃이 발생하면 문제가 생겼음을 인지한다.
TCP 세그먼트를 송신하는 호스트는 모두재전송 타이머(retransmission timer)라는 값을 유지한다.호스트가세그먼트를 전송할 떄마다재전송 타이머를 시작하는데,- 이
타이머의 카운트다운이 끝난 상황(정해진 시간이 끝난 상황)을타임아웃(timeout)이라고 한다.
- 이
타임아웃이 발생할 떄까지ACK 세그먼트를 받지 못하면,세그먼트가상대 호스트에게 정상적으로 도착하지 않았다고 간주하여,세그먼트를 재전송한다.
3.1.2 ARQ : 재전송 기법
어떤 상황에서 세그먼트를 재전송해야 하는지를 알았다면, 이제 TCP의 재전송 기법을 알아보자.
수신 호스트의 답변(ACK)과타임아웃 발생을 토대로 문제를 진단하고, 문제가 생긴 메시지를 재전송함으로써,- 신뢰성을 확보하는 방식을
ARQ(Automatic Repeat Request; 자동 재전송 요구)라고 한다.
- 신뢰성을 확보하는 방식을
ARQ의 종류는 다양한데, 대표적으로 3가지 방식이 있다.- Stop-and-Wait ARQ
- Go-Back-N ARQ
- Selective Repeat ARQ
- cf. 전송 계층의 TCP는 ARQ를 사용하는 대표적인 프로토콜이지만, ARQ 자체는 전송 계층만의 기술이 아니다.
3.1.3 Stop-and-Wait ARQ
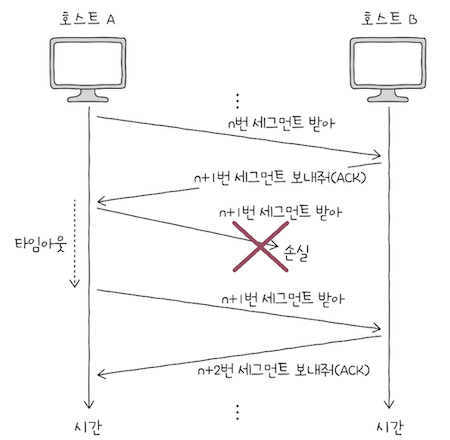
ARQ 중 가장 단순항 방식으로, 제대로 전달했음을 확인하기 전까지는 새 매세지를 보내지 않는 방식이다.
- 즉, 메시지를 송신하고, 이에 대한 확인 응답을 받고, 다시 메시지를 전송하고,
- 이에 대한 확인 응답을 받는 것을 반복한다.
- 이는 단순하지만, 높은 신뢰성을 보장하는 방식이다.
- cf. 오늘날 인터넷 환경의 TCP에서는 특별한 경우가 아닌 이상 Stop-and-Wait ARQ를 잘 사용하지 않지만,
- 뒤에 이어지는 흐름 제어에서 다시 한번 살펴본다.
- 하지만 이 방식에는 문제가 있는데, 바로 네트워크의 이용 효율이 낮아질 수 있다.
- 전송되었음을 확인해야만 비로소 다음 전송을 시작하는
Stop-and-Wait ARQ의 특성상, 송신 호스트(A)입장에서 확인 응답을 받기 전까지는 다음 전송을 할 수 있어도 하지 못한다.수신 호스트(B)입장에서도 훨씬 더 많은 데이터를 한 번에 전송받을 수 있음에도 불구하고,- 한 번에 하나씩만 확인 응답을 해야 한다.
- 전송되었음을 확인해야만 비로소 다음 전송을 시작하는
- 결과적으로 네트워크 이용효율이 낮아지고, 이는 성능의 저하로 이어질 수 있다.
3.1.4 Go-Back-N ARQ
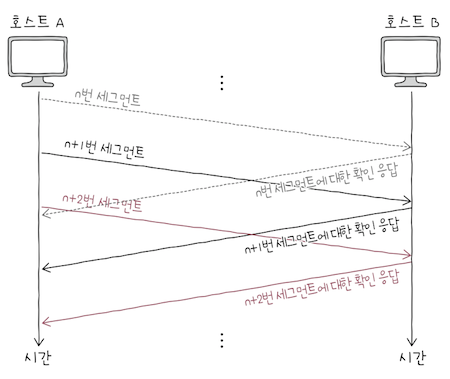
Stop-and-Wait ARQ의 문제를 해결하려면, 위 그림처럼 각 세그먼트에 대한 ACK 세그먼트가 도착하기 전이더라도,
여러 세그먼트를 보낼 수 있어야 한다.
Go-Back-N ARQ와 바로 뒤의 Selective Repeat ARQ는 모두 이런 방식으로 동작한다.
- 이렇게 연속해서 메시지를 전송할 수 있는 기술을
파이프라이닝(pipelining)이라 한다. - 오늘날 TCP는 파이프라이닝이 사용되는
Go-Back-N ARQ와Selective Repeat ARQ를 기반으로 동작한다.
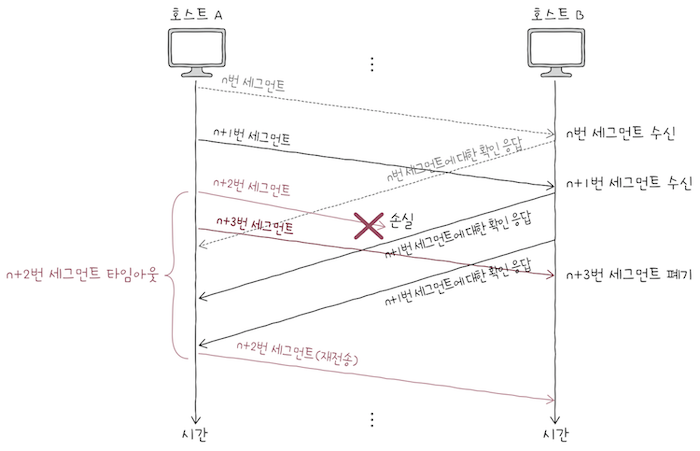
Go-Back-N ARQ는 파이프라이닝 방식을 활용해 여러 세그먼트를 전송하고,
- 도중에 잘못 전송된 세그먼트가 발생할 경우, 해당 세그먼트로부터 전부 다시 전송하는 방식이다.
- 위 그림을 보면,
송신 호스트는 여러 세그먼트를 보내고,수신 호스트는 (세그먼트를 정상 수신했다면) 그에 대한 ACK 세그먼트를 보낸다.
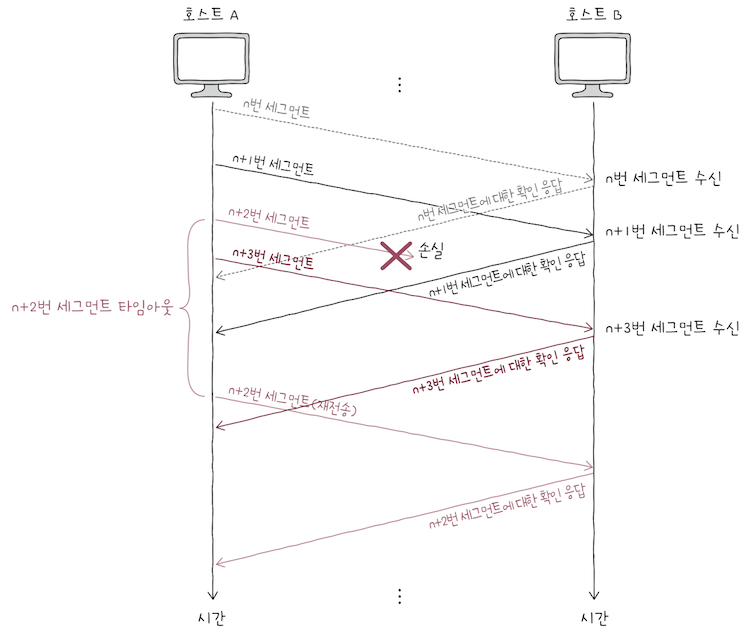
- 이떄
송신 호스트의순서 번호 n+2번 세그먼트가 전송 과정에서 유실되었다면,수신 호스트는 그 외 모든 세그먼트를 올바르게 수신했다 해도 이를 폐기한다.
송신 호스트입장에서n+2번 세그먼트에 대한ACK 세그먼트를 받지 못했기에타임아웃이 발생하고,- 이를 통해
송신 호스트는 잘못된 송신이 있음을 인지한다. - 따라서
ACK 세그먼트를 수신받지 못한n+2번 세그먼트부터 다시 전송하게 된다.
- 이를 통해
이런 점에서 볼 떄, Go-Back-N ARQ에서 순서 번호 n번에 대한 ACK 세그먼트는 ‘n번만의’ 확인 응답이 아니라,
‘n번까지의’ 확인 응답이라고 볼 수 있다.
이런 점에서 Go-Back-N ARQ의 ACK 세그먼트를 누적 확인 응답(CACK; Cumulative Acknowledgment)라고 한다.
💡 빠른 재전송(fast retransmit)
빠른 재전송은 재전송 타이머가 만료되기 전이라도 3번의 동일한 ACK 세그먼트가 수신되었다면,
- 해당 세그먼트를 곧바로 재전송하는 기능이다.
e.g.
1, 2, 3, 4, 5번 세그먼트를 전송하는 과정에서3번 세그먼트가 누락되었다고 가정해보면,
Go-Back-N ARQ방식에 따라수신 호스트는 (4, 5번 세그먼트를 받았더라도)3번 세그먼트에 대한ACK 세그먼트를송신 호스트에 전송한다.- 그리고
송신 호스트는3번 세그먼트에 대한 재전송 타이머가 만료되었을 떄,3번 세그먼트를 재전송한다.3번 세그먼트에 대한 재전송 타이머가 만료되기 전이라면,3번 세그먼트가 손실되었다고 판단하지 않는다.- 하지만,
빠른 재전송은재전송 타이머가 만료되지 않았더라도,
- 3번의 동일한
ACK 세그먼트가 수신되면, 곧바로 재전송을 수행하기에,- 타이머가 끝날 떄까지 기다리는 시간을 줄일 수 있다.
즉,
빠른 재전송은 시간 낭비를 줄이며빠르게(fast)손실된 세그먼트를재전송(retransmit)함으로써 성능을 높이는 기능이다.
3.1.5 Selective Repeat ARQ
Selective Repaet ARQ는 이름 그대로 선택적으로 재전송하는 방법이다.
Go-Back-N ARQ송신 과정은 한 세그먼트에만 문제가 발생해도, 그 후의 모든 세그먼트를 다시 재전송해야 한다는 단점이 있다.- 반대로,
Selective Repaet ARQ는 수신 호스트 측에서 제대로 전송받은 각각의 패킷들에 대해 ACK 세그먼트를 보내는 방식이다. Go-Back-N ARQ의 ACK 세그먼트가누적 확인 응답이라면,Selective Repeat ARQ의 ACK 세그먼트는개별 확인 응답(Selective Acknowledgment)인 셈이다.송신 호스트는 올바르게 수신받지 못한ACK 세그먼트가 있는지 검사하고,- 만일
응답받지 못한 세그먼트가 존재한다면, 해당세그먼트를 재전송한다.
- 만일
오늘날 대부분의 호스트는 TCP 통신에서 Selective Repeat ARQ를 지원한다.
- 두 호스트가 연결을 수립할 떄, 서로의 Selective Repeat ARQ 지원 여부를 확인하는데,
- 만약
Selective Repeat ARQ를 사용하지 않을 경우,Go-Back-N ARQ방식으로 동작한다. - cf.
Selective Repeat ARQ 지원 여부는TCP 세그먼트 헤더의 옵션 필드에 속한SACK 허용(SACK-permitted) 필드를 통해 알 수 있다.SACK는 선택 승인(Selective Acknowledgment)의 약자다.
3.2 흐름 제어: 슬라이딩 윈도우
TCP의 2번쨰 핵심 기능인 흐름 제어(flow control)를 알아보자.
파이프라이닝 기반의 Go-Back-N ARQ와 Selective Repeat ARQ가 정상 동작하려면,- 반드시
흐름 제어를 고려해야 한다.
- 반드시
- 호스트가 한 번에 받아서 처리할 수 있는 세그먼트의 양에는 한계가 있기 때문이다.
e.g. 수신 호스트가 한 번에 n개의 바이트를 받아서 처리할 수 있다면,
송신 호스트는 이 점을 인지하여 n개 바이트를 넘지 않는 선에서 송신해야 한다.- 만약 이 양보다 더 많은 양을 한 번에 전송하면 마치 운편함에 가득 차 일부 편지가 넘치는 것처럼,
- 일부 세그먼트가 처리되지 못한다.
이 상황은 수신 호스트의 수신 버퍼와 버퍼 오버플로라는 개념을 통해 더 명확히 이해할 수 있다.
수신 버퍼: 수신된 세그먼트가 앱 프로세스에 의해 읽히기 전에 임시로 저장되는 공간버퍼 오버플로(buffer overflow): 버퍼(buffer)가 넘치는(overflow) 문제 상황을 의미- 송신 호스트가 흐름 제어를 고려하지 않고, 수신 버퍼의 크기보다 많은 데이터를 전송하면,
- 저장 가능한 공간보다 더 많은 데이터를 저장하지는 못하기 때문에
- 일부 세그먼트가 처리되지 못한다.
cf. 수신된 세그먼트가 저장되는
수신 버퍼외에도, 송신할 세그먼트가 저장되는송신 버퍼도 있다.
TCP의 흐름 제어란 이런 문제 상황(버퍼 오버플로)을 방지하기 위해,
송신 호스트가수신 호스트의 처리 속도를 고려하며, 송수신 속도를 균일하게 유지하는 것을 의미한다.
그러면, 어떻게 송수신 속도를 균일하게 유지할까?
- 사실
Stop-and-Wait ARQ를 사용하면 별도의 흐름 제어가 필요하지 않다.- 확인 응답이 오기 전까지는 추가적인 세그먼트를 전송하지 않는 방식이기 때문이다.
- 하지만 실제 TCP를 동작시키는 파이프라이닝 기반
Go-Back-N ARQ와Selective Repeat ARQ에는흐름 제어가 필요하다.파이프라이닝이 연속해서 세그먼트를 전송할 수 있는 기술이라고는 하지만,- 무작정 무한한 데이터를 연속해서 보낼 수는 없기 때문이다.
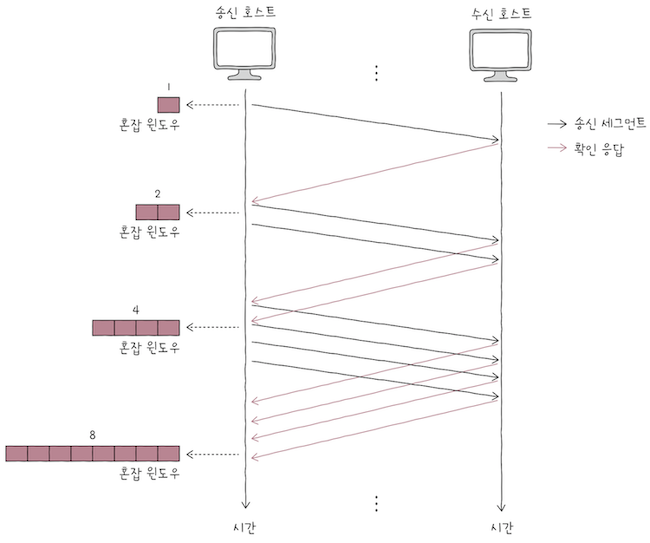
오늘날 TCP에서는 흐름 제어로 슬라이딩 윈도우(sliding window)를 사용한다.
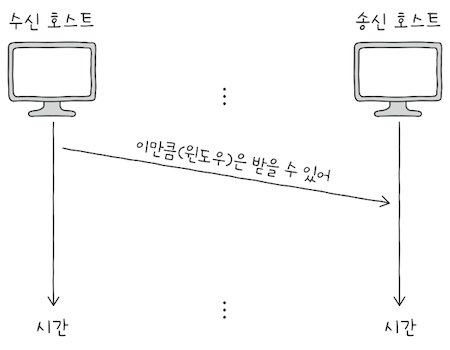
슬라이딩 윈도우이해하려면윈도우(window)가 무엇인지 이해해야 한다.윈도우란 송신 호스트가 파이프라이닝할 수 있는 최대량을 의미한다.- 윈도우의 크기만큼 확인 응답을 받지 않고도, 한 번에 전송가능하다는 의미다.
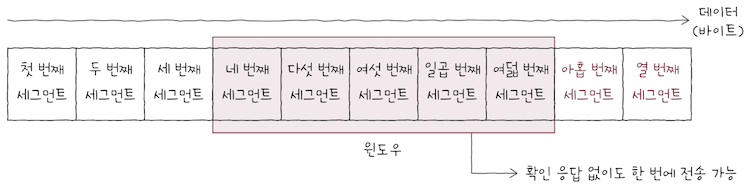
e.g. 종이에 전송하려는 데이터를 가로로 나란지 적어두고, 반투명한 종이를 그 위에 덧댄다고 가정해보자.
- 반투명된 종이에 포함된 데이터 범위가 바로 윈도우다.
- 반투명 종이 크기가 크면 윈도우 크기가 크므로, 한 번에 전송할 수 있는 데이터가 많고,
- 반투명 종이 크기가 작으면 우니도우 크기가 작으므로, 한 번에 전송할 수 있는 데이터가 적다.
e.g. 송신 호스트가 보내려는 데이터와 윈도우가 위 그림과 같다면,
1번 세그먼트부터4번 세그먼트까지 확인 응답을 받지 않고도 전송할 수 있는 양이다.- 반면에, 윈도우 크기에서 벗어난 숫자에 해당하는 세그먼트는 전송할 수 없다.
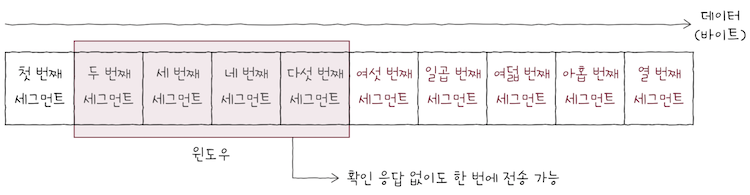
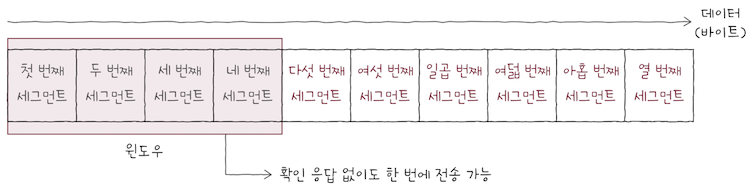
위 상황에 이어 윈도우에 포함된 1, 2, 3, 4번 세그먼트를 전송했고,
- 곧
수신 호스트로부터1번 세그먼트에 대한ACK 세그먼트를 받았다고 가정해보자. - 그렇다면
윈도우는 위 그림처럼 오른쪽으로 1칸 이동한다.
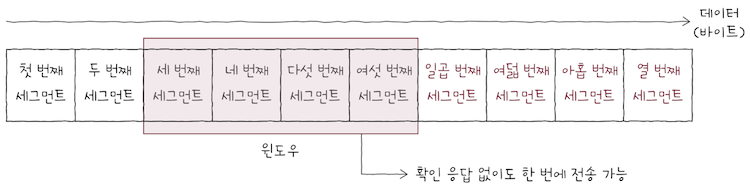
2번쨰 세그먼트에 대한 ACK 세그먼트를 받았다면, 윈도우는 또 다시 오른쪽으로 1칸 이동한다. 마치 윈도우가 점차 오른쪽으로 미끄러지듯이 움직이죠?
송신 호스트만 윈도우를 고려하는 것은 아니다. 수신 호스트도 윈도우를 고려한다.
- 사실,
송신측 윈도우(이하 송신 윈도우)는 수신 호스트가 알려주는수신 측 윈도우(이하 수신 윈도우)를 토대로 알 수 있는 정보다.
2.1 TCP 세그먼트 구조를 학습했을 떄, TCP 세그먼트 내에 윈도우라는 필드가 있었다.
윈도우 필드에는수신 윈도우의 크기가 명시되고, 이는 한 번에 수신하는 데이터의 양을 나타낸다.수신 호스트의수신 윈도우 크기를송신 호스트도 알아야겠죠?수신 호스트가 한 번에 수신하고자 하는 데이터의 양만큼만 전송해야 한다.
- 그렇기에
수신 호스트는TCP 헤더(윈도우 필드)를 통해,송신 호스트에게 자신이 받아들이고자 하는 데이터의 양을 알리게 된다.송신 호스트는 이 정보를 바탕으로수신 호스트의 처리 속도와 발맞춰 균일한 속도로 세그먼트를 전송한다.
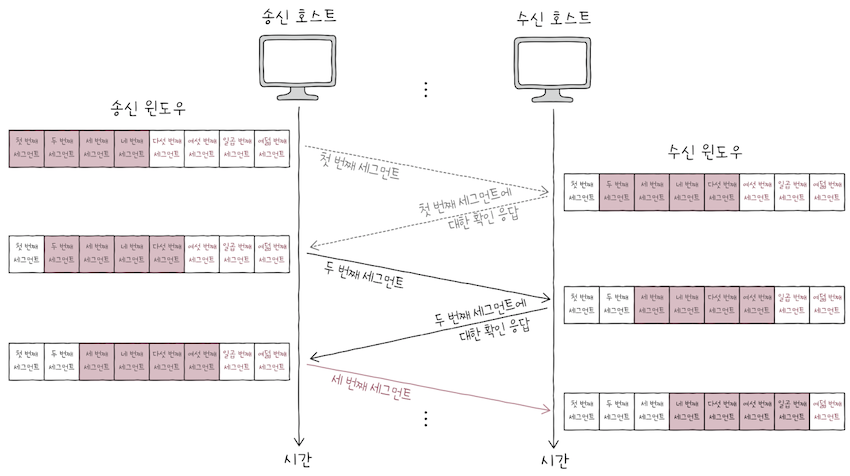
수신 호스트가 1번 세그먼트를 올바르게 수신했다면(송신 윈도우와 마찬가지로), 수신 윈도우는 오른쪽으로 1칸 이동한다.
- 또 2번 세그먼트를 올바르게 수신했다면,
수신 윈도우는 다시 한번 오른쪽으로 1칸 이동한다. - 이렇듯 파이프라이닝 과정에서
송수신 윈도우는 점차 오른쪽으로 미끄러지듯 움직인다. - ‘미끄러지다’를 영어로 표현하면
슬라이드이다. - 그래서 이런 TCP의 흐름 제어를
슬라이딩 윈도우(sliding window)라고 부른다.
3.3 혼잡 제어
사람이 많은 곳에서 네트워크를 이용할 떄 속도가 느려지는 것을 경험해봤을 것입니다.
혼잡(congestion)은 많은 트래픽으로 인해 패킷의 처리속도가 늦거나, 유실될 수 있는 네트워크 상황을 의미한다.
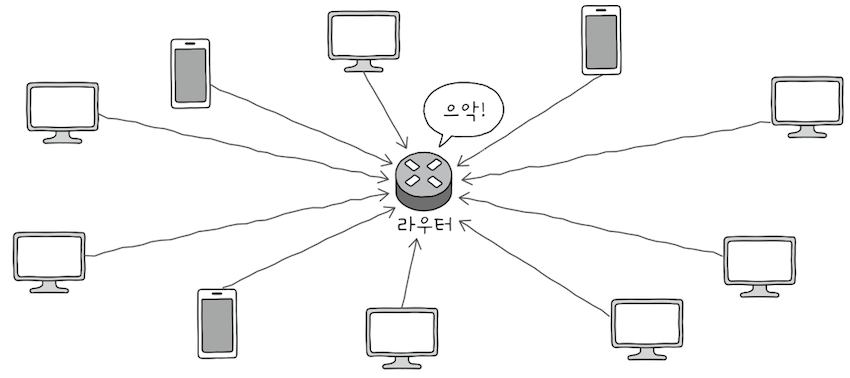
e.g. 같은 네트워크에 속한 여러 호스트가 1대의 라우터에 연결되어 있다고 가정해보면,
모든 호스트가라우터에게 전송 가능한 최대의 양으로 세그먼트를 전송하면,라우터에 과부하가 생겨 모든 정보를 한 번에 처리하지 못할 수 있다.
- 그러면
호스트들은 앞서 학습한 대로 오류를 검출하여 재전송을 하게 되고,- 그럴수록
라우터는 더 많은 세그먼트를 받게 되어혼잡 현상이 점점 악화된다. - TCP 개발 초기에는 이런
혼잡 현상에 따른 전송률 저하가 큰 골칫거리였다.
- 그럴수록
혼잡으로 인해 전송률이 크게 떨어지는 현상을
혼잡 붕괴(congestion collapse)라고 한다.
TCP의 혼잡 제어(congestion control)란 이와 같은 혼잡을 제어하기 위한 기능이다.
흐름 제어의 주체가수신 호스트라면,혼잡 제어의 주체는송신 호스트다.혼잡 제어를 수행하는송신 호스트는 네트워크 혼잡도를 판단하고,- 혼잡한 정도에 맞춰 유동적으로 전송량을 조절하며 전송한다.
혼잡 제어를 이해하려면 먼저 혼잡 윈도우를 알아야 한다.
혼잡 윈도우(congestion window)는 혼잡없이 전송할 수 있을 법한 데이터 양을 의미한다.- 쉽게 말하면, ‘이 정도 양을 송신하면, 혼잡없이 전송할 수 있겠지?’에서 ‘이 정도’에 해당하는 양이다.
혼잡 윈도우가 크면, 한 번에 전송할 수 있는 세그먼트 수가 많음을 의미하고,혼잡 윈도우가 작다면, 네트워크가 혼잡한 상황이기에 한 번에 전송할 수 있는 세그먼트 수가 적음을 의미한다.
세그먼트를 송신하는 호스트 입장에서 생각해보면,
수신 윈도우크기는수신 호스트가TCP 헤더로 알려주기에 별도로 고민할 필요가 없지만,혼잡 윈도우의 크기는송신 호스트가 어느 정도의 세그먼트를 전송해야,- 혼잡을 방지할 수 있는지를 직접 계산해서 알아내야 한다.
💡 cf.
수신 윈도우는 수신 호스트가 송신 호스트에게 알려줘야할 정보이므로,
- 송수신 호스트가 주고받는 TCP 헤더에 명시되어 있지만,
혼잡 윈도우는 송신지가 자체 계산하여 유지할 정보이기에, 헤더에 포함할 필요가 없다.
그렇다면 혼잡 윈도우 크기는 어느 정도가 적당할까?
- 이는
혼잡 제어 알고리즘을 통해 결정할 수 있다. - 혼잡 제어를 수행하는 일련의 방법을
혼잡 제어 알고리즘(congestion control algorithm)이라 부른다.
우선 가장 기본적인 알고리즘인 AIMD(Additive Increase/Multiplicative Decrease)를 알아보자.
- 해석하면, ‘합으로 증가, 곱으로 감소’라는 의미다.
- 혼잡이 감지하지 않는다면,
혼잡 윈도우를RTT(Round Trip Time)마다 1씩 선형적으로 증가하고,- 혼잡이 감지되면,
혼잡 윈도우를 절반으로 떨어뜨리는 동작을 반복하는 알고리즘이다.
- 혼잡이 감지되면,
- 그래서
혼잡 윈도우는 톱니 모양으로 변화한다는 특징이 있다.

AMID 알고리즘은 혼잡을 제어할 수 있는 기본적인 아이디어지만, 이것만으로 혼잡 제어가 이루어지지 않는다. 이를 조금 더 정교하게 만들 혼잡 제어 알고리즘들이 있다.
- 느린 시작
- 혼잡 회피
- 빠른 회복
3.3.1 느린 시작 알고리즘
느린 시작(slow start) 알고리즘은 혼잡 윈도우를 1부터 시작해,
- 문제없이
수신된 ACK 세그먼트하나당 1씩 증가시키는 방식이다. - 위 그림을 보면, 결과적으로
혼잡 윈도우는 RTT마다 2배씩 지수적으로 증가하게 된다. AIMD 방식은 처음 연결이 수립된 뒤, 혼잡 윈도우 크기가 증가하는 속도가 느리다.- 선형적으로
혼잡 윈도우를 증가시키므로, 초기 전송 속도가 확보되지 않는다. - 하지만
느린 시작을 이용하면,혼잡 윈도우의 지수적인 증가를 활용해, 초기 전송 속도를 어느정도 빠르게 확보할 수 있다.
하지만 혼잡 윈도우를 언제까지나 지수적으로 증가시킬 수는 없다.
혼잡 윈도우가 계속 지수적으로 증가하면, 언젠가는혼잡 상황을 마주할 확률이 높아지기 때문이다.- 그렇다면 언제까지 증가할까?
느린 시작 알고리즘을 사용할 떄,- 함께 사용하는 값으로
느린 시작 임계치(slow start threshold)라는 값이 정해져 있다.
- 함께 사용하는 값으로
혼잡 윈도우 값이 계속 증가하다가 느린 시작 임계치 이상이 되거나,- 타임아웃이 발생하거나,
- 3번의 중복된 ACK 세그먼트가 발생해서 혼잡이 감지되면,
- 다음 3가지 방법 중 하나를 선택한다.
| 상황 분류 | 방법 |
|---|---|
| 타임아웃 발생 | 혼잡 윈도우 값을 1로 느린 시작 임계치를 혼잡이 감지되었을 시점의 혼잡 윈도우 값의 절반으로 초기화한 뒤 느린 시작 재개 |
| 혼잡 윈도우 >= 느린 시작 임계치 | 느린 시작 종료, 혼잡 윈동루를 절반으로 초기화한 뒤 혼잡 회피 수행 |
| 3번의 중복된 ACK 발생 | (빠른 재전송 후) 빠른 회복 수행 |
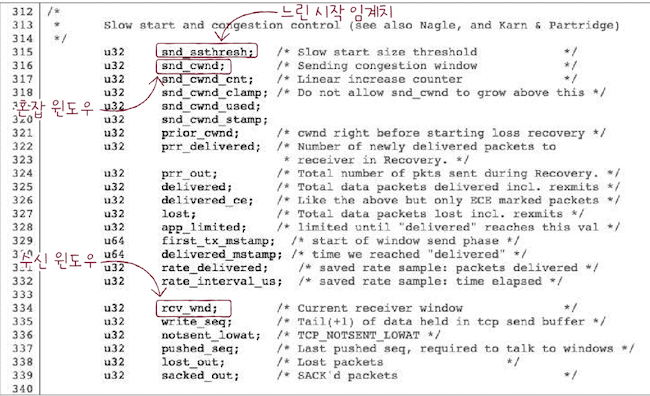
💡 수신 윈도우, 혼잡 윈도우
이번 절에서
수신 윈도우,혼잡 윈도우,느린 시작 임계치를 배웠다.
- 이들은 각각
RWND(Receiver WINDow),
CWND(Congestion WINDow),SSTHRESH(Slow Start THRESHold)라 줄여서 부른다.- 그리고 이 값들은 일반적으로 운영체제에서 TCP의 상태를 관리하는 상태 변수의 형태로 존재한다.
- 위 그림은 리눅스 운영체제의 소스코드 일부이다.
- cf. https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/tcp.h#n395
3.3.2 혼잡 회피 알고리즘
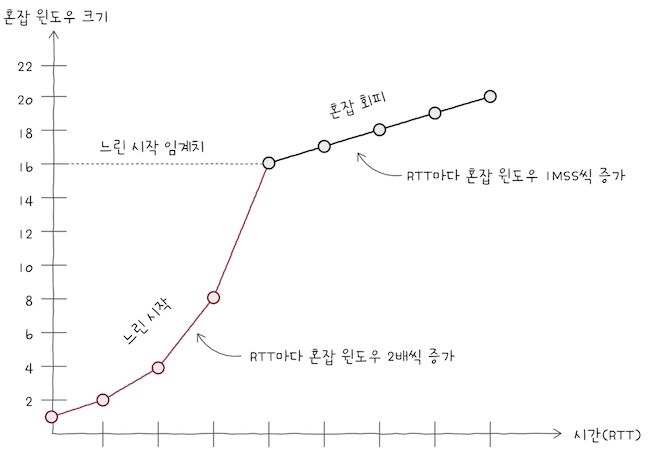
혼잡 회피(congestion avoidance) 알고리즘은 RTT마다 혼잡 윈도우를 IMSS(Maximum Segment Size)씩 증가시키는 알고리즘이다.
- 위 그래프를 보면,
혼잡 윈도우를 지수적으로 증가시키는느린 시작과 달리,혼잡 윈도우 크기를 선형적으로 증가시키는 것을 볼 수 있다.
- 느린 시작 임계치를 넘어선 시점부터는 혼잡이 발생할 우려가 있으니 조심해서 혼잡 윈도우를 증가시키는 방식이다.
이떄, 혼잡 회피 도중에 타임아웃이 발생하면 혼잡 윈도우 값은 1로,
느린 시작 임계치는 혼잡이 감지된 시점의혼잡 윈도우값의 절반으로 초기화한 뒤 다시느린 시작을 수행한다.- 그리고
혼잡 회피도중3번의 중복 ACK세그먼트가 발생되었을 떄는혼잡 윈도우값과느린 시작 임계치를 대략 절반으로 떨어뜨린 뒤,빠른 회복 알고리즘을 수행한다.
- 물론 이떄
타임아웃이 발생한 세그먼트나3번의 중복 ACK세그먼트가 발생한 세그먼트는 재전송한다.
3.3.3 빠른 회복 알고리즘
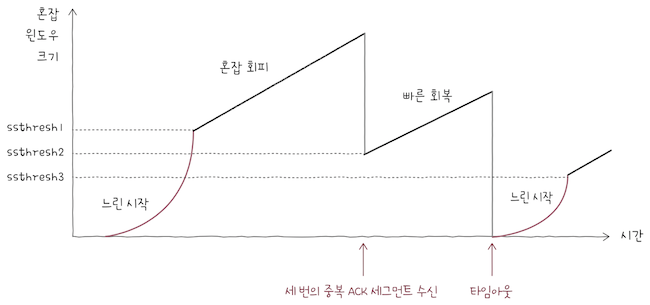
3번의 중복된 ACK 세그먼트를 수신하면, 빠른 재전송과 더불어 빠른 회복 알고리즘이 수행된다.
빠른 회복 알고리즘은3번의 중복 ACK세그먼트를 수신했을 떄,느린 시작은 건너뛰고,혼잡 회피를 수행하는 알고리즘으로,- 이름처럼 빠르게 전송률을 회복하기 위한 알고리즘이다.
- 단,
빠른 회복도중이라도타임아웃이 발생하면,혼잡 윈도우크기는 1로,느린 시작 임계치는 혼잡이 감지된 시점의 절반으로 떨어뜨린 후, 다시느린 시작을 수행한다.
💡 cf.
중복된 ACK 세그먼트가 수신되면빠른 회복과 함께 빠른 재전송이 수행된다는 점에서
빠른 재전송과빠른 회복을 함께 묶어,혼잡 제어방식의 일종으로 보기도 한다.
3.4 ECN: 명시적 혼잡 알림
앞서 학습한 혼잡 제어 알고리즘에 따르면,
혼잡을 제어하기 위해 어느 정도의 양을 송신할지 결정하는 것은 오로지송신 호스트의 몫이다.송신 호스트가 나름대로혼잡 윈도우를 계산하여 세그먼트를 송신하고,- 그 과정에서 올바르게 전송되지 않은 것이 있다면, 그때 비로소
혼잡 윈도우를 조정하는 식으로 혼잡을 제어한다.
- 그 과정에서 올바르게 전송되지 않은 것이 있다면, 그때 비로소
- 하지만, 최근 혼잡을 회피하기 위해 네트워크 중간 장치(주로 라우터)의 도움을 받는 방법이 생겼는데,
- 이를
명시적 혼잡 알림(ECN; Explicit Congestion Notification)이라 한다.
- 이를

ECN은 선택적인 기능이기에 이를 지원하는 호스트가 있고, 지원하지 않는 호스트가 있다.
ECN을 지원하는 호스트가TCP/IP 프로토콜로 정보를 주고받을 떄,IP 헤더와TCP 헤더에ECN 관련 필드가 추가된다.
IP(IPv4) 헤더에는서비스 필드내 오른쪽 두 비트가ECN으로 사용되고,TCP 헤더에서는 위 그림처럼 제어 비트의CWR 비트,ECE 비트가ECN으로 사용된다.
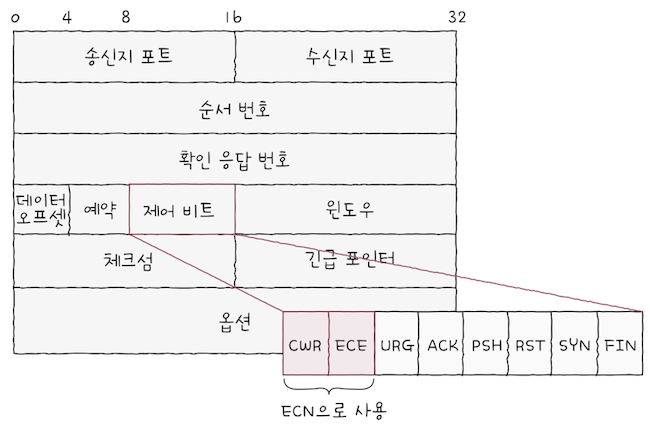
💡 ECN은 선택 기능이고, 통신을 주고받는 양쪽 호스트가 ECN 기능을 지원해야 한다.
- 이에 연결 수립 과정에서 양쪽 호스트는 앞의 비트들을 활용해 ECN 지원 여부를 확인하게 된다.
- ECN 지원 여부 확인 방법은 여기서 다루기에는 긴 내용이라 생략한다.
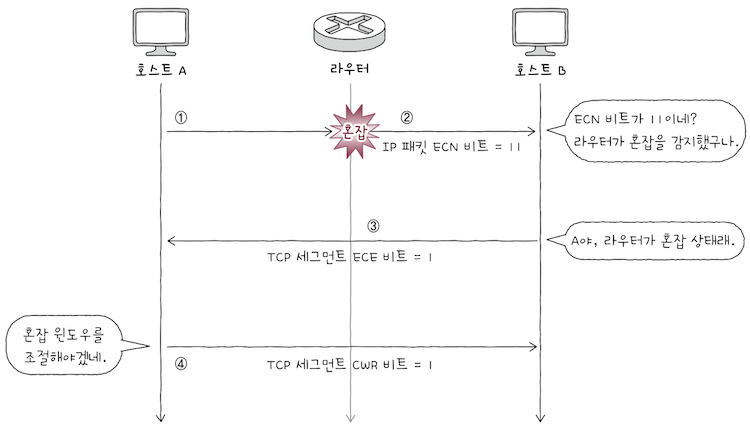
ECN을 통한 혼잡 제어의 대략적인 동작은 위 그림과 같다.
ECN을 이용한혼잡 회피는 라우터를 기준으로 시작된다.
e.g. 호스트 A와 호스트 B 사이에 라우터가 가정해보면,
호스트 A가 호스트 B에게 메시지를 전송하기 위해 라우터에게 메시지를 보낸다.- 라우터 입장에서 네트워크가 혼잡해질 것 같다고 판단할 경우,
IP 헤더의ECN 비트들을 설정한 채,수신지 호스트 B에게 전달한다.IPv4 헤더의ECN 비트가 11로 설정될 경우, 이는혼잡을 감지했음(Congestion Experienced)을 의미한다.
호스트 B가 전달받은 IP 패킷 내에 혼잡 표시가 되어 있다면,TCP ACK 세그먼트내ECE 비트세팅을 통해송신 호스트에게 네트워크가 혼잡함을 알려준다.
송신 호스트가 응답받은 세그먼트에서ECE 비트가 설정되어 있을 경우,송신 호스트는CWR 비트를 세팅 후혼잡 윈도우를 반으로 줄인다.
ECN을 이용하지 않고, 송신 호스트만 혼잡 제어를 수행할 경우,
타임아웃, 중복된 ACK 세그먼트 수신과 같이 문제가 발생한 이후에야혼잡 제어가 수행된다.- 하지만
ECN을 이용하면수신 호스트의 ACK 세그먼트를 통해 더 빠르게혼잡을 감지할 수 있고, - 이는 일반적으로
3번의 중복된 ACK 세그먼트수신 이후나타임아웃 발생후에 혼잡을 제어하는 방식에 비해 더 빠르다.